СОДЕРЖАНИЕ
Введение………………………....................................................................3
1 Процессоры……………………………………………………………....4
1.1 Последовательные процессоры……………………………………….5
1.2 Суперскалярная архитекртура……………………………………..…7
1.3 Параллельная архитектура………………………………………...…10
1.3.1 Суперкомпьютер……………………………………………………10
1.3.3 Классификация параллельных вычислительных схем………..….14
1.4 Конвейерная архитектура…………………………………………….19
1.5 История развития процессоров……………………………………....20
1.6 Современные технологии изготовления………………………….....21
Заключение………………………………………………………………..24
Список литературы………………………………..……………………...25
ВВЕДЕНИЕ
Центральным процессором (CPU — англ.céntralprócessing únit) —является часть аппаратного обеспечениякомпьютера или программируемого логического контроллера, отвечающая за выполнение арифметических операций, заданных программами операционной системы, и координирующий работу всех устройств компьютера. Начало применения термина и его аббревиатуры по отношению к компьютерным системам было положено в 60-х годахXX века. Устройство, архитектура и реализация процессоров с тех пор неоднократно менялись, однако их основные исполняемые функции остались теми же, что и прежде.
Объектом изучения данной курсовой работы являются различные архитектуры процессоров.
В качестве предмета курсовой работы рассматривается последовательные и параллельные процессоры.
Цель данной работы заключается в изучении различных видов архитектур процессоров.
Для этого необходимо выполнить следующие задачи:
- подобрать и изучить литературу по рассматриваемой теме;
- рассмотреть принципы функционирования последовательных и параллельных процессоров;
- выявить их принципиальные различия;
- оценить их с точки зрения применения на практике;
-сделать выводы по работе.
1 Процессоры
Современные ЦП, выполняемые в виде отдельных микросхем (чипов), реализующих все особенности, присущие данного рода устройствам, называют микропроцессорами. С середины 1980-х последние практически вытеснили прочие виды ЦП, вследствие чего термин стал всё чаще и чаще восприниматься как обыкновенный синоним слова «микропроцессор». Тем не менее, это не так: центральные процессорные устройства некоторых суперкомпьютеров даже сегодня представляют собой сложные комплексы больших (БИС) и сверхбольших (СБИС) интегральных схем.
Изначально термин Центральное процессорное устройство описывал специализированный класс логических машин, предназначенных для выполнения сложных компьютерных программ. Вследствие довольно точного соответствия этого назначения функциям существовавших в то время компьютерных процессоров, он естественным образом был перенесён на сами компьютеры. Начало применения термина и его аббревиатуры по отношению к компьютерным системам было положено в 60-х годахXX века. Устройство, архитектура и реализация процессоров с тех пор неоднократно менялись, однако их основные исполняемые функции остались теми же, что и прежде.
Ранние ЦП создавались в виде уникальных составных частей для уникальных, и даже единственных в своём роде, компьютерных систем. Позднее от дорогостоящего способа разработки процессоров, предназначенных для выполнения одной единственной или нескольких узкоспециализированных программ, производители компьютеров перешли к серийному изготовлению типовых классов многоцелевых процессорных устройств. Тенденция к стандартизации компьютерных комплектующих зародилась в эпоху бурного развития полупроводниковых элементов, мейнфреймов и миникомпьютеров, а с появлением интегральных схем она стала ещё более популярной. Создание микросхем позволило ещё больше увеличить сложность ЦП с одновременным уменьшением их физических размеров. Стандартизация и миниатюризация процессоров привели к глубокому проникновению основанных на них цифровых устройств в повседневную жизнь человека. Современные процессоры можно найти не только в таких высокотехнологичных устройствах, как компьютеры, но и в автомобилях, калькуляторах, мобильных телефонах и даже в детских игрушках. Чаще всего они представлены микроконтроллерами, где помимо вычислительного устройства на кристалле расположены дополнительные компоненты (интерфейсы, порты ввода/вывода, таймеры, и др.). Современные вычислительные возможности микроконтроллера сравнимы с процессорами персональных ЭВМ десятилетней давности, а чаще даже значительно превосходят их показатели.
1.1 Последовательные процессоры.
1.2
Большинство современных процессоров для персональных компьютеров в общем основаны на той или иной версии циклического процесса последовательной обработки информации, изобретённого Джоном фон Нейманом.

Д. фон Нейман придумал схему постройки компьютера в 1946 году.
Важнейшие этапы этого процесса приведены ниже. В различных архитектурах и для различных команд могут потребоваться дополнительные этапы. Например, для арифметических команд могут потребоваться дополнительные обращения к памяти, во время которых производится считывание операндов и запись результатов. Отличительной особенностью архитектуры фон Неймана является то, что инструкции и данные хранятся в одной и той же памяти.
Этапы цикла выполнения:
1. Процессор выставляет число, хранящееся в регистресчётчика команд, на шину адреса, и отдаёт памяти команду чтения;
2. Выставленное число является для памяти адресом; память, получив адрес и команду чтения, выставляет содержимое, хранящееся по этому адресу, на шину данных, и сообщает о готовности;
3. Процессор получает число с шины данных, интерпретирует его как команду (машинную инструкцию) из своей системы команд и исполняет её;
4. Если последняя команда не является командой перехода, процессор увеличивает на единицу (в предположении, что длина каждой команды равна единице) число, хранящееся в счётчике команд; в результате там образуется адрес следующей команды;
5. Снова выполняется п. 1.
Данный цикл выполняется неизменно, и именно он называется процессом (откуда и произошло название устройства).
Во время процесса процессор считывает последовательность команд, содержащихся в памяти, и исполняет их. Такая последовательность команд называется программой и представляет алгоритм полезной работы процессора. Очерёдность считывания команд изменяется в случае, если процессор считывает команду перехода — тогда адрес следующей команды может оказаться другим. Другим примером изменения процесса может служить случай получения команды останова или переключение в режим обработки аппаратного прерывания.
Команды центрального процессора являются самым нижним уровнем управления компьютером, поэтому выполнение каждой команды неизбежно и безусловно. Не производится никакой проверки на допустимость выполняемых действий, в частности, не проверяется возможная потеря ценных данных. Чтобы компьютер выполнял только допустимые действия, команды должны быть соответствующим образом организованы в виде необходимой программы.
Скорость перехода от одного этапа цикла к другому определяется тактовым генератором. Тактовый генератор вырабатывает импульсы, служащие ритмом для центрального процессора. Частота тактовых импульсов называется тактовой частотой.
В середине 40-х проект компьютера, хранящего свои программы в общей памяти был разработан в Муровской школе электрических разработок (англ.The Moore School of Electrical Engineering) вУниверситетештатаПенсильвания (англ.TheUniversityofPennsylvania). Подход, описанный в этом документе, стал известен как архитектура фон Неймана, по имени единственного из названных авторов проекта Джона фон Неймана, хотя на самом деле авторство проекта было коллективным. Архитектура фон Неймана решала проблемы, свойственные компьютеру «Эниак», который создавался в то время, за счёт хранения программы компьютера в его собственной памяти. Информация о проекте стала доступна другим исследователям вскоре после того, как в 1946 году было объявлено о создании «Эниака». По плану предполагалось осуществить проект силами Муровской школы в машине «EDVAC», однако до 1953 года «EDVAC» не был запущен из-за технических трудностей в создании надёжной компьютерной памяти. Другие научно-исследовательские институты, получившие копии проекта, сумели решить эти проблемы гораздо раньше группы разработчиков из Муровской школы и реализовали их в собственных компьютерных системах. Первыми 5 компьютерами, в которых были реализованы основные особенности архитектуры фон Неймана, были:
· «Манчестерский Марк I». Прототип («Манчестерское дитя») Университет Манчестера (англ.The University of Manchester) Великобритания, 21 июня1948 года;
· «EDSAC». Кембриджский университет (англ.TheCambridgeUniversity). Великобритания, 6 мая1949 года;
· «BINAC». США, апрель или август 1949 года;
· «CSIR Mk 1». Австралия, ноябрь 1949 года;
· «SEAC». США, 9 мая1950 года.
1.2 Суперскалярная архитектура
Способность выполнения нескольких машинных инструкций за один такт процессора. Появление этой технологии привело к существенному увеличению производительности.
CISC-процессоры
Complex Instruction Set Computer — вычисления со сложным набором команд. Процессорная архитектура, основанная на усложнённом наборе команд. Типичными представителями CISC является семейство микропроцессоров Intel x86 (хотя уже много лет эти процессоры являются CISC только по внешней системе команд).
RISC-процессоры
Reduced Instruction Set Computing (technology) — вычисления с сокращённым набором команд. Архитектура процессоров, построенная на основе сокращённого набора команд. Характеризуется наличием команд фиксированной длины, большого количества регистров, операций типа регистр-регистр, а также отсутствием косвенной адресации. Концепция RISC разработана Джоном Коком (John Cocke) из IBM Research, название придумано Дэвидом Паттерсоном (David Patterson).
Самая распространённая реализация этой архитектуры представлена процессорами серии PowerPC, включая G3, G4 и G5. Довольно известная реализация данной архитектуры — процессоры серий MIPS и Alpha.
MISC-процессоры
Minimum Instruction Set Computing — вычисления с минимальным набором команд. Дальнейшее развитие идей команды Чака Мура, который полагает, что принцип простоты, изначальный для RISC процессоров, слишком быстро отошёл на задний план. В пылу борьбы за максимальное быстродействие, RISC догнал и перегнал многие CISC процессоры по сложности. Архитектура MISC строится на стековой вычислительной модели с ограниченным числом команд (примерно 20-30 команд).
Многоядерные процессоры
Содержат несколько процессорных ядер в одном корпусе (на одном или нескольких кристаллах).
Процессоры, предназначенные для работы одной копии операционной системы на нескольких ядрах, представляют собой высокоинтегрированную реализацию системы «Мультипроцессор».
На данный момент массово доступны процессоры с двумя ядрами, в частности Intel Core 2 Duo на 65 нм ядре Conroe (позднее на 45 нм ядре Wolfdale) и Athlon64X2 на базе микроархитектуры K8. В ноябре 2006 года вышел первый четырёхъядерный процессор Intel Core 2 Quad на ядре Kentsfield, представляющий собой сборку из двух кристаллов Conroe в одном корпусе.
Двухядерность поцессоров включает такие понятия, как наличие логических и физических ядер: например двухядерный процессор Intel Core Duo состоит из одного физического ядра, которое в свою очередь разделено на два логических. Процессор Intel Core 2 Duo состоит из двух физических ядер, что существенно влияет на скорость его работы.
10 сентября2007 года были выпущены в продажу нативные (в виде одного кристалла) четырёхьядерные процессоры для серверов AMD Quad-Core Opteron, имевшие в процессе разработки кодовое название AMD Opteron Barсelona. 19 ноября2007 вышел в продажу четырёхьядерный процессор для домашних компьютеров AMD Quad-Core Phenom. Эти процесоры реализуют новую микроархитектуру K8L (K10).
27 сентября2006 года Intel продемонстрировала прототип 80-ядерного процессора. Предполагается, что массовое производство подобных процессоров станет возможно не раньше перехода на 32-нанометровый техпроцесс, а это в свою очередь ожидается к 2010 году.
Кэширование — это использование дополнительной быстродействующей памяти (кэш-памяти) для хранения копий блоков информации из основной (оперативной) памяти, вероятность обращения к которым в ближайшее время велика.
Различают кэши 1-, 2- и 3-го уровней. Кэш 1-го уровня имеет наименьшую латентность (время доступа), но малый размер, кроме того кэши первого уровня часто делаются многопортовыми. Так, процессоры AMD K8 умели производить 64 бит запись+64 бит чтение либо два 64-бит чтения за такт, процессоры Intel Core могут производить 128 бит запись+128 бит чтение за такт. Кэш 2-го уровня обычно имеет значительно большие латентности доступа, но его можно сделать значительно больше по размеру. Кэш 3-го уровня самый большой по объёму и довольно медленный, но всё же он гораздо быстрее, чем оперативная память.
1.3 Параллельная архитектура
Архитектура фон Неймана обладает тем недостатком, что она последовательная. Какой бы огромный массив данных ни требовалось обработать, каждый его байт должен будет пройти через центральный процессор, даже если над всеми байтами требуется провести одну и ту же операцию. Этот эффект называется узким горлышком фон Неймана.
Для преодоления этого недостатка предлагались и предлагаются архитектуры процессоров, которые называются параллельными. Параллельные процессоры используются в суперкомпьютерах.
Возможными вариантами параллельной архитектуры могут служить (по классификации Флинна):
· SISD — один поток команд, один поток данных;
· SIMD — один поток команд, много потоков данных;
· MISD — много потоков команд, один поток данных;
· MIMD — много потоков команд, много потоков данных.
Параллельно развиваются микропроцессоры, взявшие за основу стековую вычислительную модель.
1.3.1 Суперкомпьютер
Определение понятия суперкомпью́тер (англ.supercomputer) не раз было предметом многочисленных споров и дискуссий.
Чаще всего авторство термина приписывается Джорджу Мишелю и Сиднею Фернбачу, в конце 60-х годов XX века работавшим в Ливерморской национальной лаборатории и компании Control Data Corporation. Тем не менее, известен тот факт, что ещё в 1920 году газета New York World рассказывала о «супервычислениях», выполняемых при помощи табулятораIBM, собранного по заказу Колумбийского университета.
В общеупотребительный лексикон термин «суперкомпьютер» вошёл благодаря распространённости компьютерных системСеймура Крея, таких как, Control Data 6600, Control Data 7600, Cray-1, Cray-2, Cray-3 и Cray-4. Сеймур Крей разрабатывал вычислительные машины, которые по сути становились основными вычислительными средствами правительственных, промышленных и академических научно-технических проектов США с середины 60-х годов до 1996 года. Не случайно в то время одним из популярных определений суперкомпьютера было следующее: — «любой компьютер, который создал Сеймур Крей». Сам Крей никогда не называл свои детища суперкомпьютерами, предпочитая использовать вместо этого обычное название «компьютер».
Компьютерные системы Крея удерживались на вершине рынка в течение 5 лет с 1985 по 1990 годы. 80-е годы XX века охарактеризовались появлением множества небольших конкурирующих компаний, занимающихся созданием высокопроизводительных компьютеров, однако к середине 90-х большинство из них оставили эту сферу деятельности, что даже заставило обозревателей заговорить о «крахе рынка суперкомпьютеров». На сегодняшний день суперкомпьютеры являются уникальными системами, создаваемыми «традиционными» игроками компьютерного рынка, такими как IBM, Hewlett-Packard, NEC и другими, которые приобрели множество ранних компаний, вместе с их опытом и технологиями. Компания Cray Inc. по прежнему занимает достойное место в ряду производителей суперкомпьютерной техники.
Из-за большой гибкости самого термина до сих пор распространены довольно нечёткие представления о понятии «суперкомпьютер». Шутливая классификация Гордона Белла и Дона Нельсона, разработанная приблизительно в 1989 году, предлагала считать суперкомпьютером любой компьютер, весящий более тонны. Современные суперкомпьютеры действительно весят более 1 тонны, однако далеко не каждый тяжёлый компьютер достоин чести считаться суперкомпьютером. В общем случае, суперкомпьютер — это компьютер значительно более мощный, чем доступные для большинства пользователей машины. При этом, скорость технического прогресса сегодня такова, что нынешний лидер легко может стать завтрашним аутсайдером.
Архитектура также не может считаться признаком принадлежности к классу суперкомпьютеров. Ранние компьютеры CDC были обычными машинами, всего лишь оснащёнными быстрыми для своего времени скалярными процессорами, скорость работы которых была в несколько десятков раз выше, чем у компьютеров, предлагаемых другими компаниями.
Большинство суперкомпьютеров 70-х оснащались векторными процессорами, а к началу и середине 80-х небольшое число (от 4 до 16) параллельно работающих векторных процессоров практически стало стандартным суперкомпьютерным решением. Конец 80-х и начало 90-х годов охарактеризовались сменой магистрального направления развития суперкомпьютеров от векторно-конвейерной обработки к большому и сверхбольшому числу параллельно соединённых скалярных процессоров.
Массивно-параллельные системы стали объединять в себе сотни и даже тысячи отдельных процессорных элементов, причём ими могли служить не только специально разработанные, но и общеизвестные и доступные в свободной продаже процессоры. Большинство массивно-параллельных компьютеров создавалось на основе мощных процессоров с архитектурой RISC, наподобие PowerPC или PA-RISC.
В конце 90-х годов высокая стоимость специализированных суперкомпьютерных решений и нарастающая потребность разных слоёв общества в доступных вычислительных ресурсах привели к широкому распространению компьютерных кластеров. Эти системы характеризует использование отдельных узлов на основе дешёвых и широко доступных компьютерных комплектующих для серверов и персональных компьютеров и объединённых при помощи мощных коммуникационных систем и специализированных программно-аппаратных решений. Несмотря на кажущуюся простоту, кластеры довольно быстро заняли достаточно большой сегмент суперкомпьютерного рынка, обеспечивая высочайшую производительность при минимальной стоимости решений.
В настоящее время суперкомпьютерами принято называть компьютеры с огромной вычислительной мощностью («числодробилки» или «числогрызы»). Такие машины используются для работы с приложениями, требующими наиболее интенсивных вычислений (например, прогнозирование погодно-климатических условий, моделирование ядерных испытаний и т. п.), что в том числе отличает их от серверов и мэйнфреймов (англ.mainframe) — компьютеров с высокой общей производительностью, призванных решать типовые задачи (например, обслуживание больших баз данных или одновременная работа с множеством пользователей).
Иногда суперкомпьютеры используются для работы с одним-единственным приложением, использующим всю память и все процессоры системы; в других случаях они обеспечивают выполнение большого числа разнообразных приложений.
Большинство суперкомпьютеров построены на двоичных триггерах и работают в двоичной системе счисления, в двоичной логике по двоичным алгоритмам. Троичные компьютеры, которые строятся на троичных триггерах, работают в троичной системе счисления, в троичной логике по троичным алгоритмам и, при одинаковом числе инверторов, намного превосходят двоичные компьютеры по ёмкости памяти, производительности, быстродействию.
Наиболее распространёнными программными средствами суперкомпьютеров, также как и параллельных или распределённых компьютерных систем являются интерфейсы программирования приложений (API) на основе MPI и PVM, и решения на базе открытого программного обеспечения, наподобие Beowulf и openMosix, позволяющего создавать виртуальные суперкомпьютеры даже на базе обыкновенных рабочих станций и персональных компьютеров. Для быстрого подключения новых вычислительных узлов в состав узкоспециализированных кластеров применяются технологии наподобие ZeroConf. Примером может служить реализация рендеринга в программном обеспечении Shake, распространяемом компанией Apple. Для объединения ресурсов компьютеров, выполняющих программу Shake, достаточно разместить их в общем сегменте локальной вычислительной сети.
В настоящее время границы между суперкомпьютерным и общеупотребимым программным обеспечением сильно размыты и продолжают размываться ещё более вместе с проникновением технологий параллелизации и многоядерности в процессорные устройства персональных компьютеров и рабочих станций. Исключительно суперкомпьютерным программным обеспечением сегодня можно назвать лишь специализированные программные средства для управления и мониторинга конкретных типов компьютеров, а также уникальные программные среды, создаваемые в вычислительных центрах под «собственные», уникальные конфигурации суперкомпьютерных систем.
1.3.2 Классификация параллельных вычислительных систем
Классификация параллельных архитектур по Флинну (M. Flynn)
| Классификация по Флинну |
Одиночный поток команд
(Single Instruction) |
Множество потоков команд
(Multiple Instruction) |
Одиночный поток данных
(Single Data) |
SISD |
MISD |
Множество потоков данных
(Multiple Data) |
SIMD |
MIMD |
· Вычислительная система с одним потоком команд и данных (однопроцессорнаяЭВМ — SISD, Single Instruction stream over a Single Data stream).
· Вычислительная система с общим потоком команд (SIMD, Single Instruction, Multiple Data — одиночный поток команд и множественный поток данных).
· Вычислительная система со множественным потоком команд и одиночным потоком данных (MISD, Multiple Instruction Single Data — конвейерная ЭВМ).
· Вычислительная система со множественным потоком команд и данных (MIMD, Multiple Instruction Multiple Data).
Типичными представителями SIMD являются векторные архитектуры. К классу MISD ряд исследователей относит конвейерные ЭВМ, однако это не нашло окончательного признания, поэтому можно считать, что реальных систем — представителей данного класса не существует. Класс MIMD включает в себя многопроцессорные системы, где процессоры обрабатывают множественные потоки данных. Отношение конкретных машин к конкретному классу сильно зависит от точки зрения исследователя. Так, конвейерные машины могут быть отнесены и к классу SISD (конвейер — единый процессор), и к классу SIMD (векторный поток данных с конвейерным процессором) и к классу MISD (множество процессоров конвейера обрабатывают один поток данных последовательно), и к классу MIMD — как выполнение последовательности различных команд (операций ступеней конвейера) на множественным скалярным потоком данных (вектором).
Существуют два типа машин (процессоров), выдающих несколько команд за один такт: суперскалярные машины и VLIW-машины. Суперскалярные машины могут выдавать на выполнение в каждом такте переменное число команд, и работа их конвейеров может планироваться как статически с помощью компилятора, так и с помощью аппаратных средств динамической оптимизации. Суперскалярные машины используют параллелизм на уровне команд путем посылки нескольких команд из обычного потока команд в несколько функциональных устройств. Дополнительно, чтобы снять ограничения последовательного выполнения команд, эти машины используют механизмы внеочередной выдачи и внеочередного завершения команд, прогнозирование переходов, кэши целевых адресов переходов и условное (по предположению) выполнение команд. В отличие от суперскалярных машин, VLIW-машины выдают на выполнение фиксированное количество команд, которые сформатированы либо как одна большая команда, либо как пакет команд фиксированного формата. Планирование работы VLIW-машины всегда осуществляется компилятором. В типичной суперскалярной машине аппаратура может осуществлять выдачу от одной до восьми команд в одном такте. Обычно эти команды должны быть независимыми и удовлетворять некоторым ограничениям, например таким, что в каждом такте не может выдаваться более одной команды обращения к памяти. Если какая-либо команда в потоке команд является логически зависимой или не удовлетворяет критериям выдачи, на выполнение будут выданы только команды, предшествующие данной. Поэтому скорость выдачи команд в суперскалярных машинах является переменной. Это отличает их от VLIW-машин, в которых полную ответственность за формирование пакета команд, которые могут выдаваться одновременно, несет компилятор, а аппаратура в динамике не принимает никаких решений относительно выдачи нескольких команд. Использование VLIW приводит в большинстве случаев к быстрому заполнению небольшого объема внутрикристальной памяти командами NOP (no operation), которые предназначены для тех устройств, которые не будут задействованы в текущем цикле. В существующих VLIW разработках был найден большой недостаток, который был устранен делением длинных слов на более мелкие, параллельно поступающие к каждому устройству. Обработка множества команд независимыми устройствами одновременно является главной особенностью суперскалярной процессорной архитектуры.
Классификация Хокни (R. Hockney)
Классификация машин MIMD-архитектуры :
· Переключаемые — с общей памятью и с распределённой памятью.
· Конвейерные.
· Сети — регулярные решётки, гиперкубы, иерархические структуры, изменяющие конфигурацию.
В класс конвейерных архитектур (по Хокни) попадают машины с одним конвейерным устройством обработки, работающим в режиме разделения времени для отдельных потоков. Машины, в которых каждый поток обрабатывается своим собственным устройством Хокни назвал переключаемыми. В класс переключаемых машин попадают машины, в которых возможна связь каждого процессора с каждым, реализуемая с помощью переключателей — машины с распределённой памятью. Если же память есть разделяемый ресурс, машина называется с общей памятью. При рассмотрении машин с сетевой структурой Хокни считал, что все они имеют распределённую память. Дальнейшую классификацию он проводил в соответствии с топологией сети.
Классификация Фенга (T. Feng)
В 1972 году Фенг предложил классифицировать вычислительные системы на основе двух простых характеристик. Первая — число n бит в машинном слове, обрабатываемых параллельно при выполнении машинных инструкций. Практически во всех современных компьютерах это число совпадает с длиной машинного слова. Вторая характеристика равна числу слов m, обрабатываемых одновременно данной ВС. Немного изменив терминологию, функционирование ВС можно представить как параллельную обработку n битовых слоёв, на каждом из которых независимо преобразуются m бит. Каждую вычислительную систему можно описать парой чисел (n, m). Произведение P = n x m определяет интегральную характеристику потенциала параллельности архитектуры, которую Фенг назвал максимальной степенью параллелизма ВС.
Параллельные системы также классифицируют по Хэндлеру (W. Handler), Шнайдеру (L.Snyder), Скилликорну (D. Skillicorn).
Классификация Скилликорна
Классификация Скилликорна (1989) была очередным расширением классификации Флинна. Архитектура любого компьютера в классификации Скилликорна рассматривается в виде комбинации четырёх абстрактных компонентов: процессоров команд (Instruction Processor — интерпретатор команд, может отсутствовать в системе), процессоров данных (Data Processor — преобразователь данных), иерархии памяти (Instruction Memory, Data Memory — память программ и данных), переключателей (связывающих процессоры и память). Переключатели бывают четырёх типов — «1-1» (связывают пару устройств), «n-n» (связывает каждое устройство из одного множества устройств с соответствующим ему устройством из другого множества, то есть фиксирует попарную связь), «n x n» (связь любого устройства одного множества с любым устройством другого множества). Классификация Скилликорна основывается на следующих восьми характеристиках:
· Количество процессоров команд IP
· Число ЗУ команд IM
· Тип переключателя между IP и IM
· Количество процессоров данных DP
· Число ЗУ данных DM
· Тип переключателя между DP и DM
· Тип переключателя между IP и DP
· Тип переключателя между DP и DP
1.4 Конвейерная архитектура
Конвейерная архитектура (pipelining) была введена в центральный процессор с целью повышения быстродействия. Обычно для выполнения каждой команды требуется осуществить некоторое количество однотипных операций, например: выборка команды из ОЗУ, дешифрация команды, адресация операнда в ОЗУ, выборка операнда из ОЗУ, выполнение команды, запись результата в ОЗУ. Каждую из этих операций сопоставляют одной ступени конвейера. Например, конвейер микропроцессора с архитектурой MIPS-I содержит четыре стадии:
· получение и декодирование инструкции (Fetch)
· адресация и выборка операнда из ОЗУ (Memory access)
· выполнение арифметических операций (Arithmetic Operation)
· сохранение результата операции (Store)
После освобождения k-й ступени конвейера она сразу приступает к работе над следующей командой. Если предположить, что каждая ступень конвейера тратит единицу времени на свою работу, то выполнение команды на конвейере длиной в n ступеней займёт n единиц времени, однако в самом оптимистичном случае результат выполнения каждой следующей команды будет получаться через каждую единицу времени.
Действительно, при отсутствии конвейера выполнение команды займёт n единиц времени (так как для выполнения команды по прежнему необходимо выполнять выборку, дешифрацию и т. д.), и для исполнения m команд понадобится 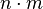 единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения m команд понадобится всего лишь n + m единиц времени. единиц времени; при использовании конвейера (в самом оптимистичном случае) для выполнения m команд понадобится всего лишь n + m единиц времени.
Факторы, снижающие эффективность конвейера:
1. простой конвейера, когда некоторые ступени не используются (напр., адресация и выборка операнда из ОЗУ не нужны, если команда работает с регистрами);
2. ожидание: если следующая команда использует результат предыдущей, то последняя не может начать выполняться до выполнения первой (это преодолевается при использовании внеочередного выполнения команд, out-of-order execution);
3. очистка конвейера при попадании в него команды перехода (эту проблему удаётся сгладить, используя предсказание переходов).
Некоторые современные процессоры имеют более 30 ступеней в конвейере, что увеличивает производительность процессора, однако приводит к большому времени простоя (например, в случае ошибки в предсказании условного перехода.)
1.4 История развития процессоров
Первым общедоступным микропроцессором был 4-разрядный Intel 4004. Его сменили 8-разрядный Intel 8080 и 16-разрядный 8086, заложившие основы архитектуры всех современных настольных процессоров. Но из-за распространённости 8-разрядных модулей памяти был выпущен 8088, клон 8086 с 8-разрядной шиной памяти. Затем проследовала его модификация 80186. В процессоре 80286 появился защищённый режим с 24-битной адресацией, позволявший использовать до 16 МБ памяти. Процессор Intel 80386 появился в 1985 году и привнёс улучшенный защищённый режим, 32-битную адресацию, позволившую использовать до 4 ГБ оперативной памяти и поддержку механизма виртуальной памяти. Эта линейка процессоров построена на регистровой вычислительной модели.
1.5 Современная технология изготовления
МикропроцессорAthlon XP в «безмостиковой» упаковке
В современных компьютерах процессоры выполнены в виде компактного модуля (размерами около 5×5×0,3 см) вставляющегося в ZIF-сокет. Большая часть современных процессоров реализована в виде одного полупроводникового кристалла, содержащего миллионы, а с недавнего времени даже миллиарды транзисторов. В первых компьютерах процессоры были громоздкими агрегатами, занимавшими подчас целые шкафы и даже комнаты, и были выполнены на большом количестве отдельных компонентов.
В начале 1970-х годов благодаря прорыву в технологии создания БИС и СБИС (больших и сверхбольших интегральных схем), микросхем, стало возможным разместить все необходимые компоненты ЦП в одном полупроводниковом устройстве. Появились так называемые микропроцессоры. Сейчас слова микропроцессор и процессор практически стали синонимами, но тогда это было не так, потому что обычные (большие) и микропроцессорные ЭВМ мирно сосуществовали ещё по крайней мере 10-15 лет, и только в начале 80-х годов микропроцессоры вытеснили своих старших собратьев. Надо сказать что переход к микропроцессорам позволил потом создать персональные компьютеры, которые теперь проникли почти в каждый дом.
Первый микропроцессор Intel 4004 был представлен 15 ноября1971 года корпорацией Intel. Он содержал 2300 транзисторов, работал на тактовой частоте 108 кГц и стоил 300$.
За годы существования технологии микропроцессоров было разработано множество различных их архитектур. Многие из них (в дополненном и усовершенствованном виде) используются и поныне. Например Intel x86, развившаяся вначале в 32 бит IA32 а позже в 64 бит x86-64. Процессоры архитектуры x86 вначале использовались только в персональных компьютерах компании IBM (IBM PC), но в настоящее время всё более активно используются во всех областях компьютерной индустрии, от суперкомпьютеров до встраиваемых решений. Также можно перечислить такие архитектуры как Alpha, POWER, SPARC, PA-RISC, MIPS (RISC — архитектуры) и IA-64 (EPIC-архитектура).
Большинство процессоров используемых в настоящее время являются Intel-совместимыми, то есть имеют набор инструкций и пр., как процессоры компании Intel.
Наиболее популярные процессоры сегодня производят фирмы Intel, AMD и IBM. Среди процессоров от Intel: 8086, i286 (в русском компьютерном сленге называется «двойка», «двушка»), i386 («тройка», «трёшка»), i486 («четвёрка»), Pentium (i586)(«пень», «пенёк», «второй пень», «третий пень» и т. д. Наблюдается также возврат названий: Pentium III называют «тройкой», Pentium 4 — «четвёркой»), Pentium II, Pentium III, Celeron (упрощённый вариант Pentium), Pentium 4, Core 2 Duo, Xeon (серия процессоров для серверов), Itanium и др. AMD имеет в своей линейке процессоры Amx86 (сравним с Intel 486), Duron, Sempron (сравним с Intel Celeron), Athlon, Athlon 64, Athlon 64 X2, Opteron и др.
В ближайшие 10-20 лет, скорее всего, изменится материальная часть процессоров ввиду того, что технологический процесс достигнет физических пределов производства. Возможно, это будут:
1. Квантовые компьютеры
2. Молекулярные компьютеры
Квантовые процессоры
Процессоры, работа которых всецело базируется на квантовых эффектах. В настоящее время ведутся работы над созданием рабочих версий квантовых процессоров.
ЗАКЛЮЧЕНИЕ
В соответствии с целями данной работы были изучены последовательная и параллельная архитектуры процессоров.
На основании рассмотренного материала делаем вывод о том, что конвейерная обработка команд и суперскалярное выполнение команд являются важнейшими технологиями, позволяющими ускорить работу процессоров. Применение технологии конвейерной обработки информации позволяет создавать процессоры с быстродействием, равным одной команде за такт. А процессоры с суперскалярной организацией способны выполнять по нескольку команд за такт. Таким образом, системы команд, ориентированные на конвейерное выполнение, являются одним из ключевых элементов современных высокопроизводительных процессоров.
Параллельные процессоры позволяют устранить недостатки архитектуры фон Неймана.
СПИСОК ИСПОЛЬЗОВАННЫХ ИСТОЧНИКОВ
1)
Борковский А. Б. Англо-русский словарь по программированию и информатике. – М.:Русский язык, 1990. – 333с.
2)
Евсеев Г. А. Практическая информатика. – М: АСТ-ПРЕСС, 2001. – 480 с.
3)
Першиков В. И. Толковый словарь по информатике. – М: Финансы и статистика, 2005. - 544с.
4)
Хамахер К., Вранешич З.. Организация ЭВМ.. Спб.: «Питер», 2003, - 848с.
5)
http://window.edu.ru/window_catalog/pdf2txt?p_id=6579
6)
http://ru.wikipedia.org/wiki
7)
http://narod.ru/disk/2422645000/comp36.zip.html
|