Зміст
Вступ................................................................................................................ 2
Вихідні дані..................................................................................................... 3
Розділ 1. Предмет, завдання і система показників ефективності сільськогосподарського виробництва............................................................ 4
1.1 Предмет і завдання статистики виробництва льоноволокна................... 4
1.2 Система показників статистики виробництва льоноволокна.................. 4
Розділ 2. Статистична оцінка показників виробництва льоноволокна...... 13
2.1 Ряди розподілу вибіркової сукупності, їх характеристика, графічне зображення......................................................................................................................... 13
2.2 Статистична оцінка показників вибіркової і генеральної сукупності... 24
2.3 Перевірка статистичної гіпотези про відповідність емпіричного ряду розподілу нормальному................................................................................................. 32
Розділ 3. Кореляційний аналіз виробництва льоноволокна....................... 37
3.1 Проста прямолінійна кореляція............................................................. 39
3.2 Криволінійна кореляція.......................................................................... 44
3.3 Множинна кореляція............................................................................... 45
3.4 Непараметрична кореляція..................................................................... 51
Висновки........................................................................................................ 56
Література..................................................................................................... 57
Вступ
Широке розповсюдження в економічному аналізі мають методи математичної статистики. Ці методи застосовуються в тих випадках, коли зміну аналізованих показників можна представити як випадковий процес. Статистичні методи, будучи основним засобом вивчення масових явищ, що повторюються, грають важливу роль в прогнозуванні поведінки економічних показників. Коли зв'язок між аналізованими характеристиками не детермінований, а стохастичний, то статистичні і імовірнісні методи - це практично єдиний інструмент дослідження. Найбільше розповсюдження з математико-статистических методів в економічному аналізі отримали методи множинного і парного кореляційного аналізу.
Для вивчення одновимірних статистичних совокупностей використовуються: варіаційний ряд, закони розподілу, вибірковий метод. Для вивчення багатовимірних статистичних совокупностей застосовують кореляції, регресії, дисперсійний, коваріационний, спектральний, компонентний, факторний види аналізу, статистики, що вивчаються в курсах теорії.
Економетрічеськие методи будуються на синтезі трьох галузей знань: економіки, математики і статистики. Основою економетрії є економічна модель, під якою розуміється схематичне представлення економічного явища або процесу за допомогою наукової абстракції, віддзеркалення їх характерних рис.
Метою даної курсової роботи є статистичне дослідження даних, які характеризують виробництво льнас метою виявлення взаємозв'язку між досліджуваними показниками.
Вихідні дані
| Урожайність льоноволокна, ц/га |
Якість льонотрести, номер |
Витрати праці на 1 центнер трести, люд/год |
| 7,8 |
0,85 |
6,9 |
| 6,6 |
0,5 |
3,33 |
| 10,7 |
1,23 |
3,97 |
| 11,8 |
0,77 |
3,24 |
| 5,9 |
0,56 |
6,67 |
| 3,7 |
0,6 |
1,43 |
| 9,8 |
0,54 |
2,66 |
| 5,6 |
0,58 |
3,59 |
| 8,7 |
0,65 |
3,28 |
| 5,1 |
0,63 |
7,85 |
| 7,2 |
0,7 |
5,75 |
| 3,7 |
0,64 |
3,94 |
| 6 |
0,72 |
6,63 |
| 5,7 |
0,5 |
4,74 |
| 9,8 |
0,97 |
4,05 |
| 7,5 |
0,88 |
7,25 |
| 5,2 |
0,65 |
5,52 |
| 4,3 |
0,5 |
2,33 |
| 7,6 |
0,6 |
5,4 |
| 6,3 |
0,78 |
2,32 |
| 10,9 |
0,72 |
6,68 |
| 12,1 |
0,88 |
10,38 |
| 13,1 |
1,37 |
3,81 |
| 3,7 |
0,56 |
4,51 |
| 13,4 |
1,46 |
3,23 |
Розділ 1. Предмет, завдання і система показників ефективності сільськогосподарського виробництва
Величезне значення в народному господарстві України має така культура як льон.
Льон є одним з найголовніших сировинних ресурсів текстильної промисловості. Велике застосування отримало використання цієї культури і в медичних цілях, особливо цінним є насіння льону.
Основні завдання статистики виробництва льону - збір, обробка і аналіз статистичних даних, що характеризують стан, розвиток галузі і виконання виробничих планів. Ці дані використовуються для складання річних і перспективних планів виробництва льону . Інформаційними джерелами статистики виробництва льону служать: періодична звітність і річні звіти колгоспів, радгоспів і ін. державних і кооперативних з.-х. підприємств, засновані на даних первинного бухгалтерського і виробничого обліку в цих господарствах; переписи; вибіркові обстеження. У статистиці виробництва льону застосовується наступна система основних показників: розмір земельної площі і угідь, склад і розподіл їх по землекористувачах; посівні площі і сортові посіви; валові збори і врожайність культури; чисельність і використання робочої сили, оплата праці, продуктивність праці; розміри основних фондів, їх структура, фондовооруженность і енергоозброєність праці, собівартість продукції, рентабельність виробництва окремих продуктів і всього господарства і ін.
Для обліку і планування вироблюваної промислової продукції застосовуються натуральні, умовно-натуральні і вартісні показники. Вказані показники широко застосовуються в статистичній звітності підприємств за підсумками своєї діяльності.
Натуральні показники продукції виражаються в певних натуральних одиницях, об'єднуючих певними фізичними властивостями, вимірювані вагою, об'ємом, завдовжки відповідними мірами ваги, об'єм, довжина і тому подібне (кг, т., кубометри, метри, кілометри і так далі).
Облік продукції в натуральному виразі не може дати повного уявлення про величину проведеної продукції. У натуральних показниках неможливо визначити в одному показнику підсумкову величину виробництва за наявності багатообразного асортименту проведеної продукції, не можна також виразити і величину незавершеного виробництва.
Умовно-натуральні показники близько стоять до натуральних показників з тією тільки різницею, що різні види продуктів, виробів виражаються в одиницях одного певного продукту за допомогою перекладних коефіцієнтів. Ці коефіцієнти можуть бути побудовані або на основі споживчого значення продукту, або на основі трудомісткості, або на основі витрат на виробництво і так далі
Умовно-натуральному методу обліку продукції властиві недоліки натурального методу. Умовно-натуральні показники використовуються для отримання узагальнювальних показників об'єму більш менш однорідної продукції.
Вартісні (ціннісні) показники є прийнятнішими як узагальнювальні показники величини, об'єму проведеної продукції на даному підприємстві або галузі в цілому, а також і по всьому народному господарству.
Умножаючи кількість проведених продуктів на їх ціни і підсумовуючи отримані твори, отримують узагальнювальний показник кількості проведеної продукції в ціннісному виразі. За допомогою даного показника враховуються також об'єми проведених напівфабрикатів, незавершеного виробництва і інші види виконаної роботи промисловими підприємствами. Оцінка у вартісних показниках роботи промислових підприємств припускає фіксацію результатів діяльності виробничих структур на певну дату або в рамках певного відрізання часу.
При виборі оцінного показника у вартісному виразі необхідно також користуватися одними і тими ж різновидами цін, і саме, цінами оптом, роздрібними, цінами підприємств або цінами промисловості даної галузі. Проте і в цьому сенсі ціни повинні характеризуватися одними і тими ж принципами їх формування.
Особливості статистики сільськогосподарського виробництва пов'язані із специфікою даної галузі виробництва. Головні особливості сільськогосподарського виробництва пояснюються сезонним характером відтворення сільськогосподарської продукції. Завдяки сезонності сільськогосподарського виробництва його продукція, що складається з продуктів землеробства і тваринництва може повною мірою врахована тільки в рамках річного періоду.
Річна продукція підраховується у всіх господарствах з різними формами власності.
Для отримання сумарних об'ємів створеної продукції проводять її оцінку у вартісних показниках, про що мова піде в наступному параграфі.
Загальний об'єм того або іншого продукту землеробства, проведеного за вегетаційний період, - період від проростання рослини до їх прибирання, зміряний у вагових одиницях, називається валовим збором або урожаєм.
Середня величина цього ж продукту, отримана з розрахунку на одиницю земляної пощади, зайнятою даною культурою, носить назву врожайності.
Валовий збір кожної культури дорівнює твору врожайності на посівну площу зайнятою даною культурою.
В зв'язку з цим важливе значення надається обліку площ, придатних для вирощування відповідних сільськогосподарських культур. У зв'язку з цими в статистиці існує декілька категорій посівних площ:
1. обсіменена (тобто засіяна);
2. весняна продуктивна;
3. прибиральна;
4. фактично прибрана;
5. зайнята під посів.
1. Обсіменена площа - це площа. на якій проведені витрати насіння, праці, пального, тяглової сили і тому подібне Ця площа підраховується в двох варіантах:
а) площа, обсіменена під урожай даного року, яка включає озимі посіви восени минулого року і ярини - весною поточного року. Причому площі всіх ділянок, де насіння висєєвалісь кілька разів, стільки ж раз включаються в загальний підсумок даного показника;
б) площа, обсіменена в даному році, відрізняється від попереднього показника тільки тим, що замість озимих посівів минулого року в неї входять озимі посіви поточного. Знання величини обсімененої площі дозволяє підрахувати трудові і матеріальні витрати пов'язані з даним посівом.
2. Весняна продуктивна площа - це площа, зайнята посівами до кінця весняної сівби. Весняна продуктивна площа є основною категорією посівних площ. Саме ця категорія використовується для розрахунку врожайності, для аналізу структури і динаміки посівних площ.
3. Прибиральна площа - це площа, на якій повинні бути організовані прибиральні роботи. Для її підрахунку з весняної продуктивної площі необхідно відняти літню загибель посівів, посіви багаторічних трав, які в даному році не забиратимуться і не додадуть площі, де урожай зніматиметься двічі за сезон. Ця категорія посівної площі використовується для визначення витрат, пов'язаних із збиранням врожаю.
4. Фактично прибрана площа відрізняється від прибиральної на величину площ, на яких прибирання по тих або інших причинах не проводилося, хоча урожай був отриманий.
5. Площа зайнята під посів - це фізична площа, на якій були проведені посіви. Вони більше весняної продуктивної на величину площі осінньо-зимової загибелі озимини. Відношення площі, зайнятої під посів, до загальної площі ріллі утворює коефіцієнт використання ріллі.
Зведення про стан посівних площ по самих різних сільськогосподарських культурах збирається статистичними організаціями щорічно як в ході посівних робіт, так і після його закінчення в господарствах з різними формами власності: колгоспи, радгоспи, фермерські і індивідуальні господарства.
Врожайність, валовий збір найважливіших культур враховується статистикою в ході завершення робіт за підсумками сільськогосподарського року. У звітах, що представляються в кінці осіннього періоду (до 1 листопада) і в річному звіті повідомляються відомості про весняну продуктивну площу, валовому зборі за підсумками приймання збору і врожайності з 1 гектара весняної продуктивної площі. Там же наводяться дані про площі, зайняті багаторічними насадженнями по видах, і про валовий збір ягід, винограду, плодів, з виділенням насіннячок, кісточкових, горіхоплодних і субтропічних. Розміри валового збору з присадибних господарств визначаються розрахунковим способом на основі даних про посівні площі і врожайність, відомості про яку отримують з вибіркового бюджетного обстеження приватних господарств.
Всі перераховані показники діяльності сільськогосподарських підприємств мають величезне значення в аналітичній роботі з метою з'ясування динаміки змін врожайності, валового збору кожної культури. При цьому, вирівнюючи динамічні ряди з використанням раніше представленими статистичними методами, виявляють закономірності їх розвитку за тривалі періоди часу, а також чинники, що впливають на їх зміну.
При порівнянні даних про валовий збір і врожайність за два періоди широко використовують індексний метод. Індивідуальний індекс врожайності по одному господарству для кожної окремої культури обчислюється як відношення її врожайності в звітному році (Y1) до її врожайності в базисному році (Y0).
Для вимірювання ж динаміки врожайності по декількох господарствах з різним рівнем врожайності або по групі однорідних культур, валовий збір яких можна підсумовувати (наприклад, по групі зернових), необхідно будувати загальні індекси врожайності. Зміну середній врожайності можна зміряти за допомогою індексу змінного складу по формулі:
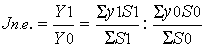
де Jnс - індекс врожайності змінного складу (змінними величинами є врожайність і площа);
y0, y1 - середня врожайність по групі господарств або по групі однорідних культур в поточному і базисному періодах відповідно;
S0, S1 - посівні площі в кожному господарстві (по кожній культурі) в поточному і базисному періоді відповідно.
Крім того, можна використовувати показники середньої врожайності по всіх господарствах в їх динаміці, тобто будувати індекс фіксованого складу по формулі
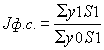
де Jф.с. - індекс врожайності фіксованого складу, решта позначень ті ж, що і в попередній формулі.
Відомо, що середня врожайність може змінюватися як за рахунок зміни врожайності, так і за рахунок зміни структури площ.
Оцінка сільськогосподарської продукції в натуральному виразі має велике значення у визначенні стану роботи тих або інших економічних структур. Проте обмежуватися цим при оцінці результатів роботи окремих господарств по територіях і формах власності неможливо у зв'язку з різноманітністю видів продукції, вироблюваних в кожному господарстві і неможливо їх підсумовувати в натуральному виразі.
Узагальнювальними показниками роботи підприємств матеріальних галузей виробництва повною мірою стають сумірними при вартісній, грошовій їх оцінці.
Стосовно сільського господарства основними вартісними показниками є валова, товарна, реалізована, чиста продукція.
Валова продукція сільського господарства обчислюється як сума валових продукций землеробства і тваринництва. Їх питома вага у валовій продукції сільського господарства приблизно однаково. Валова продукція землеробства складається з наступних складових: вартості валових зборів всіх сільськогосподарських культур урожаю поточного року, включаючи і такі побічні продукти як солома, вартості продукції вирощування багаторічних насаджень, приросту вартості незавершеного виробництва (озимих посівів, пари, зяб і тому подібне).
Товарна продукція сільського господарства є величиною вартості продукції виробленій в даному році, реалізованій по роздрібних цінах.
У товарну продукцію включаються наступні види проведених робіт.
1. Вартість всіх продуктів, проданих державі в порядку реалізації укладених контрактів.
2. Вартість всіх продуктів, реалізованих своїм робочим і службовцем або використаних на потреби громадського харчування.
3. Вартість всіх інших реалізованих продуктів.
Показник товарності окремих сільськогосподарських підприємств розраховуються як приватне від ділення товарної продукції сільського господарства на валову продукцію за той же період в одних і тих же цінах. При цьому ні в товарну, ні у валову продукцію не включають малотоварні продукти, якими є силос, солома, відходи виробництва і тому подібне При цьому з валової продукції виключають вартість вирощування багаторічних насаджень і незавершене виробництво.
Показник товарності визначається не тільки в цілому по сільськогосподарській продукції даного підприємства (колгосп, радгосп, фермерське господарство і тому подібне), але і по окремих найважливіших продуктах даного господарства.
Окрім товарної продукції в сільськогосподарському виробництві ведеться облік реалізованої продукції, тобто вартості продукції, яка була продана за ринковою ціною в поточному періоді часу (місяць, квартал, рік).
Одним з найважливіших вартісних показників, що відображають стан господарської діяльності сільськогосподарського підприємства є чиста продукція, яка характеризує знов створену вартість, тобто той дохід, який формує фонд оплати праці і накопичення даного господарства.
Величину чистої продукції сільського господарства підраховують шляхом віднімання з річної валової продукції у вартісному виразі суму матеріальних виробничих витрат того ж року.
До матеріальних витрат відноситься вартість насіння і посадочних матеріалів, кормів, підстилки, добрив, хімікатів, медикаментів, палива, горючих і змащувальних матеріалів, матеріалів використовуваних для поточного ремонту сільськогосподарських споруд, а також вартість амортизації основних виробничих сільськогосподарських фондів.
Провести оцінку господарської діяльності сільськогосподарського підприємства за підсумками поточного (звітного) року значно важче, ніж це робиться на промислових підприємствах. Це пояснюється тим, що, по-перше, одна і та ж продукція даного сільськогосподарського підприємства реалізується по різних цінах залежно від того, де і кому була продана продукція. По-друге, значна частина продукції взагалі не реалізується, а залишається в господарстві для використання на виробничі потреби усередині даного підприємства (колгосп, радгосп, фермерське господарство). Ці обставини вимушують шукати інші форми оцінок роботи в сільському господарстві. В даному випадку в практиці удаються до розмежування і відповідної оцінки товарної і нетоварної частин вироблюваної продукції.
Товарна частина оцінюється по фактичних цінах реалізації, а нетоварна частина оцінюється за собівартістю.
Валова, товарна і чиста продукція в сільськогосподарському секторі виробництва оцінюється як в поточних цінах даного року, так і в незмінних, зіставних цінах. Це робиться для отримання економічної інформації на підставі якої можна буде визначити не тільки загальні показники що характеризують діяльність трудівників аграрного сектора, але і бачити ці показники в розвитку. Крім того, на базі цих показників можна буде визначати безліч інших якісних показників, таких як продуктивність, ефективність праці і тому подібне
Періодичний перегляд зіставних незмінних цін необхідний, оскільки з часом міняється номенклатура продукції, умови її виробництва, що викликає застарівання співвідношення цін, встановлених в зіставних цінах певного року.
Розділ 2. Статистична оцінка показників виробництва льоноволокна
В результаті статистичного спостереження отримують велику кількість різноманітних відомостей про кожну одиницю досліджуваної сукупності. Проте, щоб на основі цих відомостей можна було зробити певні висновки, потрібно всю масу окремих даних привести до відповідного порядку, систематизувати, обробити і на цій основі дати зведену характеристику всієї сукупності фактів за допомогою узагальнюючих статистичних показників. Цього досягають на другому етапі статистичного дослідження, який називається зведенням і групуванням статистичних матеріалів.
Отже, статистичним зведенням називається наукова обробка первинних даних статистичного спостереження з метою отримання узагальнюючих характеристик досліджуваного явища чи процесу за рядом суттєвих для них ознак.
Статистические ряды распределения являются одним из наиболее важных элементов статистики. Они представляют собой составную часть метода статистических сводок и группировок, но, по сути, ни одно из статистических исследований невозможно произвести, не представив первоначально полученную в результате статистического наблюдения информацию в виде статистических рядов распределения.
Основною умовою для одержання правильних висновків при аналізі рядів динаміки є порівнянність його елементів.
Ряди динаміки формуються в результаті зведення й угруповання матеріалів статистичного спостереження. Повторювані в часі (по звітних періодах) значення однойменних показників у ході статистичного зведення систематизуються в хронологічній послідовності.
При цьому кожний ряд динаміки охоплює окремі відособлені періоди, у яких можуть відбуватися зміни, що приводять до непорівнянності звітних даних з даними інших періодів. Тому для аналізу ряду динаміки необхідний приведення всіх складових його елементів до порівнянного виду. Для цього відповідно до завдань дослідження встановлюються причини, що обумовили непорівнянність аналізованої інформації, і застосовується відповідна обробка, що дозволяє робити порівняння рівнів ряду динаміки.
Результати зведення і угрупування матеріалів статистичного спостереження оформляються у вигляді статистичних рядів розподілу. Статистичні ряди розподілу є впорядкованим розподілом одиниць сукупності, що вивчається, на групи за группіровочному(що варіює) ознакою. Вони характеризують склад (структуру) явища, що вивчається, дозволяють судити про однорідність сукупності, межі її зміни, закономірності розвитку спостережуваного об'єкту. Залежно від ознаки статистичні ряди розподілу діляться на:
- атрибутивні (якісні);
- варіаційні (кількісні)
а) дискретні;
б) інтервальні.
Атрибутивні ряди утворюються по якісних ознаках, якими можуть виступати посада працівників торгівлі, професія, пів, освіта і так далі
Варіаційні ряди будуються на основі кількісної группіровочногоознаки. Варіаційні ряди складаються з двох елементів: варіант і частот.
Варіанту - це окреме значення варійованої ознаки, яке він приймає у ряді розподілу. Вони можуть бути позитивними і негативними, абсолютними і відносними. Частота - це чисельність окремих варіант або кожної групи варіаційного ряду. Частоти, виражені в долях одиниці або у відсотках до підсумку, називаються частостямі. Сума частот називається об'ємом сукупності і визначає число елементів всієї сукупності.
Частості - це частоти, виражені у вигляді відносних величин (долях одиниць або відсотках). Сума частостей дорівнює одиниці або 100 %. Заміна частот частостямі дозволяє зіставляти варіаційні ряди з різним числом спостережень.
Варіаційні ряди залежно від характеру варіації підрозділяються на дискретних (переривчасті) і інтервальних (безперервні). Дискретні ряди розподілу засновані на дискретних (переривчастих) ознаках, що мають тільки цілі значення.
Інтервальні ряди розподілу базуються на значенні ознаки, що безперервно змінюється, приймає будь-які (у тому числі і дроби) кількісні вирази, тобто значення ознак таких рядах задається у вигляді інтервалу.
За наявності достатньо великої кількості варіантів значень ознаки первинний ряд є труднообозрімим, і безпосередній розгляд його не дає уявлення про розподіл одиниць за значенням ознаки в сукупності. Тому першим кроком у впорядкуванні первинного ряду є його ранжирування - розташування всіх варіантів в зростаючому (що убуває) порядку.
Для побудови дискретного ряду з невеликим числом варіантів виписуються варіанти значень ознаки, що все зустрічаються, а потім підраховується частота повторення варіанту . Ряд розподілу прийнято оформляти у вигляді таблиці, що складається з двох колонок (або рядків), в одній з яких представлені варіанти, а в іншій - частоти.
Для побудови ряду розподілу ознак, що безперервно змінюються, або дискретних, представлених у вигляді інтервалів, необхідно встановити оптимальне число груп (інтервалів), на які слід розбити всі одиниці сукупності, що вивчається.
Ряди розподілу зручно вивчати за допомогою графічного методу.
Статистичний графік - це креслення, на якому статистичні сукупності, такі, що характеризуються певними показниками, описуються за допомогою умовних геометричних образів або знаків. Представлення даних таблиць у вигляді графіка справляє сильніше враження, ніж цифри, дозволяє краще осмислити результати статистичного спостереження, правильно їх тлумачити, значно полегшує розуміння статистичного матеріалу, робить його наочним і доступним. Це, проте, зовсім не означає, що графіки мають лише ілюстративне значення. Вони дають нове знання про предмет дослідження, будучи методом узагальнення початкової інформації.
Значення графічного методу в аналізі і узагальненні даних велике. Графічне зображення дозволяє здійснити контроль достовірності статистичних показників, оскільки, представлені на графіці, вони яскравіше показують наявні неточності, пов'язані або з наявністю помилок спостереження, або з суттю явища, що вивчається. За допомогою графічного зображення можливі вивчення закономірностей розвитку явища, встановлення існуючих взаємозв'язків. Просте зіставлення даних не завжди дає можливість уловити наявність причинних залежностей, в той же час їх графічне зображення сприяє виявленню причинних зв'язків, особливо у разі встановлення первинних гіпотез, що підлягають потім подальшій розробці. Графіки також широко використовуються для вивчення структури явищ, їх зміни в часі і розміщення в просторі. У них виразніше виявляються порівняльні характеристики і виразно види основні тенденції розвитку і взаємозв'язку, властиві явищу, що вивчається, або процесу.
Для зображення і внесення думок про розвиток явища в часі і складі сукупності разом з графіками будуються діаграми.
Використовуються діаграми: стовпчикові, стрічкові, квадратні, круги, лінійні, радикальні і ін. Вибір виду діаграми залежить в основному від особливостей початкових даних, мети дослідження.
Проаналізуємо наявну інформацію.
1) проведемо групування і складемо ряд розподілу, вибравши в якості ознаки групування ознаку показник «Урожайність льоноволокна ».
Візначаємо ширину інтервалу за формулою:
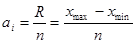
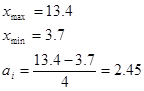
Визначаємо границі інтервалів:
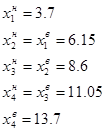
Визначаємо кількість статистичних одиниць, які потрапляють у кожний інтервал розподілу:
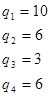
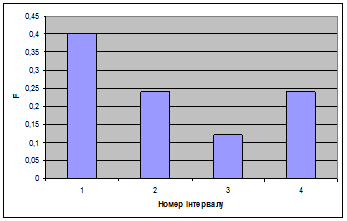
Визначаємо відносні частоти статистичних одиниць, які потрапляють у кожний інтервал розподілу:
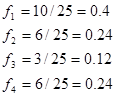
Будуємо гістограму ряду розподілу:
Будуємо полігон ряду розподілу:
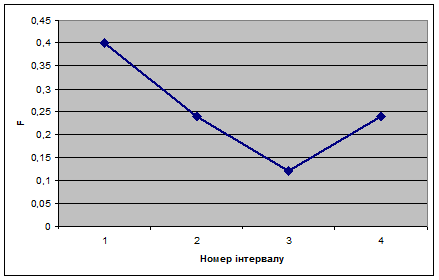
Будуємо кумуляту ряду розподілу:
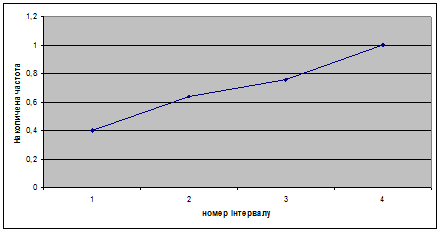
2) проведемо групування і складемо ряд розподілу, вибравши в якості ознаки групування ознаку показник «Якість льонотрести».
Візначаємо ширину інтервалу за формулою:
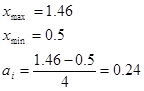
Визначаємо границі інтервалів:
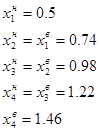
Визначаємо кількість статистичних одиниць, які потрапляють у кожний інтервал розподілу:
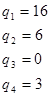
Визначаємо відносні частоти статистичних одиниць, які потрапляють у кожний інтервал розподілу:
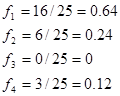
Будуємо гістограму ряду розподілу:
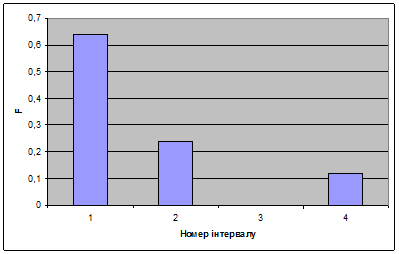
Будуємо полігон ряду розподілу:
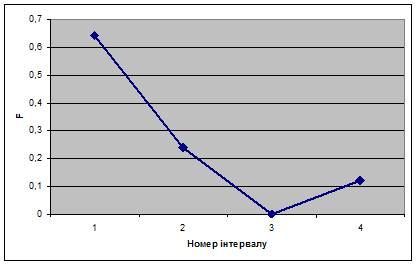
Будуємо кумуляту ряду розподілу:
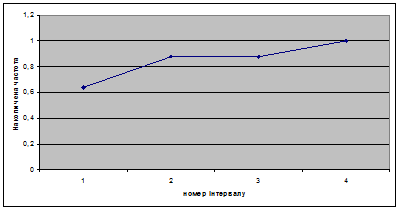
3) проведемо групування і складемо ряд розподілу, вибравши в якості ознаки групування ознаку показник «Витрати праці на 1 центнер трести».
Візначаємо ширину інтервалу за формулою:
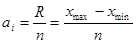
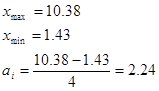
Визначаємо границі інтервалів:
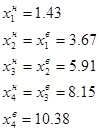
Визначаємо кількість статистичних одиниць, які потрапляють у кожний інтервал розподілу:
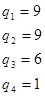
Визначаємо відносні частоти статистичних одиниць, які потрапляють у кожний інтервал розподілу:
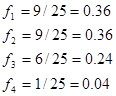
Будуємо гістограму ряду розподілу:
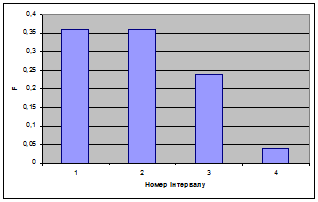
Будуємо полігон ряду розподілу:
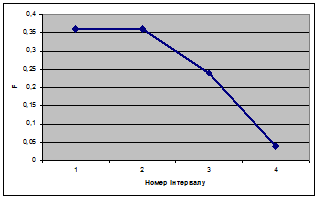
Будуємо кумуляту ряду розподілу:
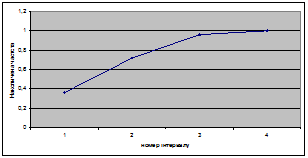
Виконаємо комбінаційне групування за ознаками «Урожайність льоноволокна» та «Якість льонотрести»:
| Урожайність льоноволокна, ц/га |
Якість льонотрести, номер |
Разом |
| 0,5-0,74 |
0,74-0,98 |
0,98-1,22 |
1,22-1,46 |
| 3,7-6,15 |
10 |
10 |
| 6,15-8,6 |
6 |
6 |
| 8,6-11,05 |
3 |
2 |
5 |
| 11,05-13,7 |
2 |
2 |
4 |
| Разом |
13 |
8 |
2 |
2 |
Аналіз комбінаційного групування вказує на існування прямого зв’язку між урожайністю льоноволокна та якістю льонотрести.
Виконаємо комбінаційне групування за ознаками «Урожайність льоноволокна» та «Витрати праці на 1 центнер трести, люд/год»:
| Урожайність льоноволокна, ц/га |
Витрати праці на 1 центнер трести, люд/год
|
Разом |
| 1,43-3,67 |
3,67-5,91 |
5,91-8,15 |
8,15-10,38 |
| 3,7-6,15 |
3 |
4 |
3 |
10 |
| 6,15-8,6 |
2 |
2 |
2 |
6 |
| 8,6-11,05 |
2 |
2 |
1 |
5 |
| 11,05-13,7 |
2 |
1 |
1 |
4 |
| Разом |
9 |
9 |
6 |
1 |
Аналіз комбінаційного групування вказує на відсутність прямого зв’язку між урожайністю льоноволокна та витратами праці на 1 центнер трести.
Виконаємо комбінаційне групування за ознаками «Якість льонотрести» та «Витрати праці на 1 центнер трести»:
| Якість льонотрести, номер |
Витрати праці на 1 центнер трести, люд/год |
Разом |
| 1,43-3,67 |
3,67-5,91 |
5,91-8,15 |
8,15-10,38 |
| 0,5-0,74 |
6 |
6 |
2 |
14 |
| 0,74-0,98 |
2 |
1 |
4 |
1 |
8 |
| 0,98-1,22 |
0 |
| 1,22-1,46 |
3 |
3 |
| Разом |
8 |
10 |
6 |
1 |
Аналіз комбінаційного групування вказує на наявність певного прямого зв’язку між якістю льонотрести та витратами праці на 1 центнер трести.
Вибірковим називається таке статистичне дослідження, при якому узагальнювальні показники сукупності, що вивчається, встановлюються по деякій її частині, сформованій на основі положень випадкового відбору.
У основі вибіркового дослідження лежить несуцільне спостереження, при якому обстежуються не всі одиниці сукупності, а лише певна їх частина.
Вибіркове дослідження широко застосовується на практиці, оскільки володіє істотними перевагами в порівнянні з іншими методами отримання статистичних даних. До них відносяться:
· Достатньо висока точність результатів обстеження завдяки використанню більш кваліфікованих кадрів, що приводить до скорочення помилок реєстрації;
· Економія часу і засобів в результаті скорочення об'єму роботи, велика оперативність в отриманні даних про результати обстеження;
· Можливість дослідження дуже великих статистичних совокупностей;
· Вибірковий метод є єдино можливим, якщо збір інформації пов'язаний з руйнуванням або втратою одиниць спостереження, наприклад, при органалітічеськом контролі якості продукції;
· Можливість дослідження повністю недоступних совокупностей. При вибірковому дослідженні вивчається порівняно невелика частина статистичної сукупності (5-10%, рідше 20-25% об'єму її одиниць).
Проведення вибіркового дослідження є достатньо складним процесом, виконання якого включає:
· обгрунтування доцільності застосування вибіркового методу в даному дослідженні;
· складання програми дослідження;
· встановлення об'єму вибірки - n;
· обгрунтування способу формування вибірки;
· відбір одиниць з Генеральної сукупності ( формування вибірки);
· вимірювання ознак, що вивчаються, у окремих одиниць;
· обробка отриманої інформації і розрахунок характеристик вибірки;
· визначення помилки вибірки;
· розповсюдження вибіркових характеристик на Генеральну сукупність.
Для постановки завдання вибіркового дослідження необхідно ввести наступні поняття:
- Генеральна сукупність - сукупність, що вивчається, з якої проводиться відбір одиниць, що підлягають вивченню, вона може бути кінцевою (N) або нескінченною (н).
- Вибіркова сукупність ( вибірка) - частина одиниць генеральної сукупності, відібрана для вивчення (n). Якість результатів вибіркового дослідження залежить від того, наскільки склад вибірки представляє генеральну сукупність, інакше кажучи, наскільки вибірка репрезентативна.
Під репрезентативністю вибірки розуміється відповідність її властивостей і структури властивостям і структурі генеральної сукупності. Репрезентативність вибірки може бути забезпечена тільки при об'єктивності відбору даних, що гарантується принципами випадковості відбору одиниць.
Принцип випадковості припускає, що на включення або виключення статистичної одиниці з вибірки не може вплинути ніякій інший чинник, окрім випадку. Цей принцип лежить в основі методів випадкового відбору, за допомогою яких формується вибірка.
Використання методів випадкового відбору при формуванні вибірки дозволяє надалі при обробці використовувати апарат теорії вірогідності.
Найчастіше за допомогою вибіркового дослідження визначаються наступні характеристики генеральної сукупності:
· Середнє значення ознаки в сукупності - X, розраховується як середня арифметична.
· Частка альтернативної ознаки в сукупності - в . Альтернативною вважається ознака, що набуває два значення. Якщо одне з них змінюється як задане, то частка альтернативної ознаки характеризуватиме питому вагу статистичних одиниць, що володіють заданим значенням альтернативної ознаки, наприклад, частка браку у виготовленій партії продукції;
· Дисперсія ознаки в сукупності - 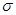 2
, як показник варіації. 2
, як показник варіації.
У загальному вигляді завдання вибіркового дослідження формулюється таким чином: Хай є деяка генеральна сукупність відомого об'єму ( N одиниць). Необхідно на основі відомих характеристик вибірки отримати статистичні оцінки характеристик генеральної сукупності.
Статистичною оцінкою або статистикою характеристики (параметра) генеральної сукупності називають наближене значення шуканої характеристики (параметра), отримане за даними вибірки.
У статистиці використовуються два види оцінок - точкові і інтервальні.
Точковою статистичною оцінкою параметра генеральної сукупності називається конкретне числове значення шуканої характеристики.
Інтервальна оцінка є числовими інтервалами, що імовірно містять значення параметра генеральної сукупності.
Якість статистичних оцінок визначається наступними їх властивостями:
Спроможність: оцінка вважається спроможною, якщо при необмеженому збільшенні об'єму вибірки її помилка прагне до 0.
Незміщеність: оцінка вважається незміщеною, якщо при даному об'ємі вибірки n математичне очікування помилки дорівнює 0. Для незміщеної оцінки її математичне очікування точно дорівнює математичному очікуванню характеристики вибірки.
Незміщена оцінка не завжди дає хороше наближення оцінюваного параметра, оскільки можливі значення отримуваної оцінки можуть бути сильно розсіяні навколо свого середнього значення. Тому оцінка повинна відповідати ще одній вимозі - ефективності.
Ефективність: оцінка вважається ефективною, якщо її помилка, звана помилкою вибірки, є величиною мінімальною.
Для точкових оцінок справедливі наступні твердження:
· Точковою оцінкою генеральної частки є вибіркова частка
· Точковою оцінкою генеральною середньою є вибіркова середня
Таким чином, заздалегідь відомо, що оцінки для вказаних параметрів є спроможними і незміщеними. Для решти параметрів генеральної сукупності це твердження не є справедливим. У математичній статистиці доводиться, що точковою оцінкою генеральної дисперсії є вибіркова дисперсія, відкоректована на відношення 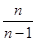 . Аналогічно, точковою оцінкою генерального среднеквадратічеськоговідхилення є вибіркове среднеквадратічеськоєвідхилення, відкоректоване на . . Аналогічно, точковою оцінкою генерального среднеквадратічеськоговідхилення є вибіркове среднеквадратічеськоєвідхилення, відкоректоване на .
В цьому випадку точкові оцінки генеральної дисперсії і генерального среднеквадратічеськоговідхилення є спроможними і незміщеними. Основним недоліком точкових оцінок є те, що вони не враховують помилки вибірки, тобто не є ефективними. Тому переважнішими є інтервальні оцінки параметрів генеральної сукупності, в яких ці помилки враховуються. Інтервальні оцінки відповідають всім трьом вимогам якості статистичної оцінки. Застосування інтервальних оцінок означає, що характеристики генеральної сукупності укладаються в певний діапазон значень. Щоб їх отримати, необхідно розрахувати відповідні помилки вибірки.
Розрахуємо середні арифметичні значення ознак в вибірковій сукупності. Розрахунки будемо виконувати на основі групувань, проведених вище. Для виконання розрахунків не обходимо визначити середнє значення відповідної ознаки в кожній групі.
Ознака «Урожайність льоноволокна»:
| Номер інтервалу |
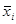 |
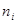 |
| 1 |
4,89 |
10 |
| 2 |
7,166667 |
6 |
| 3 |
9,433333 |
3 |
| 4 |
12 |
6 |
Отже, 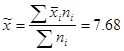
Ознака «Якість льонотрести»
| Номер інтервалу |
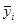 |
|
| 1 |
0,603125 |
16 |
| 2 |
0,855 |
6 |
| 3 |
0 |
0 |
| 4 |
1,353333 |
3 |
Отже, 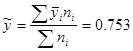
Ознака «Витрати праці на 1 центнер трести»:
| Номер інтервалу |
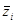 |
|
| 1 |
2,823333 |
9 |
| 2 |
4,632222 |
9 |
| 3 |
6,996667 |
6 |
| 4 |
10,38 |
1 |
Отже, 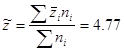
Розраховані вибіркові середні досліджуваних ознак є точковими оцінками генеральних середніх відповідних ознак.
Розрахуємо вибіркові дисперсії досліджуваних ознак:
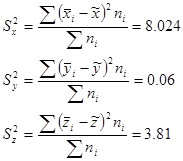
Розрахуємо середні квадратичні відхилння досліджуваних ознак:
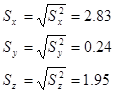
Розрахуємо точкові незміщені оцінки дисперсій генеральної сукупності.
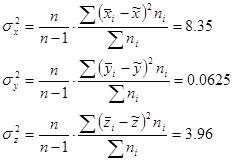
Розрахуємо незміщені середні квадратичні відхилння досліджуваних ознак:
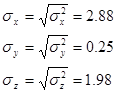
Вважаючи, що надані дані є 5% вибіркою, розрахуємо інтервальні оцінки показників.
Середні похибки вибірки:
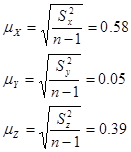
Граничні похибки вибірки при довірчій ймовірності 0,997:
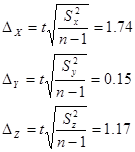
Отже, довірчі інтервали для генеральних середніх:
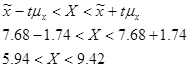
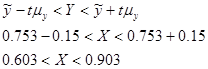
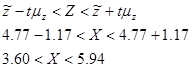
Розрахуємо коефіцієнти варіації:
Ознака «Урожайність льоноволокна»:
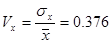 - свідчить про неоднорідність досліджуваної сукупності - свідчить про неоднорідність досліджуваної сукупності
Ознака «Якість льонотрести»
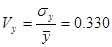 - свідчить про однорідність досліджуваної сукупності - свідчить про однорідність досліджуваної сукупності
Ознака «Витрати праці на 1 центнер трести»:
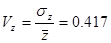 - свідчить про неоднорідність досліджуваної сукупності - свідчить про неоднорідність досліджуваної сукупності
Розрахуємо структурі середні – моду та медіану кожної ознаки.
Медіана (Ме) - це величина, яка відповідає варіанту, що знаходиться в середині ранжируваного ряду.
Модою (Мо-пермалой) називають значення ознаки, яке зустрічається найчастіше у одиниць сукупності. Для дискретного ряду модою буде варіант з найбільшою частотою.
Ознака «Урожайність льоноволокна»:
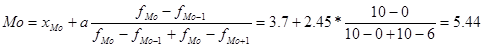
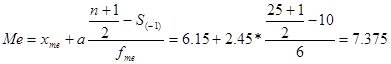
Ознака «Якість льонотрести»
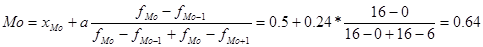
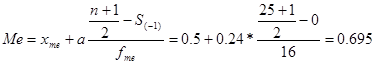
Ознака «Витрати праці на 1 центнер трести»:
Цей ряд розподілу є двомодальним.
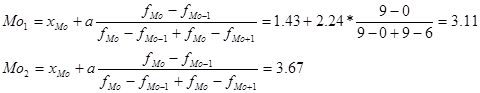
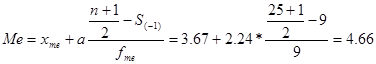
2.3 Перевірка статистичної гіпотези про відповідність емпіричного ряду розподілу нормальному
Основною метою аналізу варіаційних рядів є виявлення закономірності розподілу, виключаючи при цьому вплив випадкових для даного розподілу чинників. Цього можна досягти, якщо збільшувати об'єм досліджуваної сукупності і одночасно зменшувати інтервал ряду. При спробі зображення цих даних графічно ми отримаємо деяку плавну криву лінію, яка для полігону частот буде деякою межею. Цю лінію називають кривою розподіли.
Іншими словами, крива розподілу є графічне зображення у вигляді безперервної лінії зміни частот у варіаційному ряду, яке функціонально пов'язане із зміною варіант. Крива розподілу відображає закономірність зміни частот за відсутності випадкових чинників. Графічне зображення полегшує аналіз рядів розподілу.
Відомо достатньо багато форм кривих розподіли, по яких може вирівнюватися варіаційний ряд, але в практиці статистичних досліджень найчастіше використовуються такі форми, як нормальний розподіл і розподіл Пуассона.
Нормальний розподіл залежить від двох параметрів: середньою арифметичною 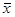 і середнього квадратичного відхилення . Його крива виражається рівнянням і середнього квадратичного відхилення . Його крива виражається рівнянням
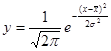
Якщо потрібно отримати теоретичні частоти f' при вирівнюванні варіаційного ряду по кривій нормального розподілу, то можна скористатися формулою:
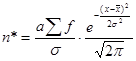
За допомогою цієї формули ми отримуємо теоретичний (імовірнісне) розподіл, замінюючи ним емпіричний (фактичне) розподіл, по характеру вони не повинні відрізнятися один від одного.
Порівнюючи отримані величини теоретичних частот n* з емпіричними (фактичними) частотами n, переконуємося, що їх розбіжності можуть бути вельми невеликі.
Об'єктивна характеристика відповідності теоретичних і емпіричних частот може бути отримана за допомогою спеціальних статистичних показників, які називають критеріями згоди.
Для оцінки близькості емпіричних і теоретичних частот застосовуються критерій згоди Пірсону, критерій згоди Романовського, критерій згоди Колмогорова.
Найбільш поширеним є критерій згоди К. Пірсона 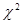 , який можна представити як суму відносин квадратів розбіжностей між n* і n до теоретичних частот: , який можна представити як суму відносин квадратів розбіжностей між n* і n до теоретичних частот:
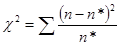
Обчислене значення критерію 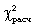 необхідно порівняти з табличним (критичним) значенням необхідно порівняти з табличним (критичним) значенням 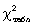 . Табличне значення визначається по спеціальній таблиці, воно залежить від прийнятої вірогідності Р і числа мір свободи до (при цьому до = m - 3, де m - число груп у ряді розподілу для нормального розподілу). При розрахунку критерію згоди Пірсону повинна дотримуватися наступна умова: достатньо великим повинне бути число спостережень (n . Табличне значення визначається по спеціальній таблиці, воно залежить від прийнятої вірогідності Р і числа мір свободи до (при цьому до = m - 3, де m - число груп у ряді розподілу для нормального розподілу). При розрахунку критерію згоди Пірсону повинна дотримуватися наступна умова: достатньо великим повинне бути число спостережень (n  50), при цьому якщо в деяких інтервалах теоретичні частоти < 5, то інтервали об'єднують для умови > 5. 50), при цьому якщо в деяких інтервалах теоретичні частоти < 5, то інтервали об'єднують для умови > 5.
Якщо 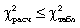 , то розбіжності між емпіричними і теоретичними частотами розподілу можуть бути випадковими і припущення про близькість емпіричного розподілу до нормального не може бути спростована. , то розбіжності між емпіричними і теоретичними частотами розподілу можуть бути випадковими і припущення про близькість емпіричного розподілу до нормального не може бути спростована.
Перевіримо статистичну гіпотезу про відповідність статистичного розподілу за ознакою «Урожайність льоноволокну» нормальному закону розподілу.
| Номер інтервалу |
|
|
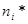 |
| 1 |
4,89 |
10 |
5,337562 |
| 2 |
7,166667 |
6 |
8,373766 |
| 3 |
9,433333 |
3 |
7,076648 |
| 4 |
12 |
6 |
2,782567 |
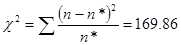
Критичнее значення критерія Пірсона при рівні значущості 0,058 та ступені свободи 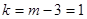 дорівнює 3,84 дорівнює 3,84
Оскільки розраховане значення критерію Персона більше за критичне, то розбіжності між емпіричними і теоретичними частотами розподілу не можуть бути випадковими і припущення про близькість емпіричного розподілу до нормального повинна бути спростоване.
Отже,
Перевіримо статистичну гіпотезу про відповідність статистичного розподілу за ознакою «Якість льонотрести» нормальному закону розподілу.
| Номер інтервалу |
|
|
|
| 1 |
0,603125 |
16 |
8,020999 |
| 2 |
0,855 |
6 |
8,833321 |
| 3 |
0 |
0 |
0,102868 |
| 4 |
1,353333 |
3 |
0,537173 |
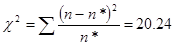
Критичнее значення критерія Пірсона при рівні значущості 0,05 та ступені свободи дорівнює 3,84
Оскільки розраховане значення критерію Персона більше за критичне, то розбіжності між емпіричними і теоретичними частотами розподілу не можуть бути випадковими і припущення про близькість емпіричного розподілу до нормального повинна бути спростоване.
Перевіримо статистичну гіпотезу про відповідність статистичного розподілу за ознакою «Витрати праці на 1 центнер трести» нормальному закону розподілу.
| Номер інтервалу |
|
|
|
| 1 |
2,823333 |
9 |
6,979346 |
| 2 |
4,632222 |
9 |
11,23498 |
| 3 |
6,996667 |
6 |
6,021962 |
| 4 |
10,38 |
1 |
0,211756 |
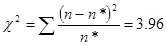
Критичнее значення критерія Пірсона при рівні значущості 0,05 та ступені свободи дорівнює 3,84
Оскільки розраховане значення критерію Персона більше за критичне, то з ймовірністю 95% розбіжності між емпіричними і теоретичними частотами розподілу не можуть бути випадковими і припущення про близькість емпіричного розподілу до нормального повинна бути спростоване.
Розділ 3. Кореляційний аналіз виробництва льоноволокна
Одним з найважливіших завдань статистики є вивчення об'єктивно існуючих зв'язків між явищами. При дослідженні таких зв'язків з'ясовуються причинно-наслідкові відносини між явищами, а це, у свою чергу, дозволяє виявити чинники, що роблять основний вплив на варіацію явищ, що вивчаються, і процесів. Причинно-наслідкові відносини є таким зв'язком явищ, при якому зміну одну з них, - причини, веде до зміни іншого - следствія. Причинно-наслідкова форма зв'язку визначає всі інші форми, носить загальний і багатообразний характер. Для опису причинно-наслідкового зв'язку між явищами і процесами використовується ділення статистичних ознак, що відображають окремі сторони взаємозв'язаних явищ, на факторних і результативних. Факторними вважаються ознаки, обуславлівающиезміна інших, пов'язаних з ними ознак, що є причинами і умовами таких змін. Результативними є ознаки, такими, що змінюються під впливом факторних. Форми прояву існуючих взаємозв'язків вельми різноманітні. Як найзагальніші їх види виділяють функціональний і статистичний зв'язки. Функціональною називають такий зв'язок, при якому певному значенню факторної ознаки відповідає одне і лише одне значення результативне. Такий зв'язок можливий за умови, що на поведінку однієї ознаки ( результативного) впливає тільки друга ознака (факторний) і ніякі інші. Такі зв'язки є абстракціями, в реальному житті вони зустрічаються рідко, але знаходять широке застосування в точних науках в е р б першу чергу, в математиці.
Функціональний зв'язок виявляється у всіх випадках спостереження і для кожної конкретної одиниці сукупності, що вивчається. У масових явищах виявляються статистичні зв'язки, при яких строго певному значенню факторної ознаки ставиться у відповідність безліч значень результативного. Такі зв'язки мають місце, якщо на результативну ознаку діють декілька факторних, а для опису зв'язку використовується один або декілька визначальних (врахованих) чинників.
Строга відмінність між функціональним і статистичним зв'язком можна отримати при їх математичному формулюванні.
Функціональний зв'язок можна представити рівнянням: 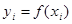
Статистичний зв'язок може бути представлена рівнянням наступного вигляду: 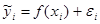
Де 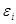 - частина значення результативної ознаки, що виникає унаслідок дії неконтрольованих чинників або помилок вимірювання. - частина значення результативної ознаки, що виникає унаслідок дії неконтрольованих чинників або помилок вимірювання.
По напряму кореляційні зв'язки діляться на прямих і зворотних. При прямому зв'язку результативна ознака росте із збільшенням факторного, при зворотній - зростання факторної ознаки призводить до зниження значень результативної ознаки. Наприклад, чим більше стаж роботи, тим вище продуктивність праці - прямий зв'язок, а чим вище продуктивність праці, тим нижче собівартість одиниці продукції - зворотний зв'язок. За формою (аналітичному виразу) зв'язку діляться на лінійні ( прямолінійні) і нелінійні ( криволінійні) зв'язки. Лінійні зв'язки виражаються рівнянням прямої, а нелінійні - рівнянням параболи, гіперболи, статечної і тому подібне По кількості взаємодіючих чинників зв'язку діляться на парний ( однофакторную) і множинний ( багатофакторну) зв'язки. При парному зв'язку на результативну ознаку діє один факторний, при множинній - декілька факторних ознак. Дослідження статистичного зв'язку проводиться в наступному порядку:
якісний аналіз зв'язку - визначення складу ознак, попередній аналіз форми зв'язку;
· збір даних на основі статистичного спостереження;
· кількісна оцінка тісноти зв'язку за емпіричними даними;
· регресійний аналіз (аналітичний опис зв'язку):
· вибір форми зв'язку
· оцінка параметрів моделі
· оцінка якості моделі.
Основним методом вивчення статистичного взаємозв'язку є статистичне моделювання зв'язку на основі кореляційного і регресійного аналізу. Завданням кореляційного аналізу є кількісне визначення тісноти зв'язку між двома ознаками при парному зв'язку або між результативним і декількома факторними при множинному зв'язку. Регресійний аналіз полягає у визначенні аналітичного виразу зв'язку у вигляді рівняння регресії. Регресією називається залежність середнього значення випадкової величини результативної ознаки від величини факторного, а рівнянням регресії - рівняння описує кореляційну залежність між результативною ознакою і одним або декільком факторними.
Найповніше в статистиці розроблена методологія парної кореляції, що розглядає вплив варіації однієї факторної ознаки на результатний. Дослідження парної кореляції здійснюється на основі кореляційного аналізу, який припускає послідовне вирішення ряду завдань:
• Виявлення зв'язку;
• Опис зв'язку в табличній і графічній формах;
• Вимірювання тісноти зв'язку;
• Формулювання виводів про характер існуючого зв'язку.
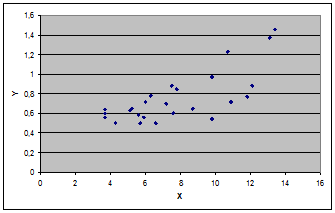
Завдання виявлення зв'язку між факторною і результативною ознаками може бути вирішена за допомогою наступних прийомів: - візуалізація зв'язку (побудова і візуальний аналіз кореляційного поля); - використання результатів аналітичного угрупування і ін. Кореляційним полем є точковий графік в системі координат {x,y}. Кожна крапка відповідає одиниці сукупності. Положення крапок на графіці визначається величиною двох ознак - факторного і результативного. Точки кореляційного поля можуть розташовуватися на графіці хаотично, без всякої закономірності - тоді робиться вивід про відсутність зв'язку між ознаками; або певним чином уздовж деякої гіпотетичної лінії - тоді робиться вивід про існування зв'язку між ознаками.
При другому способі - використанні результатів аналітичного угрупування зв'язок вважається встановленим, якщо угрупування показує зміну середнього значення результативної ознаки в групах при зміні факторної ознаки (підстави угрупування).
Опис виявленого зв'язку при проведенні кореляційного аналізу проводиться в двох формах - табличною і графічною. При табличному описі зв'язку статистичні одиниці групуються за значенням факторної ознаки ( розташовуються в порядку його зростання або убування)
Графічний опис зв'язку полягає в побудові лінії емпіричної регресії - ламаній лінії, що сполучає на кореляційному полі крапки, абсцисами яких є значення факторної ознаки ( індивідуальні значення або групові значення), а ординатами - середні значення результативної ознаки. Емпірична лінія регресії відображає основну тенденцію даної залежності. Якщо по своєму вигляду вона наближається до прямої лінії, то можна припустити наявність прямолінійного зв'язку між ознаками.
Тіснота зв'язку показує міру впливу факторної ознаки на загальну варіацію результативної ознаки.
На емпіричному рівні, при проведенні кореляційного аналізу тіснота зв'язку вимірюється за допомогою інтегральних показників, побудованих на правилі складання дисперсії. Відповідно до нього загальна дисперсія результативної ознаки розкладається на внутрішньогрупову і міжгрупову.
Через співвідношення дисперсій визначаються показники, що вимірюють ступінь тісноти зв'язку між результативними і факторними ознаками: коефіцієнт детерміації 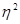 2 і емпіричне кореляційне відношення 2 і емпіричне кореляційне відношення 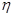 . .
Коефіцієнт детерміації розраховується по формулі:
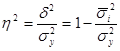
Приведене відношення визначає питома вага варіації, з'ясовної впливом врахованого чинника на результат, в загальній варіації результативної ознаки. Показник змінюється в діапазоні від 0 до 1.
Коефіцієнт детерміації складно інтерпретується, тому на його основі розраховується ще один показник тісноти зв'язку - емпіричне кореляційне відношення .
Емпіричне кореляційне відношення розраховується по формулі: 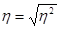 . Діапазон зміни цього показника: від 0 до 1 . Нульове значення емпіричного кореляційного відношення означає відсутність зв'язку між результативною і факторною ознаками, при . Діапазон зміни цього показника: від 0 до 1 . Нульове значення емпіричного кореляційного відношення означає відсутність зв'язку між результативною і факторною ознаками, при 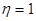 зв'язок класифікується як функціональна. зв'язок класифікується як функціональна.
Якщо відомо, що між результативною і факторною ознакою існує лінійний зв'язок, то для оцінки її тісноти використовується лінійний коефіцієнт кореляції, що розраховується по формулі:
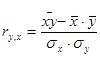
На основе предоставленных данных исследуем с помощью коэффициента линейной корреляции тесноту связи между признаками Х («Урожайность льноволокна»), В («Качество ленотрести») («Расходы труда на 1 центнер ленотрести»):
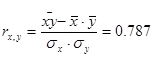
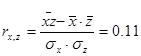
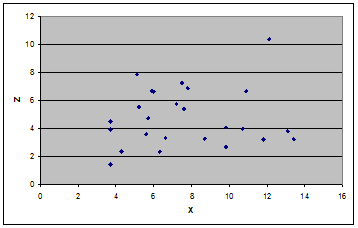
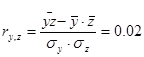

Такимчином, згідно із класифікацією Чеддока зв'язок між показниками «Урожайність льоноволокна» та «Якість льонотрести» можна вважати прямим тісним, зв'язок між показниками «Урожайність льоноволокна» та «Витрати праці на 1 центнер льонотрести» можна вважати прямим слабким, а зв'язок між показниками «Якість льонотрести» та «Витрати праці на 1 центнер льонотрести» відсутня.
Для коефіцієнту кореляції 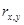 значення критерію Стьюдента становить: значення критерію Стьюдента становить:
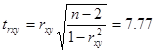
Для коефіцієнту кореляції 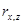 значення критерію Стьюдента становить: значення критерію Стьюдента становить:
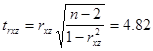
Для коефіцієнту кореляції 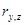 значення критерію Стьюдента становить: значення критерію Стьюдента становить:
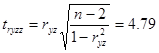
Критичнее значення критерію Стьюдента при рівні значущості 0,05 та 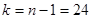 становить 2,063. становить 2,063.
Оскільки розраховані значення критерію Стьюдента для коефіцієнтів кореляції більші за критичне, можна стверджувати, що числові значення цих коефіцієнтів не являються випадковими.
Між параметрами моделі можливі також випадки криволінійної кореляції Для дослідження такої залежності потрібно досліджувану сукупність розділити на інтервали, які мають прямолінійний характер, і дослідити кожний участок окремо.
Дослідимо криволінійну кореляцію між ознаками Х та У. Дослідимо окремо участки 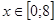 та та 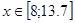
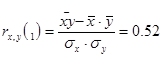
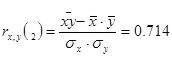
Бачимо, що при урожайності льоноволокна меншою за 8 ц/га, залежність між урожайністю льоноволокна та якістю льонотрести є помірною, а при урожайності льоноволокна більше за 8 ц/га, залежність між урожайністю льоноволокна та якістю льонотрести є тісною.
Дослідимо криволінійну кореляцію між ознаками Х та 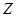 . Дослідимо окремо участки та : . Дослідимо окремо участки та :
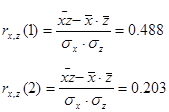
Бачимо, що при урожайності льоноволокна меншою за 8 ц/га, залежність між урожайністю льоноволокна та витратами праці на 1 центнер льонотрести є помірною, а при урожайності льоноволокна більше за 8 ц/га, залежність між урожайністю льоноволокна та витратами праці на 1 центнер льонотрести є слабкою.
Дослідимо криволінійну кореляцію між ознаками У та . Дослідимо окремо участки 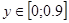 та та 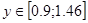 : :
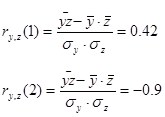
Бачимо, що при залежність між якістю льонотрести та витратами праці на 1 центнер льонотрести є прямою помірною, а при залежність між якістю льонотрести та витратами праці на 1 центнер льонотрести є зворотньою функціональною.
Двомірні кореляційні моделі ( парна кореляція) використовуються у випадках, коли серед чинників, що впливають на результативну ознаку, є домінуючий. Такі зв'язків небагато, частіше зустрічаються залежності результативної ознаки від декількох факторних, оскільки економічні явища знаходяться під впливом значного числа одночасно і чинників, що сукупно діють.
Завдання множинного кореляційно-регресійного аналізу в загальному вигляді формулюється таким чином: Хай деяка статистична сукупність, що складається з n одиниць спостереження володіє певним набором ознак, один з яких грає роль результативного, а останні - факторних . На основі спостережуваних значень всіх ознак потрібно виявити і описати зв'язок між ними у вигляді множинної кореляційної моделі вигляду: 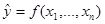 . .
Рішення даної задачі вимагає послідовного виконання наступних етапів дослідження множинного кореляційного зв'язку:
• попередній відбір чинників, що включаються в модель;
• попередній опис зв'язку;
• уточнення моделі на основі аналізу кореляційної матриці;
• визначення тісноти зв'язку;
• оцінка надійності множинної кореляційної моделі;
• інтерпретація моделі.
Вивчення множинної регресії ( кореляції) вимагає вимірювання не тільки прямої дії кожного чинника на результат, але і обліку впливу чинників один на одного, тобто обліку наявності міжфакторних зв'язків. Загальне число зв'язків завжди значно більше числа чинників, що включаються в модель. Воно визначається виразом:
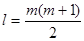
де 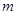 – кількість факторних ознак, включених в модель. – кількість факторних ознак, включених в модель.
У загальному випадку, при великому числі чинників, що враховуються, необхідно будувати складні моделі, що вимагають проведення складних розрахунків; моделі виходять громіздкими. З іншого боку, - чим велика кількість чинників враховується, тим адекватніше побудована модель. Для вирішення вказаного протиріччя заздалегідь обмежується число чинників, що враховуються . Доцільність їх включення в модель визначається наступними міркуваннями:
· вони повинні бути соїзмеріми, мати кількісний вираз;
· чинники не повинні бути інтеркорреліровани, тобто тісно зв'язаними між собою;
· вони повинні пояснювати варіацію результативної ознаки.
При включенні в модель інтеркоррелірованнихчинників неможливо визначити ізольований вплив таких чинників на результативний показник, а оцінки параметрів рівняння множинної регресії будуть ненадійними, залежними від спостережень.
Попередній опис множинного кореляційного зв'язку ( МКЗ) здійснюється через побудову відповідного рівняння регресії. Практика показує, що можна використовувати наступні п'ять функцій, оскільки вони описують всі реально існуючі залежності між соціально-економічними явищами:
1. лінійна ;
2. статечна ;
3. показова (експотенциональная);
4. параболічна;
5. гіперболічна .
Працювати з нелінійними функціями складно, тому основне значення мають лінійні моделі через їх простоту і логічність економічної інтерпретації. Нелінійні форми завжди можна привести до лінійної, використовуючи відомий в математиці прийом лінеаризації функцій. Величина кожного параметра в рівнянні прямої може бути визначена по методу найменших квадратів.
При виборі форми рівняння множинної регресії необхідно мати на увазі:
1. Чим складніше функція, тим гірше інтерпретуються параметри моделі.
2. Складні функції ( поліноми) з великою кількістю чинників вимагають великого числа спостережень ( на кожен параметр не менше 6 спостережень)
Остаточний відбір чинників, тобто уточнення кореляційної моделі проводиться на основі аналізу кореляційної матриці. Кореляційна матриця складається з парних лінійних коефіцієнтів кореляції юшок r, що відображають тісноту зв'язку результативної і факторної ознаки і коефіцієнтів інтеркорреляції, що відображають тісноту зв'язку між i-м і j-м факторними ознаками.
Оцінка тісноти множинного кореляційного зв'язку проводиться на основі двох показників: множинного коефіцієнта детерміації і множинного коефіцієнта кореляції .
Для двохфакторної моделі множинний коефіцієнт кореляції визначається по формулі:
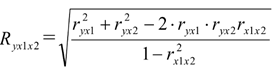
Діапазон зміни множинного коефіцієнта кореляції від 0 до 1. «0» означає відсутність зв'язку, «1» - наявність функціонального множинного зв'язку між ознаками. Для класифікації тісноти зв'язку використовується шкала Чеддока.
Для оцінки надійності виявленого зв'язку порівнюється множинний коефіцієнт кореляції з лінійними кореляційними коефіцієнтами кореляції між результатом і факторними ознаками, включеними в модель. Зв'язок визнається надійним, якщо
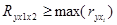
Завершуючим етапом множинної кореляції є інтерпретація параметрів побудованої кореляційної моделі. Чим більше величина цих параметрів ( коефіцієнтів регресії), тим значніше вплив даних чинників на результат. Важливе значення мають знак перед коефіцієнтами регресії. Знак “+”свідчить про зростання результату при збільшенні факторної ознаки, знак “-” - про зменшення результату при зростанні факторного.
Опишемо зв'язок між урожайністю льоноволокну (факторна змінна Х1), витратами праці на 1 центнер льонотрести (факторна змінна Х2) та якістю льнотрести (результуюча змінна У). Для побудови моделі лінійної регресії скористаємось матричною формулою
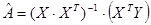
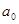 |
0,29041 |
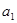 |
0,065151 |
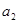 |
-0,00789 |
Таким чином, економетрична модель має вигляд:
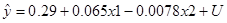
| Y |
X1 |
X2 |
Y^ |
U |
| 0,5 |
4,3 |
2,33 |
0,551326 |
-0,05133 |
| 0,5 |
5,7 |
4,74 |
0,623528 |
-0,12353 |
| 0,5 |
6,6 |
3,33 |
0,693026 |
-0,19303 |
| 0,54 |
9,8 |
2,66 |
0,906252 |
-0,36625 |
| 0,56 |
3,7 |
4,51 |
0,495322 |
0,064678 |
| 0,56 |
5,9 |
6,67 |
0,621474 |
-0,06147 |
| 0,58 |
5,6 |
3,59 |
0,625998 |
-0,046 |
| 0,6 |
3,7 |
1,43 |
0,519346 |
0,080654 |
| 0,6 |
7,6 |
5,4 |
0,74188 |
-0,14188 |
| 0,63 |
5,1 |
7,85 |
0,56027 |
0,06973 |
| 0,64 |
3,7 |
3,94 |
0,499768 |
0,140232 |
| 0,65 |
5,2 |
5,52 |
0,584944 |
0,065056 |
| 0,65 |
8,7 |
3,28 |
0,829916 |
-0,17992 |
| 0,7 |
7,2 |
5,75 |
0,71315 |
-0,01315 |
| 0,72 |
6 |
6,63 |
0,628286 |
0,091714 |
| 0,72 |
10,9 |
6,68 |
0,946396 |
-0,2264 |
| 0,77 |
11,8 |
3,24 |
1,031728 |
-0,26173 |
| 0,78 |
6,3 |
2,32 |
0,681404 |
0,098596 |
| 0,85 |
7,8 |
6,9 |
0,74318 |
0,10682 |
| 0,88 |
7,5 |
7,25 |
0,72095 |
0,15905 |
| 0,88 |
12,1 |
10,38 |
0,995536 |
-0,11554 |
| 0,97 |
9,8 |
4,05 |
0,89541 |
0,07459 |
| 1,23 |
10,7 |
3,97 |
0,954534 |
0,275466 |
| 1,37 |
13,1 |
3,81 |
1,111782 |
0,258218 |
| 1,46 |
13,4 |
3,23 |
1,135806 |
0,324194 |
1) розрахуємо коефіцієнт детермінації: 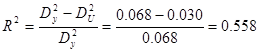 . Цей показник показує, що вариація залежної змінної залежить від варіації пояснюючих змінних на 55,8% . Цей показник показує, що вариація залежної змінної залежить від варіації пояснюючих змінних на 55,8%
2) розрахуємо коефіцієнт множинної кореляції:
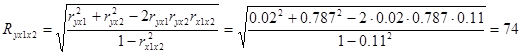
Бачимо, що зв'язок між пояснюючими та залежною змінними є тісним.
3) Статистична значущість звязку, отриманого на основі економетричної моделі, оцінимо за критерієм Фішера.
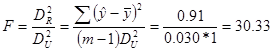
Розрахуємо критичне значення критерію Фішера при рівні значущості 0,05 та ступені свободи 2 та 25:
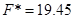
Оскільки фактичне значення критерія Фішера є більшим за критичне, то економетрична модель є достовірною.
4) Розрахуємо критерій Стьюдента для оцінки статистичної значущості кожної оцінки параметрів економетричної моделі: 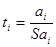
Критичне значення критерію Стьюдента при рівні значущості 0,05 та ступеню свободи 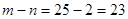 дорівнює дорівнює 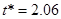 . .
Таким чином, параметри 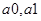 є статистично достовірними, а параметр є статистично достовірними, а параметр 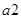 - статистично недостовірним. - статистично недостовірним.
У статистичній практиці можуть зустрічатися такі випадки, коли якості факторних і результативних ознак не можуть бути виражені чисельно. Тому для вимірювання тісноти залежності необхідно використовувати інші показники. Для цих цілей використовуються так звані непараметричні методи.
Найбільше розповсюдження мають рангові коефіцієнти кореляції, в основу яких покладений принцип нумерації значень статистичного ряду. При використанні коефіцієнтів кореляції рангів корреліруются не самі значення показників х і у, а тільки номери їх місць, які вони займають в кожному ряду значень. В цьому випадку номер кожної окремої одиниці буде її рангом.
Коефіцієнти кореляції, засновані на використанні ранжируваного методу, були запропоновані К. Спірменом і м. Кенделом.
Коефіцієнт кореляції рангів Спірмена (р) заснований на розгляді різниці рангів значень результативної і факторної ознак і може бути розрахований по формулі
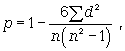
де в = Nx - Ny, тобто різниця рангів кожної пари значень х і у; n - число спостережень.
Ранговий коефіцієнт кореляції Кендела можна визначити по формулі
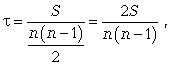
де S = P + Q.
До непараметричних методів дослідження можна віднести коефіцієнт асоціації Кас і коефіцієнт контінгенциі Ккон, які використовуються, якщо, наприклад, необхідно досліджувати тісноту залежності між якісними ознаками, кожен з яких представлений у вигляді альтернативних ознак.
Якщо необхідно оцінити тісноту зв'язку між альтернативними ознаками, які можуть приймати будь-яке число варіантів значень, застосовується коефіцієнт взаємної зв'язаності Пірсону (КП ).
Нарешті, слід згадати коефіцієнт Фехнера, що характеризує елементарний ступінь тісноти зв'язку, який доцільно використовувати для встановлення факту наявності зв'язку, коли існує невеликий об'єм початкової інформації. Даний коефіцієнт визначається по формулі
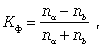
де na - кількість збігів знаків відхилень індивідуальних величин від їх середньої арифметичної; nb - відповідно кількість неспівпадань.
Коефіцієнт Фехнера може змінюватися в межах від -1 до 1.
Розрахуємо коефіцієнт рангової кореляції між показниками «Урожайність льоноволокну» та «Якість льонотрести»:
Точка
|
Столбец1 |
Ранг |
Процент |
Точка |
Столбец2 |
Ранг |
Процент |
| 25 |
13,4 |
1 |
100,00% |
25 |
1,46 |
1 |
100,00% |
| 23 |
13,1 |
2 |
95,80% |
23 |
1,37 |
2 |
95,80% |
| 22 |
12,1 |
3 |
91,60% |
3 |
1,23 |
3 |
91,60% |
| 4 |
11,8 |
4 |
87,50% |
15 |
0,97 |
4 |
87,50% |
| 21 |
10,9 |
5 |
83,30% |
16 |
0,88 |
5 |
79,10% |
| 3 |
10,7 |
6 |
79,10% |
22 |
0,88 |
5 |
79,10% |
| 7 |
9,8 |
7 |
70,80% |
1 |
0,85 |
7 |
75,00% |
| 15 |
9,8 |
7 |
70,80% |
20 |
0,78 |
8 |
70,80% |
| 9 |
8,7 |
9 |
66,60% |
4 |
0,77 |
9 |
66,60% |
| 1 |
7,8 |
10 |
62,50% |
13 |
0,72 |
10 |
58,30% |
| 19 |
7,6 |
11 |
58,30% |
21 |
0,72 |
10 |
58,30% |
| 16 |
7,5 |
12 |
54,10% |
11 |
0,7 |
12 |
54,10% |
| 11 |
7,2 |
13 |
50,00% |
9 |
0,65 |
13 |
45,80% |
| 2 |
6,6 |
14 |
45,80% |
17 |
0,65 |
13 |
45,80% |
| 20 |
6,3 |
15 |
41,60% |
12 |
0,64 |
15 |
41,60% |
| 13 |
6 |
16 |
37,50% |
10 |
0,63 |
16 |
37,50% |
| 5 |
5,9 |
17 |
33,30% |
6 |
0,6 |
17 |
29,10% |
| 14 |
5,7 |
18 |
29,10% |
19 |
0,6 |
17 |
29,10% |
| 8 |
5,6 |
19 |
25,00% |
8 |
0,58 |
19 |
25,00% |
| 17 |
5,2 |
20 |
20,80% |
5 |
0,56 |
20 |
16,60% |
| 10 |
5,1 |
21 |
16,60% |
24 |
0,56 |
20 |
16,60% |
| 18 |
4,3 |
22 |
12,50% |
7 |
0,54 |
22 |
12,50% |
| 6 |
3,7 |
23 |
0,00% |
2 |
0,5 |
23 |
0,00% |
| 12 |
3,7 |
23 |
0,00% |
14 |
0,5 |
23 |
0,00% |
| 24 |
3,7 |
23 |
0,00% |
18 |
0,5 |
23 |
0,00% |
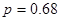 . .
Це значення коефіцієнту Спірмена свідчить про наявність помірної тісноти зв’язку між показниками «Урожайність льоноволокну» та «Якість льонотрести»
Розрахуємо коефіцієнт рангової кореляції між показниками «Урожайність льоноволокну» та «Витрати праці на 1 центнер льонотрести»:
| Точка |
Столбец1 |
Ранг |
Процент |
Точка |
Столбец2 |
Ранг |
Процент |
| 25 |
13,4 |
1 |
100,00% |
22 |
10,38 |
1 |
100,00% |
| 23 |
13,1 |
2 |
95,80% |
10 |
7,85 |
2 |
95,80% |
| 22 |
12,1 |
3 |
91,60% |
16 |
7,25 |
3 |
91,60% |
| 4 |
11,8 |
4 |
87,50% |
1 |
6,9 |
4 |
87,50% |
| 21 |
10,9 |
5 |
83,30% |
21 |
6,68 |
5 |
83,30% |
| 3 |
10,7 |
6 |
79,10% |
5 |
6,67 |
6 |
79,10% |
| 7 |
9,8 |
7 |
70,80% |
13 |
6,63 |
7 |
75,00% |
| 15 |
9,8 |
7 |
70,80% |
11 |
5,75 |
8 |
70,80% |
| 9 |
8,7 |
9 |
66,60% |
17 |
5,52 |
9 |
66,60% |
| 1 |
7,8 |
10 |
62,50% |
19 |
5,4 |
10 |
62,50% |
| 19 |
7,6 |
11 |
58,30% |
14 |
4,74 |
11 |
58,30% |
| 16 |
7,5 |
12 |
54,10% |
24 |
4,51 |
12 |
54,10% |
| 11 |
7,2 |
13 |
50,00% |
15 |
4,05 |
13 |
50,00% |
| 2 |
6,6 |
14 |
45,80% |
3 |
3,97 |
14 |
45,80% |
| 20 |
6,3 |
15 |
41,60% |
12 |
3,94 |
15 |
41,60% |
| 13 |
6 |
16 |
37,50% |
23 |
3,81 |
16 |
37,50% |
| 5 |
5,9 |
17 |
33,30% |
8 |
3,59 |
17 |
33,30% |
| 14 |
5,7 |
18 |
29,10% |
2 |
3,33 |
18 |
29,10% |
| 8 |
5,6 |
19 |
25,00% |
9 |
3,28 |
19 |
25,00% |
| 17 |
5,2 |
20 |
20,80% |
4 |
3,24 |
20 |
20,80% |
| 10 |
5,1 |
21 |
16,60% |
25 |
3,23 |
21 |
16,60% |
| 18 |
4,3 |
22 |
12,50% |
7 |
2,66 |
22 |
12,50% |
| 6 |
3,7 |
23 |
0,00% |
18 |
2,33 |
23 |
8,30% |
| 12 |
3,7 |
23 |
0,00% |
20 |
2,32 |
24 |
4,10% |
| 24 |
3,7 |
23 |
0,00% |
6 |
1,43 |
25 |
0,00% |
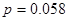
Це значення коефіцієнту Спірмена свідчить про наявність слабкої тісноти зв’язку між показниками «Урожайність льоноволокну» та «Якість льонотрести»
Розрахуємо коефіцієнт рангової кореляції між показниками «Якість льонотрести» та «Витрати праці на 1 центнер льонотрести»:
| Точка |
Столбец1 |
Ранг |
Процент |
Точка |
Столбец2 |
Ранг |
Процент |
| 25 |
1,46 |
1 |
100,00% |
22 |
10,38 |
1 |
100,00% |
| 23 |
1,37 |
2 |
95,80% |
10 |
7,85 |
2 |
95,80% |
| 3 |
1,23 |
3 |
91,60% |
16 |
7,25 |
3 |
91,60% |
| 15 |
0,97 |
4 |
87,50% |
1 |
6,9 |
4 |
87,50% |
| 16 |
0,88 |
5 |
79,10% |
21 |
6,68 |
5 |
83,30% |
| 22 |
0,88 |
5 |
79,10% |
5 |
6,67 |
6 |
79,10% |
| 1 |
0,85 |
7 |
75,00% |
13 |
6,63 |
7 |
75,00% |
| 20 |
0,78 |
8 |
70,80% |
11 |
5,75 |
8 |
70,80% |
| 4 |
0,77 |
9 |
66,60% |
17 |
5,52 |
9 |
66,60% |
| 13 |
0,72 |
10 |
58,30% |
19 |
5,4 |
10 |
62,50% |
| 21 |
0,72 |
10 |
58,30% |
14 |
4,74 |
11 |
58,30% |
| 11 |
0,7 |
12 |
54,10% |
24 |
4,51 |
12 |
54,10% |
| 9 |
0,65 |
13 |
45,80% |
15 |
4,05 |
13 |
50,00% |
| 17 |
0,65 |
13 |
45,80% |
3 |
3,97 |
14 |
45,80% |
| 12 |
0,64 |
15 |
41,60% |
12 |
3,94 |
15 |
41,60% |
| 10 |
0,63 |
16 |
37,50% |
23 |
3,81 |
16 |
37,50% |
| 6 |
0,6 |
17 |
29,10% |
8 |
3,59 |
17 |
33,30% |
| 19 |
0,6 |
17 |
29,10% |
2 |
3,33 |
18 |
29,10% |
| 8 |
0,58 |
19 |
25,00% |
9 |
3,28 |
19 |
25,00% |
| 5 |
0,56 |
20 |
16,60% |
4 |
3,24 |
20 |
20,80% |
| 24 |
0,56 |
20 |
16,60% |
25 |
3,23 |
21 |
16,60% |
| 7 |
0,54 |
22 |
12,50% |
7 |
2,66 |
22 |
12,50% |
| 2 |
0,5 |
23 |
0,00% |
18 |
2,33 |
23 |
8,30% |
| 14 |
0,5 |
23 |
0,00% |
20 |
2,32 |
24 |
4,10% |
| 18 |
0,5 |
23 |
0,00% |
6 |
1,43 |
25 |
0,00% |
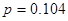
Це значення коефіцієнту Спірмена свідчить про наявність слабкої тісноти зв’язку між показниками «Якість льонотрести» та «Витрати праці на 1 центнер льонотрести»
Висновки
В результаті виконання курсової роботи мною було досліджено надані дані, які характеризують виробництво льону за такими ознаками:
· «Урожайність льоноволокну»
· «Якість льонотрести»
· «Витрати праці на 1 центнер льонотрести»
У результаті аналіза побудованих варіаційних рядів було виявлено, що існує залежність між урожайністю льоноволокну та якістю льонотрести. Залежності між витратами праці на 1 центнер льонотрести та іншими досліджуваними параметрами в результаті аналіза варіаційних рядів не виявлено.
Проведений кореляційний аналіз підтвердив попередні висновки. Обчислені коефіцієнти парної кореляції свідчать про те, що існує сильна пряма залежність між значеннями показників «Урожайність льоноволокну» та «Витрати праці на 1 центнер льонотрести». Залежність між значеннями показників «Урожайність льоноволокну» та «Витрати праці на 1 центнер льонотрести» слабка, а залежність між значеннями показників «Витрати праці на 1 центнер льонотрести» та «Якість льонотрести» практично відсутня.
В результаті аналізу зв'язку між урожайністю льоноволокну (факторна змінна Х1), витратами праці на 1 центнер льонотрести (факторна змінна Х2) та якістю льнотрести (результуюча змінна У) було створено відповідну економетричну модель. Розраховане значення коефіцієнту множинної кореляції свідчить про наявність тісного зв’язку між факторними та результуючою змінними. Однак оцінка статистичної значущості параметрів економетричної моделі дає підстави стверджувати, що змінна Х2 «Витрати праці на 1 центнер льонотрести» не є статистично значимої в даній економетричній моделі.
1. Єріна А. М. Статистичне моделювання та прогнозування: Навч. посіб. — К.: Вид-во КНЕУ, 2001.
2. Статистика: Підручник / С. С. Герасименко, А. В. Головач, М. Єріна та ін. — 2-ге вид., перероб. і доп. — К.: Вид-во КНЕУ, 2000.
3. Статистика // Под редакцией И. И. Елисеевой. – М.: Вісшее образование, 2006 г.
4. Статистика // Редактор М. Р. Ефимова. - Инфра-М, 2004 г.
5. Кулинич Е. И. Эконометрия. – М.: Финансы и статистика, 1999 г.
6. Э. Фёрстер, Б. Рёнц. Методы корреляционного и регрессионного анализа. - Финансы и статистика, 1983 г.
7. В. И. Суслов, Н. М. Ибрагимов, Л. П. Талышева, А. А. Цыплаков. Эконометрия. - Новосибирский государственный университет, 2005 г.
8. Н. В. Артамонов. Теория вероятностей и математическая статистика. Углубленный курс. - МГИМО-Университет, 2008 г.
9. А. И. Кобзар. Прикладная математическая статистика. - ФИЗМАТЛИТ, 2006 г.
10. Г. Крамер. Математические методы статистики. - Регулярная и хаотическая динамика, 2003 г.
|