В. Пикулев
Методы компьютерных вычислений и их приложение к физическим задачам
Методическое пособие
Петрозаводск, 2004г.
1. Всякий специалист стремится достичь своего уровня некомпетентности.
2. Компьютер – средство многократного увеличения некомпетентности человека.
3. Если две ошибки не принесли результата – испробуй третью.
Лоуренс Питер, «Иерархиология».
1. Введение в предмет
Численные методы – раздел математики, который со времен Ньютона и Эйлера до настоящего времени находит очень широкое применение в прикладной науке. Традиционно физика является основным источником задач построения математических моделей, описывающих явления окружающего мира, она же является основным потребителем алгоритмов и программ, позволяющих эти задачи с определенным успехом решать.
При этом задачей физика является не только правильный выбор программы, которая призвана решать физическую проблему, но и подробный анализ и корректировка используемых алгоритмов, в соответствии с реалиями поставленной задачи и теми математическими правилами, которые либо допускают существование решения с заданной точностью, либо говорят о невозможности такого решения.
Примеры современных физических задач, для решения которых используются численные методы – моделирование астрономических событий (рождение и развитие Вселенной), моделирование процессов в микромире (распад и синтез частиц), моделирование установок и процессов термоядерного синтеза. Более «прикладные» задачи – моделирование физических процессов в твердотельных структурах (широко используется в проектировании и изготовлении интегральных схем), моделирование процессов в газах и плазме. Учитывая большую сложность и дороговизну современных экспериментальных методик, и, с другой стороны, постоянный рост производительности вычислительных систем, нетрудно определить тенденцию к увеличению в настоящее время доли модельных (вычислительных) экспериментов. Большое количество численных методов разработано для решения задач математической физики, к которым, например, относятся задачи тепло- и массопереноса, исследования турбулентного движения.
К инженерным приложениям численных методов можно отнести расчеты магнитных и электростатических линз для заряженных частиц, различного рода радиотехнические расчеты, включая, например, проектирование СВЧ-волноводов. Любопытно, что как в теоретической физике, так и в инженерной практике решаются численными методами различные задачи теоретической механики, например, задачи столкновения (в том числе динамический хаос). Естественно, такое приложение вычислительной техники к физике, как управление экспериментом и сбор данных, в данном курсе не рассматривается.
План построения вычислительного эксперимента:
1) Создание модели, фиксирующей главные исследуемые факторы. Одновременно формулируются рамки применимости модели.
2) Предварительное исследование математической модели: поверка корректности постановки задачи, существования и единственности решения.
3) Разработка метода расчета сформулированной задачи, построение эффективных вычислительных алгоритмов.
4) Создание программы, осуществляющей моделирование физического объекта, включающей в себя реализации используемых численных методов, проверки корректности ввода исходных и вывода результирующих данных
5) Сравнение полученных результатов моделирования с тестовыми примерами и экспериментальными данными; решение вопроса о правильности практического моделирования (иначе повторяются пункты 3 и 4).
6) Решение вопроса о достоверности предложенной математической модели. Если модель не описывает экспериментальные данные, возврат на пункт 1.
Таким образом, численный эксперимент – это не однократное вычисление по некоторому набору формул, а многостадийный процесс программирования, анализа результатов и их погрешностей.
Задача называется корректно поставленной, если для любых входных данных х из некоторого класса решение y существует, единственно и устойчиво по входным данным.
(Класс может представлять собой координатное бесконечномерное пространство, множество непрерывных функций и др.)
Численный алгоритм – однозначная последовательность действий, которые могут привести к одному решению.
Отсутствие устойчивости обычно означает, что сравнительно небольшой погрешности δx соответствует весьма большое δy, а значит получаемое решение будет далеко от истинного. К такой задаче численные методы применять бессмысленно, ибо погрешности численного расчета будут катастрофически нарастать. Устойчивость задачи определяется (1) математической формулировкой, (2) используемым алгоритмом расчета. Пример неустойчивой задачи в первом случае:
Система 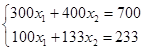 имеет решение имеет решение 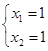 , однако , однако
Система  имеет решение имеет решение 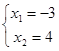 , то есть разница в коэффициенте менее 1% приводит к изменению решения в 300%. , то есть разница в коэффициенте менее 1% приводит к изменению решения в 300%.
Пример алгоритмической неустойчивости – вычисление производных численными методами: какой бы метод мы не использовали, приходится вычитать весьма мало различающиеся числа.
В настоящее время развиты методы решения многих некорректных задач, которые основаны на решении вспомогательной корректной задачи, близкой к исходной.
Если выполняется условие для норм (модулей)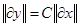 , то задача устойчива. Однако если константа С очень велика, то фактически наблюдается слабая устойчивость. Такую задачу называют плохо обусловленной. Пример – дифференциальное уравнение , то задача устойчива. Однако если константа С очень велика, то фактически наблюдается слабая устойчивость. Такую задачу называют плохо обусловленной. Пример – дифференциальное уравнение 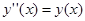 с начальными условиями с начальными условиями 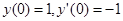 . Общее решение дифференциального уравнения есть . Общее решение дифференциального уравнения есть
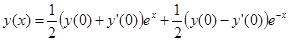
Начальные условия приводят к обнулению первого слагаемого, но если из-за погрешности начальных данных это будет не так, то при возрастании x влияние первого слагаемого будет катастрофически нарастать.
2. Точность вычислений, классификация погрешностей
Во всех случаях математическая точность решения должна быть в 2-4 раза выше, чем ожидаемая физическая точность модели. Более высокая математическая точность, как и более низкая, будут неадекватны данной модели.
Существуют четыре источника погрешности результата:
1) погрешность математической модели – связана с ее несоответствием физической реальности, так как абсолютная истина недостижима. Если математическая модель выбрана недостаточно тщательно, то, какие бы методы мы не применяли для расчета, все результаты будут недостаточно надежны, а в некоторых случаях и совершенно неправильны.
2) погрешность исходных данных, принятых для расчета. Это неустранимая погрешность, но это погрешность возможно и необходимо оценить для выбора алгоритма расчета и точности вычислений. Как известно, ошибки эксперимента условно делят на систематические, случайные и грубые, а идентификация таких ошибок возможно при статистическом анализа результатов эксперимента.
3) погрешность метода – основана на дискретном характере любого численного алгоритма. Это значит, что вместо точного решения исходной задачи метод находит решение другой задачи, близкого в каком-то смысле (например по норме банахова пространства) к искомому. Погрешность метода – основная характеристика любого численного алгоритма. Погрешность метода должна быть в 2-5 раз меньше неустранимой погрешности.
4) погрешность округления – связана с использованием в вычислительных машинах чисел с конечной точностью представления.
Вот иллюстрация этих определений. Пусть имеется реальный маятник, совершающий затухающие колебания, начинающий движение в момент t = t0
. Требуется найти угол отклонения φ от вертикали в момент t1
. Движение маятника мы можем описать следующим дифференциальным уравнением:
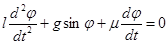
где l – длина маятника, g – ускорение силы тяжести, μ – коэффициент трения.
Как только принимается такое описание задачи, решение уже приобретает неустранимую погрешность, в частности потому, что реальное трение зависит от скорости не совсем линейно (погрешность модели). Кроме того, воспроизведя реальный эксперимент, мы зададим l, g (в известной точке планеты), μ с некоторой точностью, и получим набор значений с погрешностью, которую можем оценить из анализа статистики некоторого числа однотипных опытов (погрешность исходных данных). Взятое в модели дифференциальное уравнение нельзя решить в явном виде, для его решения требуется применить какой-либо численный метод, имеющий заранее известную погрешность, которая должна быть меньше неустранимой погрешности. После совершения вычислений мы получим значения с погрешностью большей, нежели погрешность метода, так как к ней прибавится погрешность округления.
Рассмотрим правила расчета погрешности округления:
1) Сложение и вычитание приближенных чисел
Введем в рассмотрение два числа a и b, называемых приближенными, то есть это есть оценка точных значений A и B, известных с абсолютными погрешностями ±εa
и ±εb
. Знаки этих погрешностей нам неизвестны, следовательно для обеспечения достоверности конечного результата мы должны взять наихудший случай, когда погрешности складываются. Таким образом формулируются следующие правила:
1. Абсолютная погрешность суммы приближенных чисел равна сумме абсолютных погрешностей слагаемых.
2. Абсолютная погрешность разности приближенных чисел равна сумме абсолютных погрешностей слагаемых.
Относительной погрешностью приближенного числа a будет являться величина
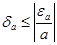
По этому же правилу определим относительную погрешность суммы приближенных чисел a и b как
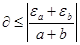
При этом можно показать, что
3. Относительная погрешность суммы слагаемых одного знака заключена между наименьшей и наибольшей относительными погрешностями слагаемых:
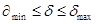
4. Для разности двух приближенных чисел одного знака величина относительной погрешности
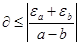 может быть сколь угодно большой. может быть сколь угодно большой.
2) Умножение и деление приближенных чисел
Очевидно, что приближенное число
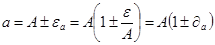
Тогда для произведения
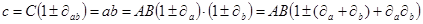
Если пренебречь последним малым слагаемым в скобках, то можно сформулировать следующее правило:
1. Относительная погрешность произведения приближенных чисел равна сумме относительных погрешностей множителей 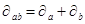 . .
Так как деление на число b равнозначно умножению на 1/b, то справедливо утверждение:
2. Относительная погрешность частного приближенных чисел равна сумме относительных погрешностей делимого и делителя.
Следовательно, при умножении и делении приближенных чисел необходимо принимать во внимание количество значащих цифр, характеризующих относительную точность числа, а не количество десятичных знаков, обуславливающих его абсолютную погрешность.
Совершенно очевидно, что при большом количестве действий такого сорта правила нельзя считать удовлетворительными, так как погрешности будут иметь разные знаки и компенсировать друг друга. Статистическая оценка показывает, что при N одинаковых действиях среднее значение суммарной ошибки больше единичной в 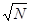 раз, если нет систематических причин для накопления погрешности. Систематические причины возникают, если, например в алгоритме вычитаются близкие по величине числа. раз, если нет систематических причин для накопления погрешности. Систематические причины возникают, если, например в алгоритме вычитаются близкие по величине числа.
При любых расчетах надо устанавливать такую точность вычислений, чтобы погрешность округления была существенно меньше всех остальных погрешностей.
3. Краткое введение в используемые программные средства
Традиционные языки высокоуровневого программирования. В большинстве практических случаев моделирование или численный расчет предполагает использование готового алгоритма, который необходимым образом модифицируется для конкретной задачи. В настоящее время существуют обширные фонды алгоритмов и программ, ориентированных на классические языки программирования, такие как Фортран, Си и Паскаль. Наиболее мощные математические библиотеки были разработаны для самого старого языка программирования из вышеперечисленных – Фортрана. Однако во многих случаях, обладая соответствующей квалификацией, легче написать программу, отталкиваясь от первых принципов, нежели тестировать и исправлять, или переводить на другой язык программирования незнакомый текст.
Другое направление, которое в настоящее время особенно популярно – использование мощных математических пакетов для численных и аналитических расчетов.
Mathcad.
Разрабатывается компанией MathSoft Inc. Является наиболее легкой для освоения системой математических расчетов. Принята концепция «активного документа», то есть все вычисления записываются в традиционной математической нотации (с использованием значков интеграла, суммы и др.), а после введения знака равенства или другого запускающего символа появляется рассчитанное значение. Основной недостаток – слишком мал набор основных функций и очень низкое быстродействие.
MathLab.
Система MATLAB (MATrix LABoratory) разрабатывается фирмой MathWorks. Эта система создана для работы в среде Windows и представляет собой интерактивную среду для вычислений и моделирования, причем она может работать как в режиме непосредственных вычислений (очень напоминает режим «командной строки»), так и в режиме интерпретации написанных программ. Сильная сторона системы – виртуозная работа с матрицами и векторами. Численное значение или аналитическая формула, а также сообщения системы выводится на экран в виде списка. Помимо обычных алгебраических вычислений система имеет огромный набор встроенных функций, а также имеется возможность создавать пользовательские функции. В системе очень качественно реализовано построение двух и трехмерных изображений, в том числе динамически изменяющихся. Кроме того, имеется библиотека, которая обеспечивает удобное управление исполнением программ. И это только базовый набор, который обычно расширяется многочисленными дополнениями – например языком Simulink моделирования нелинейных динамических систем. Основное назначение – технические расчеты.
Mathematica.
Разрабатывается фирмой Wolfram Research. Одна из наиболее сложных для освоения систем. Предназначена в основном для решения теоретических задач, в связи с чем весьма популярна в научных кругах. Предуставляет широкие возможности в проведении символических (аналитических) преобразований, красотой интерфейса не отличается.
Maple.
Разработка компании Waterloo Maple Inc. Также очень популярный в научных кругах пакет аналитических преобразований и численных методов. Символический процессор Maple поставляется отдельно, в связи с чем производители других программных средств могут интегрировать его в свои разработки.
4. Численное интегрирование
Задача численного интегрирования состоит в замене исходной подинтегральной функции f(x), для которой трудно или невозможно записать первообразную в аналитике, некоторой аппроксимирующей функцией φ(x). Такой функцией обычно является полином (кусочный полином)
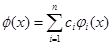
То есть:
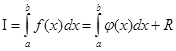 , ,
где 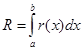 – априорная погрешность метода на интервале интегрирования, – априорная погрешность метода на интервале интегрирования,
а r(x) – априорная погрешность метода на отдельном шаге интегрирования.
Обзор методов интегрирования.
Методы вычисления однократных интегралов называются квадратурными (для кратных интегралов – кубатурными).
1) Методы Ньютона-Котеса. Здесь φ(x) – полином различных степеней. Сюда относятся метод прямоугольников, трапеций, Симпсона.
2) Методы статистических испытаний (методы Монте-Карло). Здесь узлы сетки для квадратурного или кубатурного интегрирования выбираются с помощью датчика случайных чисел, ответ носит вероятностный характер. В основном применяются для вычисления кратных интегралов.
3) Сплайновые методы. Здесь φ(x) – кусочный полином с условиями связи между отдельными полиномами посредством системы коэффициентов.
4) Методы наивысшей алгебраической точности. Обеспечивают оптимальную расстановку узлов сетки интегрирования и выбор весовых коэффициентов ρ(x) в задаче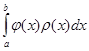 . Сюда относится метод Гаусса Кристоффеля (вычисление несобственных интегралов) и метод Маркова. . Сюда относится метод Гаусса Кристоффеля (вычисление несобственных интегралов) и метод Маркова.
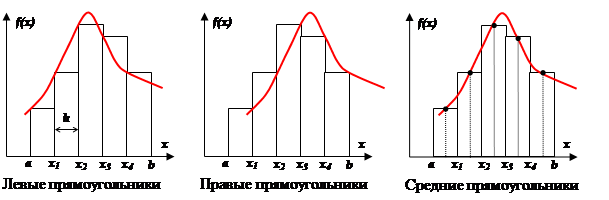
Метод прямоугольников.
Различают метод левых, правых и средних прямоугольников. Суть метода ясна из рисунка. На каждом шаге интегрирования функция аппроксимируется полиномом нулевой степени – отрезком, параллельным оси абсцисс.
Выведем формулу метода прямоугольников из анализа разложения функции f(x) в ряд Тейлора вблизи некоторой точки x = xi
.
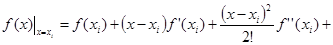
Рассмотрим диапазон интегрирования от xi
до xi
+ h, где h – шаг интегрирования.
Вычислим 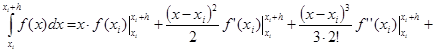 …= …=
=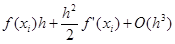 = =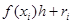
Получили формулу правых (или левых) прямоугольников и априорную оценку погрешности r на отдельном шаге интегрирования. Основной критерий, по которому судят о точности алгоритма – степень при величине шага в формуле априорной оценки погрешности.
В случае равного шага h на всем диапазоне интегрирования общая формула имеет вид
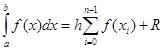
Здесь n – число разбиений интервала интегрирования
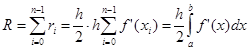
Для справедливости существования этой оценки необходимо существование непрерывной f’(x).
Метод средних прямоугольников. Здесь на каждом интервале значение функции считается в точке
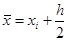 , то есть , то есть 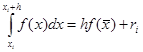
Разложение функции в ряд Тейлора показывает, что в случае средних прямоугольников точность метода существенно выше:
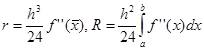
Метод трапеций.
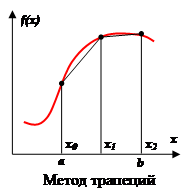
Аппроксимация в этом методе осуществляется полиномом первой степени. Суть метода ясна из рисунка.
На единичном интервале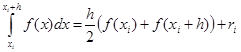 . .
В случае равномерной сетки (h = const)
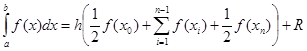
При этом 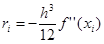 , а , а 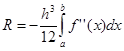
Погрешность метода трапеций в два раза выше, чем у метода средних прямоугольников! Однако на практике найти среднее значение на элементарном интервале можно только у функций, заданных аналитически (а не таблично), поэтому использовать метод средних прямоугольников удается далеко не всегда. В силу разных знаков погрешности в формулах трапеций и средних прямоугольников истинное значение интеграла обычно лежит между двумя этими оценками.
Особенности поведения погрешности.

Казалось бы, зачем анализировать разные методы интегрирования, если мы можем достичь высокой точности, просто уменьшая величину шага интегрирования. Однако рассмотрим график поведения апостериорной погрешности R результатов численного расчета в зависимости от числа n разбиений интервала (то есть при 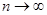 шаг шаг 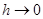 ). На участке (1) погрешность уменьшается в связи с уменьшением шага h. Но на участке (2) начинает доминировать вычислительная погрешность, накапливающаяся в результате многочисленных арифметических действий. Таким образом, для каждого метода существует своя Rmin
, которая зависит от многих факторов, но прежде всего от априорного значения погрешности метода R. ). На участке (1) погрешность уменьшается в связи с уменьшением шага h. Но на участке (2) начинает доминировать вычислительная погрешность, накапливающаяся в результате многочисленных арифметических действий. Таким образом, для каждого метода существует своя Rmin
, которая зависит от многих факторов, но прежде всего от априорного значения погрешности метода R.
Уточняющая формула Ромберга.
Метод Ромберга заключается в последовательном уточнении значения интеграла при кратном увеличении числа разбиений. В качестве базовой может быть взята формула трапеций с равномерным шагом h.
Обозначим интеграл с числом разбиений n = 1 как
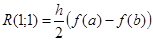
Уменьшив шаг в два раза, получим

Если последовательно уменьшать шаг в 2n
раз, получим рекуррентное соотношение для расчета
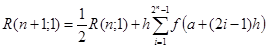
Пусть мы вычислили четыре раза интеграл с n от 1 до 4. Представим следующий треугольник:
R(1;1)
R(2;1) R(2;2)
R(3;1) R(3;2) R(3;3)
R(4;1) R(4;2) R(4;3) R(4;4)
В первом столбце стоят значения интеграла, полученные при последовательном удвоении числа интервалов. Следующие столбцы – результаты уточнения значения интеграла по следующей рекуррентной формуле:
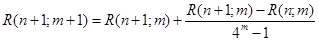 . .
Правое нижнее значение в треугольнике – искомое уточненное значение интеграла.
Метод Симпсона.
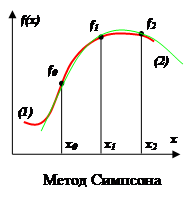
Подинтегральная функция f(x) заменяется интерполяционным полиномом второй степени P(x) – параболой, проходящей через три узла, например, как показано на рисунке ((1) – функция, (2) – полином).
Рассмотрим два шага интегрирования (h = const = xi
+1
– xi
), то есть три узла x0
, x1
, x2
, через которые проведем параболу, воспользовавшись уравнением Ньютона:
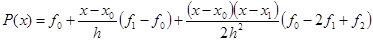 . .
Пусть z = x – x0
,
тогда 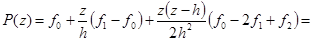
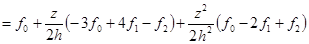
Теперь, воспользовавшись полученным соотношением, сосчитаем интеграл по данному интервалу:
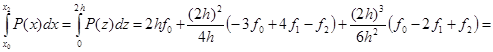
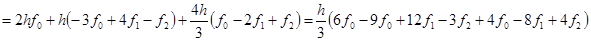
В итоге 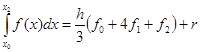 . .
Для равномерной сетки и четного числа шагов n формула Симпсона принимает вид:
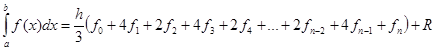
Здесь 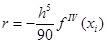 , а , а 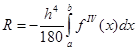
В предположении непрерывности четвертой производной подинтегральной функции.
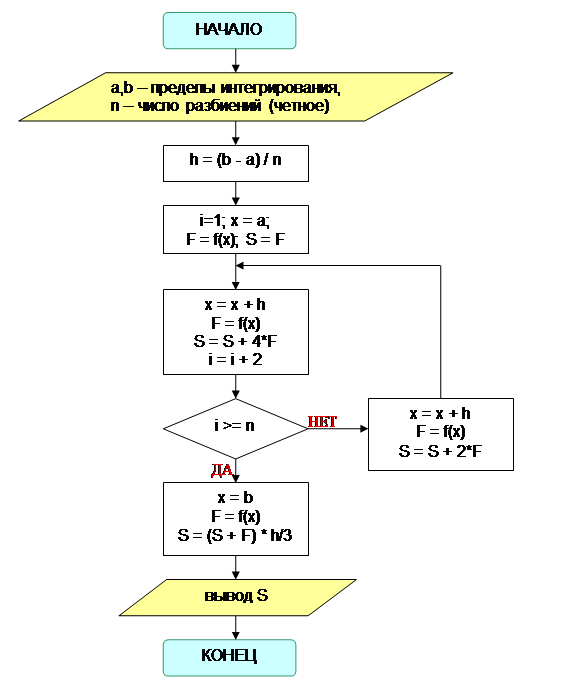
Блок-схема алгоритма метода Симпсона
Методы Монте-Карло
1) одномерная случайная величина – статистический вариант метода прямоугольников.

В качестве текущего узла xi
берется случайное число, равномерно распределенное на интервале интегрирования [a, b]. Проведя N вычислений, значение интеграла определим по следующей формуле:
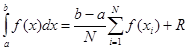
Для R можно утверждать хотя бы ~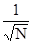
2) двумерная случайная величина – оценка площадей.
Рассматриваются две равномерно распределенных случайных величины xi
и yi
, которые можно рассматривать как координаты точки в двумерном пространстве. За приближенное значение интеграла принимается количества точек S, попавших под кривую y = f(x), к общему числу испытаний N, т.е.
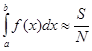
И первый, и второй случай легко обобщаются на кратные интегралы.
5. Оценка апостериорной погрешности
Мы записывали априорные оценки главного члена погрешности в виде R0
= Ahp
, (1) где A – коэффициент, зависящий от метода интегрирования и вида подинтегральной функции; h – шаг интегрирования, p – порядок метода. Такого сорта оценку можно применить не только к методам интегрирования, но и ко многим другим численным алгоритмам.
Первая формула Рунге.
Пусть w – точное значение, к которому должен прийти численный метод (мы его не знаем). Результат численного расчета дает нам величину wh
такую, что
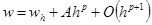 . (2) . (2)
Теперь вычислим ту же величину w с шагом kh, где константа k может быть как больше, так и меньше единицы. Коэффициент A будет одинаковый, так как вычисление осуществляется одним и тем же методом. Получаем
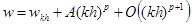 (3) (3)
Приравняем правые части выражений (2) и (3) и пренебрежем бесконечно малыми величинами одинакового порядка малости.
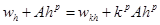
Отсюда, учитывая (1), получим
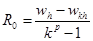
(4) Эта формула, выражающая апостериорную оценку главного члена погрешности величины w путем двойного просчета с разным шагом, носит название первой формулы Рунге. При уменьшении шага главный член погрешности будет стремиться к полной погрешности R.
Вторая формула Рунге.
Так как модуль и знак апостериорной погрешности из формулы (4) известны, можно уточнить искомое значение
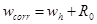
Это вторая формула Рунге. Однако теперь погрешность wcorr
не определена, известно лишь, что она по модулю меньше R0
.
Алгоритм Эйткена.
Способ оценки погрешности для случая, когда порядок метода p неизвестен. Более того, алгоритм позволяет опытным путем определить и порядок метода. Для этого в третий раз вычислим значение величины w с шагом k2
h:
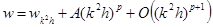 . (5) . (5)
Приравняем правые части выражений (5) и (3):
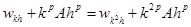
Отсюда:
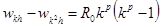
Подставим сюда значение R0
из (4):
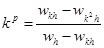
Из этой формулы определяем знаменатель для (4). Кроме того, определяем порядок
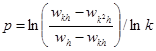
Для правильно реализованных алгоритмов методов априорных и апостериорных порядки должны получиться совпадающими. Программная реализация формул Рунге позволяет вычислить определенные интегралы с заданной точностью, когда выбор необходимого числа разбиений интервала интегрирования осуществляется автоматически. Пример – уже рассмотренная ранее формула Ромберга.
6. Численное дифференцирование
Методы численного дифференцирования применяются, если исходную функцию f(x) трудно или невозможно продифференцировать аналитически. Например, эта функция может быть задана таблично. Задача численного дифференцирования – выбрать легко вычисляемую функцию (обычно полином) 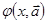 , для которой приближенно полагают , для которой приближенно полагают 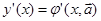 . .

Численное дифференцирование – некорректная задача, так как отсутствует устойчивость решения. При численном дифференцировании приходится вычитать друг из друга близкие значения функции. Это приводит к уничтожению первых значащих цифр, т.е. к потере части достоверных знаков числа. А так как значения функции обычно известны с определенной погрешностью, то все значащие цифры могут быть потеряны. На графике кривая (1) соответствует уменьшению погрешности дифференцирования при уменьшении шага; кривая (2) представляет собой неограниченно возрастающий (осциллирующий) вклад неустранимой погрешности исходных данных – значений функции y(x). Критерий выхода за оптимальный шаг при его уменьшении – «разболтка» решения: зависимость результатов вычислений становится нерегулярно зависящей от величины шага.
Пусть 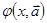 введена как интерполяционный многочлен Ньютона. В этом случае для произвольной неравномерной сетки: введена как интерполяционный многочлен Ньютона. В этом случае для произвольной неравномерной сетки:
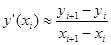 , для i = 0,1…n-1, интерполяция полиномом первой степени. , для i = 0,1…n-1, интерполяция полиномом первой степени.
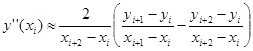 , интерполяция полиномом второй степени. , интерполяция полиномом второй степени.
В общем случае 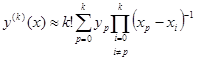
Минимальное число узлов, необходимое для вычисления k-й производной, равно k + 1.
Оценка погрешности при численном дифференцировании может быть осуществлена по формуле
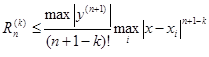
где n – число узлов функции, k – порядок производной.
На практике чаще всего используются упрощенные формулы для равномерной сетки, при этом точность нередко повышается. Часто используются следующие формулы для трех узлов:
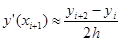 , где h = x1
– x0
= const. , где h = x1
– x0
= const.
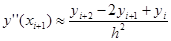
Исходя из общего вида интерполяционного полинома можно вывести формулы для более высокого порядка точности или для более высоких производных.
7. Численное решение систем линейных уравнений
Классы задач линейной алгебры
При численном решении большого круга задач в конечном итоге происходит их линеаризация, в связи с чем в соответствующих алгоритмах весьма широко используются методы линейной алгебры. В их числе:
· решение систем линейных алгебраических уравнений (СЛАУ);
· вычисление определителей матриц 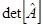 ; ;
· нахождение обратных матриц 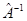 ; ;
· определение собственных значений и собственных векторов матриц 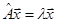 ; ;
Постановка задачи решения СЛАУ:
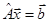 , (1) , (1)
где 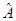 – квадратная матрица коэффициентов размерности n, – квадратная матрица коэффициентов размерности n, 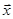 – вектор неизвестных, – вектор неизвестных, 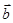 – вектор свободных коэффициентов. Иногда СЛАУ представляют в виде расширенной матрицы размерности n × n+1, где в качестве последнего столбца фигурирует вектор свободных коэффициентов. В координатном представлении такая СЛАУ выглядит следующим образом: – вектор свободных коэффициентов. Иногда СЛАУ представляют в виде расширенной матрицы размерности n × n+1, где в качестве последнего столбца фигурирует вектор свободных коэффициентов. В координатном представлении такая СЛАУ выглядит следующим образом:
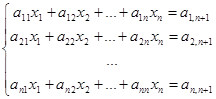 . (2) . (2)
Для решения СЛАУ применяют в основном два класса методов: прямые (выполняемые за заранее известное количество действий) и итерационные (обеспечивающие постепенную сходимость к корню уравнения, зависящую от многих факторов). Прямые методы обычно применяются для решения систем порядка n < 200, для бóльших n используются итерационные методы. Перед решением СЛАУ требуется проанализировать корректную постановку задачи:
1) Если 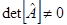 – решение существует и единственно. Если же определитель равен нулю, то тогда, если матрица вырождена (т.е. ее можно преобразовать к виду, когда как минимум одна строка коэффициентов – нули) решений бесконечное множество, иначе решения не существует. – решение существует и единственно. Если же определитель равен нулю, то тогда, если матрица вырождена (т.е. ее можно преобразовать к виду, когда как минимум одна строка коэффициентов – нули) решений бесконечное множество, иначе решения не существует.
2) Если 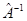 не имеет элементов с большими по модулю значениями решение устойчиво (см. пример к главе 1). Показателем плохо обусловленных систем является не имеет элементов с большими по модулю значениями решение устойчиво (см. пример к главе 1). Показателем плохо обусловленных систем является 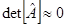 . .
Алгоритм метода Гаусса
1) Прямой ход.
Идея метода состоит в последовательном исключении неизвестных из системы n линейных уравнений. На примере первого уравнения системы (2) рассмотрим выражение для x1
:
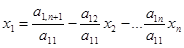 . .
Подставим выражение для x1
во второе и все остальные уравнения системы:
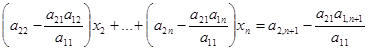 . .
Для расширенной матрицы коэффициентов это означает, что каждый элемент первой строки следует поделить на диагональный элемент, а все остальные строки преобразовать, как показано выше. Таким образом, станут равны нулю все коэффициенты первого столбца, лежащие ниже главной диагонали. Затем аналогичная процедура проводится со второй строкой матрицы и нижележащими строками, при этом первая строка и первый столбец уже не изменяются. И так далее до тех пор, пока все коэффициенты, лежащие ниже главной диагонали, не будут равны нулю.
Общие формулы прямого хода:
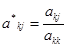 , (3) , (3)
k = 1…n, j = 1…n+1. Звездочкой отмечены элементы k-й строки с измененными значениями, которые будут подставлены в следующую формулу. Для определенности будем считать первый индекс – по строкам, второй – по столбцам.
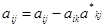 , (4) , (4)
i = k +1…n, j = 1…n+1, k фиксировано в уравнении (3). Для уменьшения количества действий достаточно изменять значения элементов, находящихся выше главной диагонали.
2) Обратный ход.
Второй этап решения СЛАУ методом Гаусса называется обратным ходом и состоит в последовательном определении xk
, начиная с xn
, так как для последнего решение фактически получено. Общая формула:
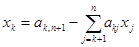 . (5) . (5)
Таким образом, вычисление корней 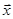 происходит за 2/3 n3
арифметических действий. происходит за 2/3 n3
арифметических действий.
3) Выбор главного элемента.
Для уменьшения погрешности вычислений следует стремиться к тому, чтобы на главной диагонали матрицы стояли максимальные по модулю значения коэффициентов. Алгоритмически этого можно добиться, переставляя строки таким образом, чтобы на диагонали стоял наибольший по модулю элемент текущего столбца. Такая процедура называется выбором главного элемента и осуществляется всякий раз при переходе к новой строке в прямом цикле метода Гаусса.
4) Погрешность метода. Расчет невязок.
Точность результатов будет определяться только точностью выполнения арифметических операций при преобразовании элементов матрицы, т.е. ошибкой округления. Контроль правильности полученного решения осуществляется подстановкой полученных значений x1
…xn
в исходную систему уравнений и вычислением невязок, т.е. разностей между правыми и левыми частями уравнений:
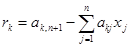 , где k = 1…n. (6) , где k = 1…n. (6)
Специально отметим, что подставлять найденные значения 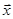 следует в исходную (не преобразованную к верхнетреугольному виду) систему. следует в исходную (не преобразованную к верхнетреугольному виду) систему.
5) Преимущества и недостатки метода.
Преимущество метода в том, что он позволяет достичь результата за заранее известное и фиксированное число действий. Точность результатов будет определяться правильным выбором порядка коэффициентов в матрице 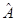 и ее размерностью. Недостатком метода является резкое увеличение времени и погрешности вычислений с ростом n. и ее размерностью. Недостатком метода является резкое увеличение времени и погрешности вычислений с ростом n.
Блок-схема алгоритма метода Гаусса без выбора главного элемента

Итерационные методы решения систем линейных уравнений.
Простейшим итерационным методом решения СЛАУ является метод простой итерации. При этом система уравнений 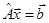 (1) преобразуется к виду (1) преобразуется к виду
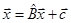 (2) (2)
а ее решение находится как предел последовательности
 (3) (3)
где {n} – номер итерации. Утверждается, что всякая система (2), эквивалентная (1), записывается в виде
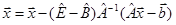
Теорема о достаточном условии сходимости метода простой итерации утверждает, что если норма матрицы
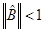 ( (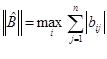 ) )
то система уравнений (2) имеет единственное решение и итерационный процесс (3) сходится к решению со скоростью геометрической прогрессии.
Теорема о необходимом и достаточном условии сходимости метода простой итерации: Пусть система (2) имеет единственное решение. Итерационный процесс (3) сходится к решению системы (2) при любом начальном приближении тогда и только тогда, когда все собственные значения матрицы 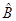 по модулю меньше 1. по модулю меньше 1.
На практике для обеспечения сходимости итерационных методов необходимо, чтобы значения диагональных элементов матрицы СЛАУ были преобладающими по абсолютной величине по сравнению с другими элементами.
Представим СЛАУ в следующей форме, удовлетворяющей (3):
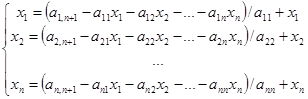 (4) (4)
Зададим начальные приближения 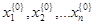 и вычислим правую часть (4), получим новые приближения и вычислим правую часть (4), получим новые приближения 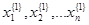 , которые опять подставим в систему (4). Таким образом организуется итерационный процесс, который обрывается по условию , которые опять подставим в систему (4). Таким образом организуется итерационный процесс, который обрывается по условию 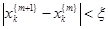 , где , где 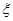 – заданная погрешность. – заданная погрешность.
К ускорению сходимости приводит использование приближения к решениям путем последовательного уточнения компонентов, причем k-я неизвестная находится из k-го уравнения. Такая модификация итерационного метода носит название метода Зейделя:
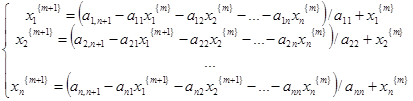
Критерий сходимости метода Зейделя: Пусть 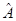 – вещественная симметричная положительно определенная матрица. Тогда метод Зейделя сходится. – вещественная симметричная положительно определенная матрица. Тогда метод Зейделя сходится.
Достоинствами метода простых итераций является простота программной реализации и более быстрый, по сравнению с линейными методами, поиск решения в матрицах большого размера. Недостатками являются сложный контроль условий сходимости и выбора начального приближения.
8)Интерполирование функций
 
1) Необходимость: приблизить f(x) более простой функцией ф(х), совпадающей в узлах xi
с f(xi
), если f(x) определена только в узловых точках (результат эксперимента) или очень сложно вычисляется.
Условия Лагранжа
ф(х, с0
, с1
…сn
) = fi
, 0 <_
i < n,
где сi
- свободные параметры, определяемые из данной системы уравнений.
С помощью интерполяции решают широкий круг задач численного анализа: дифференцирование и интегрирование функций, нахождение нулей и экстремумов, решение дифференцированных и т. д. Термин интерполяция употребляют, если х заключено между узлами, если он выходит за крайний узел, говорят об экстраполяции(при которой трудно гарантировать надежность приближения).
2) Пусть ф (х) = с0
+ с1
х + с2
х2
+…+ сn
xn
(канонический вид полинома) ;сетка узлов может быть неравномерной. Получившаяся СЛАУ относительно свободных параметров сi имеет решение, если среди узлов хi
нет совпадающих.Ее определитель – определитель Вандермонда:
Общая блок-схема:
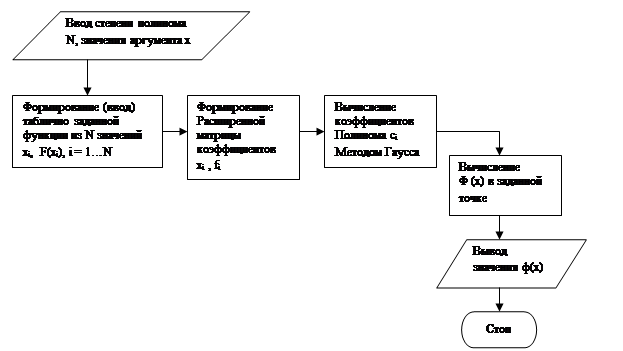
3) Пусть задано n+1 значение функции f(x) в узлах xj
ф(х) = Pn
(х) = 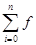 i i
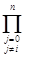 (x-xj
)/(xi
-xj
) - полином Лагранжа (x-xj
)/(xi
-xj
) - полином Лагранжа
Преимущества: потребуется решать СЛАУ для определения значения полинома в точке х.
Недостатки: для каждого х полином требуется читать заново.
Погрешность формулы:
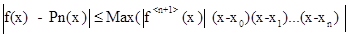 (*) (*)
Увеличение числа узлов и, соответственно, степени полинома Pn
(x) ведет к увеличению погрешности из-за роста производных 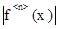 . .
4) ф(х) = Pn
(x) = A0
+A1
(x-x0
)+A2
(x-x0
)(x-x1
)+…+An
(x-x0
)(x-x1
)…(x-xn
-1
) - многочлен Ньютона для n+1 узла.
Коэффициенты Ф представляют собой разделенные разности и записываются в виде:
А0
= f0
A1
= (f0
-f1
)/(x0
-x1
) = f01
A2
= (f01
-f02
)/(x1
-x2
) = f012
, где f02
= (f0
-f2
)/(x0
-x2
)
A3
= (f012
-f013
)/(x2
-x3
) = f0123
, где f013
= (f01
-f03
)/(x1
-x3
) , а f03
= (f0
-f3
)/(x0
-x3
)
и в общем случае Ak
= (f01…
k
-1
-f01…
k
)/(xk
-1
-xk
)
Т.е. многочлен n-й степени выражается при помощи разделенных разностей через свои значения в узлах.
Преимущества: не решается СЛАУ, однако вычисление коэффициентов полинома не зависит от значения х и может быть вычислено только один раз. При добавлении нового узла также не происходит пересчета коэффициентов, кроме последнего.
После определения коэффициентов полинома Ньютона вычисление его значений при конкретных аргументах х наиболее экономично проводить по схеме Горнера:
P2
(x) = A0
+ (x-x0
)(A1
+(x-x2
)(A3
+…)…)

Погрешность определяется тем же соотношением (*)
Входящая в состав погрешности величина
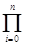 (х-хi
) = wn
(x) ведет себя при постоянном шаге так, как показано на рисунке. Многочлен Ньютона имеет погрешность 0(hn
+1
) и обеспечивает n+1-й порядок точности интерполяции. (х-хi
) = wn
(x) ведет себя при постоянном шаге так, как показано на рисунке. Многочлен Ньютона имеет погрешность 0(hn
+1
) и обеспечивает n+1-й порядок точности интерполяции.
Между разделенными разностями и производными соответствующих порядков существует соотношение f <
n
>
(x) ~ n! F01…
n
, где n – степень производной. Это используется в численном дифференцировании и при оценке погрешностей интерполяции.

Можно строить полиномы, не только проходящие через заданные точки, но и имеющие в них заданные касательные (интерполяционный многочлен Эрмита) или заданную кривизну. Количество всех полагаемых условий должно быть n-1, если n – степень полинома.
Основной недостаток интерполирования с помощью многочленов – неустранимые колебания, которые претерпевает кривая в промежутках между узлами.
При этом повышение степени интерполяционного полинома для большинства решаемых уравнений приводит не к уменьшению, а к увеличению погрешности.
Интерполяция сплайнами.
Происхождение термина “сплайны” связано с гибкой чертежной линейкой, которой пользовались для рисования гладких кривых, проходящих через заданные точки. Из теории упругости следует, что получающаяся кривая имеет постоянную кривизну и разрывы возникают лишь в третьей производной.
Обычно для сплайна выбирают кубический полином
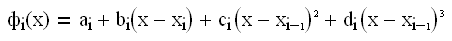
определенный на интервале х из [xi
-1
, хi
].
При этом вся кривая представляет собой набор таких кубических полиномов, с определенным образом подобранными коэффициентами аi
, bi
, ci
, di
, i- параметр сплайна.

Если вдоль сплайна совершается механическое движение, то непрерывность второй производной предполагает непрерывность ускорения и, следовательно, отсутствие резких изменений приложенной силы.

N+1 узлов
N интервалов

4N неизвестных
Условия подбора коэффициентов:
1)условия Лагранжа:
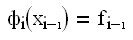 , ,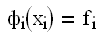
2)непрерывность первой и второй производной в узлах
фi
’(xi
) = фi
+1’(
xi
); фi
”(xi
) = фi
+1
(xi
)
3) условия в крайних узлах x0
и xn
. Обычно задают условия свободных концов сплайна:
ф1
”(x0
) = 0, фn
”(xn
) = 0
Из полученных условий определяются зависимости между коэффициентами сплайнов:
В узле х = хi
-1
коэффициент ai
= fi
-1
.
В следующем узле x = xi
выполняется условие ai
+bi
hi
+ci
hi
2
+di
hi
3
= fi
,
где элементарный шаг hi
= xi
– xi
-1
.
Потребуем непрерывности первой и второй производной на конце интервала
фi
/
(x) = bi
+2ci
(x-xi-1
)+3di
(x-xi-1
)2
,
фi
//
(x) = 2ci
+6di
(x-xi-1
);
В узле x = xi
первая производная
фi
/
(xi
) = bi
+2ci
hi
+3di
hi
2
(1)
фi
+1
//
(xi
) = bi
+1
(2)
Приравнивая (1) и (2), получаем bi
+2ci
hi
+3di
hi
2
= bi
+1
.
Вторая производная
фi
//
(xi
) = 2ci
+6ci
hi
(3)
фi+1
//
(xi
) = 2ci
(4)
Приравнивая (3) и (4), получаем в свою очередь ci
+3di
hi
= ci
+1
. Таким образом стыкуем все полиномы в узлах 1 ≤ i ≤ n-1. В крайних точках диапазона
ф1
//
(x0
) = 2c1
= 0 → c1
= 0
ф1
//
(xn
) = 2cn
+6dn
hn
= 0 → cn
+3dn
hn
= 0
Для всех 0 ≤ i ≤ n вышеприведенные соотношения представляют собой полную систему 4n линейных алгебраических уравнений относительно коэффициентов сплайнов, которую можно привести к системе ЛАУ, выразив коэффициенты ai
, bi
, di
через ci
и решить методом Гаусса или прогонки.
Система N линейных уравнений для коэффициентов сi
:
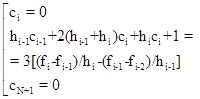
для 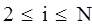 , ,
где hi
= xi
-xi
-1
После определения коэффициентов ci
, 2N коэффициентов bi
и di
вычисляются по формулам:
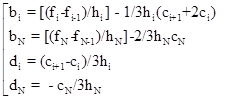 , ,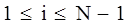
И N уравнений для 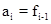 , , 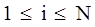
Сплайновая интерполяция хороша тем, что требует знания в узлах только значений функции, но не ее производных.
Многомерная интерполяция
1) Последовательная интерполяция на прямоугольной сетке. Пусть заданы z i
j
= z(xi
, yj
) требуется найти z(x, y). Сначала при фиксированных yj
0
найдем значение z(x, yj
0
),
Затем по полученному набору значений найдем z(x, y).
В случае интерполяции полиномом Лагранжа общая формула имеет вид
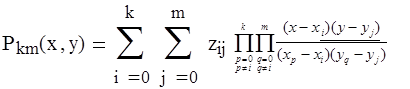
где k и m – количество узлов по сторонам прямоугольной сетки.
2) Треугольная конфигурация узлов.
z (x0
, x1
, y) = [z(x0
, y)-z(x1
, y)]/(x0
-x1
)
z (x, y0
, y1
) = [z(x, y0
)-z(x,y1
)]/(y0
-y1
)
Многочлен Лагранжева типа в этом случае имеет вид
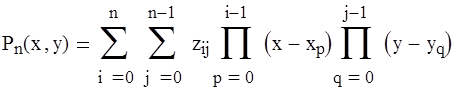
9. Аппроксимация функций методом наименьших квадратов
Постановка задачи аппроксимации по МНК. Условия наилучшего приближения.
Если набор экспериментальных данных получен со значительной погрешностью, то интерполяция не только не требуется, но и нежелательна! Здесь требуется построить кривую, которая воспроизводила бы график исходной экспериментальной закономерности, т.е. была бы максимально близка к экспериментальным точкам, но в то же время была бы нечувствительна к случайным отклонениям измеряемой величины.
Введем непрерывную функцию φ(x) для аппроксимации дискретной зависимости f(xi
), i = 0…n. Будем считать, что φ(x) построена по условию наилучшего квадратичного приближения, если
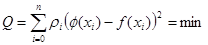 . (1) . (1)
Весу ρ для i-й точки придают смысл точности измерения данного значения: чем больше ρ, тем ближе аппроксимирующая кривая «притягивается» к данной точке. В дальнейшем будем по умолчанию полагать ρ = 1 для всех точек.
Рассмотрим случай линейной аппроксимации:
φ(x) = c0
φ0
(x) + c1
φ1
(x) + … + cm
φm
(x), (2)
где φ0
…φm
– произвольные базисные функции, c0
…cm
– неизвестные коэффициенты, m < n. Если число коэффициентов аппроксимации взять равным числу узлов, то среднеквадратичная аппроксимация совпадет с интерполяцией Лагранжа, при этом, если не учитывать вычислительную погрешность, Q = 0.
Если известна экспериментальная (исходная) погрешность данных ξ, то выбор числа коэффициентов, то есть величины m, определяется условием:
 . (3) . (3)
Иными словами, если 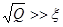 , число коэффициентов аппроксимации недостаточно для правильного воспроизведения графика экспериментальной зависимости. Если , число коэффициентов аппроксимации недостаточно для правильного воспроизведения графика экспериментальной зависимости. Если  , многие коэффициенты в (2) не будут иметь физического смысла. , многие коэффициенты в (2) не будут иметь физического смысла.
Для решения задачи линейной аппроксимации в общем случае следует найти условия минимума суммы квадратов отклонений для (2). Задачу на поиск минимума можно свести к задаче поиска корня системы уравнений
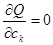 , k = 0…m. (4) , k = 0…m. (4)
Подстановка (2) в (1), а затем расчет (4) приведет в итоге к следующей системе линейных алгебраических уравнений:
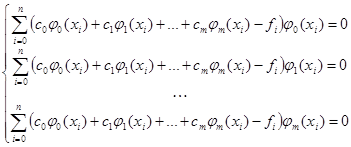
Далее следует решить полученную СЛАУ относительно коэффициентов c0
…cm
. Для решения СЛАУ обычно составляется расширенная матрица коэффициентов, которую называют матрицей Грама, элементами которой являются скалярные произведения базисных функций и столбец свободных коэффициентов:
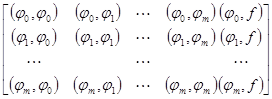 , ,
где 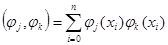 , , 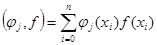 , j = 0…m, k = 0…m. , j = 0…m, k = 0…m.
После того как с помощью, например, метода Гаусса найдены коэффициенты c0
…cm
, можно построить аппроксимирующую кривую или вычислить координаты заданной точки. Таким образом, задача аппроксимации решена.
Аппроксимация каноническим полиномом.
Выберем базисные функции в виде последовательности степеней аргумента x:
φ0
(x) = x0
= 1; φ1
(x) = x1
= x; φm
(x) = xm
, m < n.
Расширенная матрица Грама для степенного базиса будет выглядеть следующим образом:
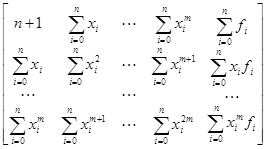 . .
Особенность вычислений такой матрицы (для уменьшения количества выполняемых действий) состоит в том, что необходимо сосчитать только элементы первой строки и двух последних столбцов: остальные элементы заполняются сдвигом предшествующей строки (за исключением двух последних столбцов) на одну позицию влево. В некоторых языках программирования, где отсутствует быстрая процедура возведения в степень, пригодится алгоритм расчета матрицы Грама, представленный далее.
Выбор базисных функций в виде степеней x не является оптимальным с точки зрения достижения наименьшей погрешности. Это является следствием неортогональности выбранных базисных функций. Свойство ортогональности заключается в том, что для каждого типа полинома существует отрезок [x0
, xn
], на котором обращаются в нуль скалярные произведения полиномов разного порядка:
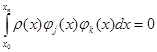 , j ≠ k, ρ – некоторая весовая функция. , j ≠ k, ρ – некоторая весовая функция.
Если бы базисные функции были ортогональны, то все недиагональные элементы матрицы Грама были бы близки к нулю, что увеличило бы точность вычислений, в противном случае при 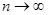 определитель матрицы Грама очень быстро стремится к нулю, т.е. система становится плохо обусловленной. определитель матрицы Грама очень быстро стремится к нулю, т.е. система становится плохо обусловленной.
Блок-схема алгоритма формирования матрицы Грама

Аппроксимация ортогональными классическими полиномами.
Представленные ниже полиномы, относящиеся ко многочленам Якоби, обладают свойством ортогональности в изложенном выше смысле. То есть, для достижения высокой точности вычислений рекомендуется выбирать базисные функции для аппроксимации в виде этих полиномов.
1) Полиномы Чебышева.
Определены и ортогональны на [–1, 1] с весом 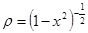 . В интервал ортогональности всегда можно вписать область определения исходной функции с помощью линейных преобразований. . В интервал ортогональности всегда можно вписать область определения исходной функции с помощью линейных преобразований.
Строятся следующим образом (рекуррентная формула):
T0
(x) = 1;
T1
(x) = x;
Tk
+1
(x) = 2xTk
(x) – Tk
–1
(x).
2) Полиномы Лежандра.
Определены и ортогональны на [–1, 1] с весом 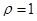 . .
Строятся следующим образом (рекуррентная формула):
L0
(x) = 1;
L1
(x) = x;
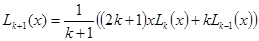 . .
Сглаживание и линейная регрессия.
Рассмотрим несколько наиболее простых с точки зрения программной реализации случаев аппроксимации (сглаживания).
1) Линейная регрессия.
В случае линейного варианта МНК (линейная регрессия) φ(x) = a + bx можно сразу получить значения коэффициентов a и b по следующим формулам:
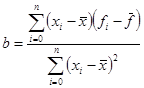 , ,
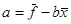 , ,
где 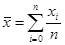 , , 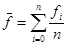 . .
2) Линейное сглаживание по трём точкам.
3) Линейное сглаживание по пяти точкам.
10. Решение нелинейных уравнений с одним неизвестным
Общие сведения о численном решении уравнений с одним неизвестным.
Пусть задана непрерывная функция f(x). Требуется найти корни уравнения f(x) = 0 численными методами – это и является постановкой задачи. Численное решение уравнения распадается на несколько подзадач:
1) Анализ количества, характера и расположения корней (обычно путем построения графика функции или исходя из физического смысла исследуемой модели). Здесь возможны следующие варианты:
· единственный корень;
· бесконечное множество решений;
· корней нет;
· имеется несколько решений, как действительных, так и мнимых (например, для полинома степени n). Корни четной кратности выявить сложно.
2) Локализация корней (разбиение на интервалы) и выбор начального приближения к каждому корню. В простейшем случае можно протабулировать функцию с заданным шагом.
Если в двух соседних узлах функция будет иметь разные знаки, то между этими узлами лежит нечетное число корней уравнения (по меньшей мере один).
3) Вычисление каждого (или интересующего нас) корня уравнения с требуемой точностью. Уточнение происходит с помощью методов, изложенных ниже.
Метод дихотомии (бисекций)

Иначе называется методом половинного деления. Пусть задан начальный интервал [x0
, x1
], на котором f(x0
)f(x1
) ≤ 0 (т.е. внутри имеется не менее чем один корень). Найдем x2
= ½ (x0
+ x1
) и вычислим f(x2
). Если f(x0
)f(x2
) ≤ 0, используем для дальнейшего деления отрезок [x0
, x2
], если > 0 – используем для дальнейшего деления отрезок [x1
, x2
], и продолжаем деление пополам.
Итерации продолжаются, пока длина отрезка не станет меньше 2ξ – заданной точности. Тогда середина последнего отрезка даст значение корня с требуемой точностью. В качестве иного критерия можно взять | f(x)| ≤ ξy
.
Скорость сходимости метода невелика, однако он прост и надежен. Метод неприменим к корням четной кратности. Если на отрезке несколько корней, то заранее неизвестно, к какому из них сойдется процесс.
Если на заданном интервале предполагается несколько корней, то существует возможность последовательно исключать найденные корни из рассмотрения. Для этого воспользуемся вспомогательной функцией
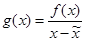
где  – только что найденный корень. Для функций f(x) и g(x) совпадают все корни, за исключением (в этой точке полюс функции g(x)). Для достижения требуемой точности рекомендуется грубо приблизиться к корню по функции g(x), а затем уточнить его, используя f(x). – только что найденный корень. Для функций f(x) и g(x) совпадают все корни, за исключением (в этой точке полюс функции g(x)). Для достижения требуемой точности рекомендуется грубо приблизиться к корню по функции g(x), а затем уточнить его, используя f(x).
Метод хорд.
Идея метода проиллюстрирована рисунком. Задается интервал [x0
, x1
], на котором f(x0
)f(x1
) ≤ 0, между точками x0
и x1
строится хорда, стягивающая f(x). Очередное приближение берется в точке x2
, где хорда пересекает ось абсцисс. В качестве нового интервала для продолжения итерационного процесса выбирается тот, на концах которого функция имеет разные знаки. Условия выхода из итерационного цикла:
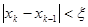 или или
f(x)| ≤ ξy
.
Для вывода итерационной формулы процесса найдем точку пересечения хорды (описываемой уравнением прямой) с осью абсцисс:
ax2
+ b = 0, где 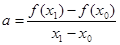 ; b = f(x0
) – ax0
. ; b = f(x0
) – ax0
.
Отсюда легко выразить 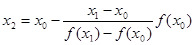
Метод хорд в большинстве случаев работает быстрее, чем метод дихотомии. Недостатки метода те же, что и в предыдущем случае.
Метод Ньютона (касательных).
Пусть x0
– начальное приближение к корню, а f(x) имеет непрерывную производную. Следующее приближение к корню найдем в точке x1
, где касательная к функции f(x), проведенная из точки (x0
, f0
), пересекает ось абсцисс. Затем точно так же обрабатываем точку (x1
, f1
), организуя итерационный процесс. Выход из итерационного процесса по условию

Уравнение касательной, проведенной из точки (x0
, f0
): y(x) = f /
(x0
)(x–x0
) + f(x0
) дает для y(x1
) = 0 следующее выражение:
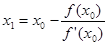 , (1) , (1)
Которое и используется для организации итерационного процесса. Итерации сходятся, только если всюду выполняется условие 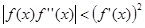 ; в противном случае сходимость будет не при любом начальном приближении, а только в некоторой окрестности корня. Итерации будут сходиться к корню с той стороны, с которой ; в противном случае сходимость будет не при любом начальном приближении, а только в некоторой окрестности корня. Итерации будут сходиться к корню с той стороны, с которой 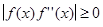 . .
Метод обладает самой высокой скоростью сходимости: погрешность очередного приближения примерно равна квадрату погрешности предыдущего приближения. Метод можно использовать для уточнения корней в области комплексных чисел, что необходимо при решении многих прикладных задач, например при численном моделировании электромагнитных колебательных и волновых процессов с учетом временной и пространственной диссипации энергии.
Недостатком метода можно указать необходимость знать явный вид первой и второй производных, так как их численный расчет приведет к уменьшению скорости сходимости метода. Иногда, ради упрощения расчетов, используют т.н. модифицированный метод Ньютона, в котором значение f /
(x) вычисляется только в точке x0
, при этом число итераций увеличивается, но расчеты на каждой итерации упрощаются.
Метод секущих.
В отличие от метода Ньютона, можно заменить производную первой разделенной разностью, найденной по двум последним итерациям, т.е. заменить касательную секущей. При этом первый шаг итерационного процесса запишется так:
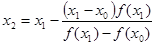
Для начала итерационного процесса необходимо задать x0
и x1
, которые не обязательно ограничивают интервал, на котором функция должна менять знак; это могут быть любые две точки на кривой. Выход из итерационного процесса по условию 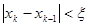
Сходимость может быть немонотонной даже вблизи корня. При этом вблизи корня может происходить потеря точности, т.н. «разболтка решения», особенно значительная в случае кратных корней. От разболтки страхуются приемом Гарвика: выбирают некоторое ξx
и ведут итерации до выполнения условия 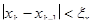 . Затем продолжают расчет, пока . Затем продолжают расчет, пока 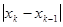 убывает. Первое же возрастание может свидетельствовать о начале разболтки, а значит, расчет следует прекратить, а последнюю итерацию не использовать. убывает. Первое же возрастание может свидетельствовать о начале разболтки, а значит, расчет следует прекратить, а последнюю итерацию не использовать.
Метод простых итераций.
Суть метода простых итераций в принципе совпадает с методом, изложенным для решения систем линейных алгебраических уравнений. Для нелинейного уравнения метод основан на переходе от уравнения
f(x) = 0 (2)
к эквивалентному уравнению x = φ (x). Этот переход можно осуществить разными способами, в зависимости от вида f(x). Например, можно положить
φ (x) = x + bf(x), (3)
где b = const, при этом корни исходного уравнения (2) не изменятся.
Если известно начальное приближение к корню x0
, то новое приближение x1
= φ (x0
), т.е. общая схема итерационного процесса:
xk
+1
= φ (xk
). (4)
Наиболее простой критерий окончания процесса 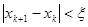 . .
Критерий сходимости метода простых итераций: если вблизи корня |φ/
(x)| < 1, то итерации сходятся. Если указанное условие справедливо для любого x, то итерации сходятся при любом начальном приближении. Исследуем выбор константы b в функции (3) с точки зрения обеспечения максимальной скорости сходимости. В соответствии с критерием сходимости наибольшая скорость сходимости обеспечивается при |φ/
(x)| = 0. При этом, исходя из (3), b = –1/f /
(x), и итерационная формула (4) переходит в
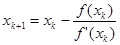
т.е. в формулу метода Ньютона (1). Таким образом, метод Ньютона является частным случаем метода простых итераций, обеспечивающим самую высокую скорость сходимости из всех возможных вариантов выбора функции φ (x).
11. Численное решение систем нелинейных уравнений
Постановка задачи.
Требуется решить систему нелинейных уравнений
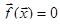 (1) (1)
В координатном виде эту задачу можно записать так:
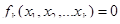
где 1 ≤ k ≤ n.
Убедиться в существовании решения и количестве корней, а также выбрать нулевое приближение в случае системы двух уравнений с двумя неизвестными можно, построив графики функций в удобных координатах. В случае сложных функций можно посмотреть поведение аппроксимирующих их полиномов. Для трех и более неизвестных, а также для комплексных корней, удовлетворительных способов подбора начального приближения нет.
Метод Ньютона.
Обозначим 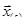 некоторое приближение к корню системы уравнений некоторое приближение к корню системы уравнений 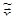 . Пусть малое . Пусть малое
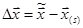
Вблизи 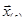 каждое уравнение системы можно линеаризовать следующим образом: каждое уравнение системы можно линеаризовать следующим образом:
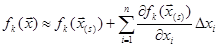 , 1 ≤ k ≤ n. (2) , 1 ≤ k ≤ n. (2)
Это можно интерпретировать как первые два члена разложения функции в ряд Тейлора вблизи  . В соответствии с (1), приравнивая (2) к нулю, получим: . В соответствии с (1), приравнивая (2) к нулю, получим:
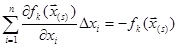 , 1 ≤ k ≤ n. (3) , 1 ≤ k ≤ n. (3)
Мы получили систему линейных уравнений, неизвестными в которой выступают величины 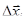 . Решив ее, например, методом Гаусса, мы получим некое новое приближение к . Решив ее, например, методом Гаусса, мы получим некое новое приближение к  , т.е. , т.е. 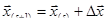 . Выражение (3) можно представить как обобщение на систему уравнений итерационного метода Ньютона, рассмотренного в предыдущей главе: . Выражение (3) можно представить как обобщение на систему уравнений итерационного метода Ньютона, рассмотренного в предыдущей главе:
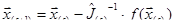 , (4) , (4)
где в данном случае
 – матрица Якоби, которая считается для каждого (s) приближения – матрица Якоби, которая считается для каждого (s) приближения
Критерием окончания итерационного процесса является условие 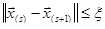 (Можем принять под (Можем принять под 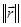 как норму как норму  , так и , так и 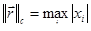 ). Достоинством метода является высокая скорость сходимости. Сходимость метода зависит от выбора начального приближения: если ). Достоинством метода является высокая скорость сходимости. Сходимость метода зависит от выбора начального приближения: если 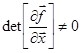 , то итерации сходятся к корню. Недостатком метода является вычислительная сложность: на каждой итерации требуется находить матрицу частных производных и решать систему линейных уравнений. Кроме того, если аналитический вид частных производных неизвестен, их надо считать численными методами. , то итерации сходятся к корню. Недостатком метода является вычислительная сложность: на каждой итерации требуется находить матрицу частных производных и решать систему линейных уравнений. Кроме того, если аналитический вид частных производных неизвестен, их надо считать численными методами.
Блок-схема метода Ньютона для решения систем нелинейных уравнений

Так как метод Ньютона отличается высокой скоростью сходимости при выполнении условий сходимости, на практике критерием работоспособности метода является число итераций: если оно оказывается большим (для большинства задач >100), то начальное приближение выбрано плохо.
Частным случаем решения (4) методом Ньютона системы из двух нелинейных уравнений
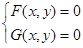
являются следующие легко программируемые формулы итерационного процесса:
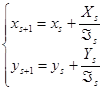 , где , где 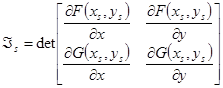 , ,
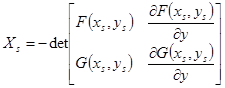 , , 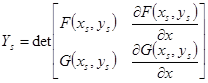
Метод простых итераций.
Метод простых итераций для решения (1) аналогичен методу, рассмотренному при решении нелинейных уравнений с одним неизвестным. Прежде всего, выбирается начальное приближение 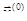 , а исходная система уравнений преобразуется к эквивалентной системе вида , а исходная система уравнений преобразуется к эквивалентной системе вида
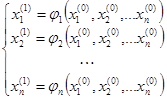 , (5) , (5)
и по ней осуществляется итерационный цикл. Если итерации сходятся, то они сходятся к решению уравнения (1). Обозначим
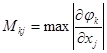
Достаточным условием сходимости является  . Скорость сходимости метода сильно зависит от вида конкретно подбираемых функций . Скорость сходимости метода сильно зависит от вида конкретно подбираемых функций 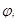 , которые должны одновременно удовлетворять условиям эквивалентности (5) и (1), и обеспечивать сходимость итерационного процесса. , которые должны одновременно удовлетворять условиям эквивалентности (5) и (1), и обеспечивать сходимость итерационного процесса.
Например, для исходной системы уравнений 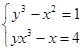 эквивалентная итерационная система (5) может быть представлена в следующем виде: эквивалентная итерационная система (5) может быть представлена в следующем виде:
 , ,
где множители 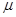 = –0.15и = –0.15и 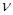 = –0.1 подбираются из анализа условий сходимости. = –0.1 подбираются из анализа условий сходимости.
Метод спуска.
Рассмотрим функцию
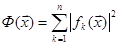
Она неотрицательна и обращается в нуль в том и только в том случае, если 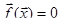 . То есть, если мы найдем глобальный минимум . То есть, если мы найдем глобальный минимум 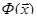 , то полученные значения , то полученные значения 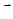 как раз и будут решениями уравнения (1). Подробнее о решении таких задач см. следующую главу. как раз и будут решениями уравнения (1). Подробнее о решении таких задач см. следующую главу.
12. Поиск минимума функций
Задачи поиска максимума эквивалентны задачам поиска минимума, так как требуется лишь поменять знак перед функцией. Для поиска минимума необходимо определить интервал, на котором функция могла бы иметь минимум. Для этого можно использовать (1) графическое представление функции, (2) аналитический анализ аппроксимирующей функции и (3) сведения о математической модели исследуемого процесса (т.е. законы поведения данной функции).
Численные методы поиска минимума функции одной переменной.
Определения.
Функция f(x) имеет локальный минимум при некотором 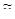 , если существует некоторая конечная ξ-окрестность этого элемента, в которой , если существует некоторая конечная ξ-окрестность этого элемента, в которой
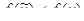 , , 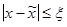
Требуется, чтобы на множестве X функция f(x) была по крайней мере кусочно-непрерывной.
Точка, в которой функция достигает наименьшего на множестве X значения, называется абсолютным минимумом функции. Для нахождения абсолютного минимума требуется найти все локальные минимумы и выбрать наименьшее значение.
Задачу называют детерминированной, если погрешностью вычисления (или экспериментального определения) функции f(x) можно пренебречь. В противном случае задачу называют стохастической. Все изложенные далее методы применимы только к детерминированным задачам.
Методы поиска минимума по нахождению корней уравнений.
Если функция f(x) аналитически дифференцируема, то решаем f /
(x) = 0 методами, изложенными в предыдущих главах. При этом условие f //
(x) > 0 в найденной точке указывает нам на минимум. Для использования этих методов необходимо знать либо аналитический вид первой и второй производных, либо рассчитать их численно, если это не приведет к потере точности.
Метод дробления

Наиболее простой метод поиска минимума. Пусть дана начальная точка x0
, а также величина и знак шага h, определяющие движение из этой точки в сторону предполагаемого минимума f(x). Метод заключается в последовательном дроблении исходного шага h с изменением его знака при выполнении условия f(xk
+1
) > f(xk
), где k – порядковый номер вычисляемой точки. Например, как только очередное значение функции стало больше предыдущего, выполняется h = – h/3 и процесс продолжается до тех пор, пока
|xk
+1
– xk
| ≤ ξ . (1)
Данный метод является одним из самых медленных для поиска минимума. Основное достоинство данного алгоритма – возможность использования в программах управления экспериментальными исследованиями, когда значения функции f(x) последовательно измеряются с шагом h ≥ hmin
.
Метод золотого сечения.
Пусть f(x) задана и кусочно-непрерывна на [xL
, xR
], и имеет на этом отрезке только один локальный минимум. Золотое сечение, о котором упоминал ещё Евклид, состоит в разбиении интервала [xL
, xR
] точкой x1
на две части таким образом, что отношение длины всего отрезка к его большей части равно отношению большей части к меньшей:
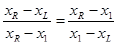 . (2) . (2)
Таким образом, возьмем на отрезке две точки x1
и x2
, симметрично относительно границ делящие исходный отрезок в отношении золотого сечения:
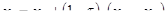 , ,
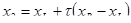 , ,
где коэффициент 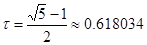
Если f(x1
) < f(x2
), мы должны сузить отрезок справа, т.е. новое значение xR
= x2
, в противном случае xL
= x1
. Оставшаяся внутри нового отрезка точка является первым приближением к минимуму и делит этот отрезок в отношении золотого сечения. Таким образом, на каждой итерации приближения к минимуму (см. рисунок) нам нужно ставить только одну точку (x1
или x2
), в которой считать значение функции и сравнивать его с предыдущим. Условием выхода из итерационного процесса будет, подобно предыдущему случаю, условие |x2
– x1
| ≤ ξ.
Метод отличается высокой скоростью сходимости, обычно изысканной компактностью программной реализации и всегда находит точку, минимальную на заданном интервале.
Метод парабол.
Пусть f(x) имеет первую и вторую производную. Разложим f(x) в ряд Тейлора в некоторой точке xk
, ограничиваясь при этом тремя членами разложения:
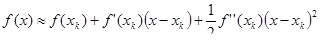 . (3) . (3)

Иными словами, аппроксимируем нашу функцию в точке xk
параболой. Для этой параболы можно аналитически вычислить положение экстремума как корень уравнения первой производной от (3):
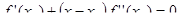
Пусть минимум аппроксимирующей параболы находится в точке xk
+1
. Тогда вычислив значение функции f(xk
+1
), мы получаем новую точку приближения к минимуму.
Обычно в практических реализациях данного метода не используют аналитический вид первой и второй производных f(x). Их заменяют конечно-разностными аппроксимациями. Наиболее часто берут симметричные разности с постоянным шагом h:
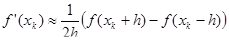 ; ;
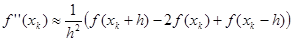
Это эквивалентно аппроксимации функции параболой, проходящей через три близкие точки xk
+h, xk
, xk
–h. Окончательное выражение, по которому можно строить итерационный процесс, таково:
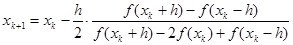 (4) (4)
Данный метод отличается от вышеизложенных высокой скоростью сходимости. Вблизи экстремума, вплоть до расстояний ~h2
, сходимость практически не отличается от квадратичной. Однако алгоритм требует постоянного контроля сходимости. Например, итерационный процесс будет сходиться к минимуму, если
1) знаменатель формулы (4) должен быть >0. Если это не так, нужно сделать шаг в обратном направлении, причем достаточно большой. Обычно в итерационном процессе полагают 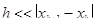 . Иногда ради упрощения расчетов полагают . Иногда ради упрощения расчетов полагают 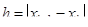 , однако это существенно уменьшает скорость сходимости. , однако это существенно уменьшает скорость сходимости.
2) 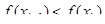 . Если это не так, то от xk
следует сделать шаг . Если это не так, то от xk
следует сделать шаг  с τ = ½. Если и при этом условие убывания не выполнено, уменьшают τ и вновь делают шаг. с τ = ½. Если и при этом условие убывания не выполнено, уменьшают τ и вновь делают шаг.
Численные методы поиска минимума функции нескольких переменных.
Будем рассматривать методы поиска минимума 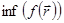 в многомерных задачах на примере функции двух переменных f(x, y), так как эти методы легко аппроксимировать на случай трех и более измерений. Все эффективные методы поиска минимума сводятся к построению траекторий, вдоль которых функция убывает. Разные методы отличаются способами построения таких траекторий, так как метод, приспособленный к одному типу рельефа, может оказаться плохим для рельефа другого типа. Различают следующие типы рельефа: в многомерных задачах на примере функции двух переменных f(x, y), так как эти методы легко аппроксимировать на случай трех и более измерений. Все эффективные методы поиска минимума сводятся к построению траекторий, вдоль которых функция убывает. Разные методы отличаются способами построения таких траекторий, так как метод, приспособленный к одному типу рельефа, может оказаться плохим для рельефа другого типа. Различают следующие типы рельефа:
| 1) Котловинный (гладкая функция)

|
2) Истинный овраг

|
3) Разрешимый овраг

|
4) Неупорядоченный

|
Метод координатного спуска

Пусть требуется найти минимум f(x, y). Выберем нулевое приближение (x0
, y0
). Рассмотрим функцию одной переменной f(x, y0
) и найдем ее минимум, используя любой из рассмотренных выше способов. Пусть этот минимум оказался в точке (x1
, y0
). Теперь точно так же будем искать минимум функции одной переменной f(x1
, y). Этот минимум окажется в точке (x1
, y1
). Одна итерация спусков завершена. Будем повторять циклы, постепенно приближаясь ко дну котловины, пока не выполнится условие
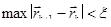

Сходимость метода зависит от вида функции и выбора нулевого приближения. Вблизи невырожденного минимума гладкой функции спуск по координатам линейно сходится к минимуму. Если линии уровня образуют истинный овраг, возможен случай, когда спуск по одной координате приводит на дно оврага, а любое движение по следующей координате ведет на подъем. Процесс координатного спуска в данном случае не сходится к минимуму. При попадании траектории спуска в разрешимый овраг сходимость становится чрезвычайно медленной. В физических задачах овражный рельеф указывает на то, что не учтена какая-то закономерность, определяющая связь между переменными. Явный учет этой закономерности облегчает использование численных методов.
Метод градиентного (наискорейшего) спуска.

В этом методе функция минимизируется по направлению, в котором она быстрее всего убывает, т.е. в направлении, обратном 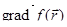 . Вдоль этого направления функция зависит от одной параметрической переменной t, для нахождения минимума которой можно воспользоваться любым известным методом поиска минимума функции одной переменной. Спуск из точки начального приближения . Вдоль этого направления функция зависит от одной параметрической переменной t, для нахождения минимума которой можно воспользоваться любым известным методом поиска минимума функции одной переменной. Спуск из точки начального приближения  против градиента до минимума t определяет новую точку против градиента до минимума t определяет новую точку 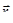 , в которой вновь определяется градиент и делается следующий спуск. Условием окончания процесса, как и в случае координатного спуска, будет , в которой вновь определяется градиент и делается следующий спуск. Условием окончания процесса, как и в случае координатного спуска, будет
С помощью метода градиентного спуска минимум гладких функций в общем случае находится быстрее, чем при использовании координатного спуска, однако нахождение градиента численными методами может свести на нет полученный выигрыш. Сходимость плохая для функций с овражным рельефом, т.е. с точки зрения сходимости градиентный спуск не лучше спуска по координатам.
Каждый спуск заканчивается в точке, где линия градиента касательна к линии (поверхности) уровня. Это означает, что каждый следующий спуск должен быть перпендикулярен предыдущему. Таким образом, вместо поиска градиента в каждой новой точке можно сосчитать градиент в начальной точке, и развернуть оси координат так, чтобы одна их осей была параллельна градиенту, а затем осуществлять спуск координатным методом.
Метод оврагов.

Ставится задача найти минимум  для овражной функции. Для этого выбираются две близкие точки для овражной функции. Для этого выбираются две близкие точки 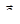 и и 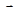 , и осуществляется спуск из этих точек (любым методом), причем высокой точности сходимости не требуется. Конечные точки спуска , и осуществляется спуск из этих точек (любым методом), причем высокой точности сходимости не требуется. Конечные точки спуска 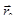 и будут лежать вблизи дна оврага. Затем осуществляется движение вдоль прямой, соединяющей и в сторону уменьшения (как бы вблизи дна оврага). Движение может быть осуществлено только на один шаг ~ h, направление выбирается из сравнения значения функции в точках и и будут лежать вблизи дна оврага. Затем осуществляется движение вдоль прямой, соединяющей и в сторону уменьшения (как бы вблизи дна оврага). Движение может быть осуществлено только на один шаг ~ h, направление выбирается из сравнения значения функции в точках и 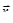 . Таким образом, находится новая точка . Таким образом, находится новая точка 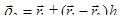 . Так как возможно, что точка . Так как возможно, что точка 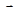 уже лежит на склоне оврага, а не на дне, то из нее снова осуществляется спуск в новую точку уже лежит на склоне оврага, а не на дне, то из нее снова осуществляется спуск в новую точку 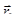 . Затем намечается новый путь по дну оврага вдоль прямой, соединяющей и . Если . Затем намечается новый путь по дну оврага вдоль прямой, соединяющей и . Если 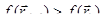 – процесс прекращается, а в качестве минимума в данном овраге используется значение – процесс прекращается, а в качестве минимума в данном овраге используется значение 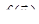 . .
Метод оврагов рассчитан на то, чтобы пройти вдоль оврага и выйти в котловину около минимума. В этой котловине значения минимума лучше уточнять другими методами.
Проблемы поиска минимума в задачах с большим числом измерений.
Пусть в n-мерном векторном пространстве задана скалярная функция . Наложим дополнительные условия 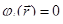 , 1 ≤ i ≤ m; , 1 ≤ i ≤ m; 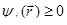 , 1 ≤ j ≤ p. Условия типа равенств выделяют в пространстве некоторую (n – m)-мерную поверхность, а условия типа неравенств выделяют n-мерную область, ограниченную гиперповерхностями , 1 ≤ j ≤ p. Условия типа равенств выделяют в пространстве некоторую (n – m)-мерную поверхность, а условия типа неравенств выделяют n-мерную область, ограниченную гиперповерхностями 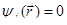 . Число таких условий может быть произвольным. Следовательно, задача inf есть поиск минимума функции n переменных в некоторой (n – m)-мерной области E. Функция может достигать минимального значения как внутри области, так и на ее границе. Однако перейти к (n – m)-мерной системе координат практически никогда не удается, поэтому спуск приходится вести во всем n-мерном пространстве. . Число таких условий может быть произвольным. Следовательно, задача inf есть поиск минимума функции n переменных в некоторой (n – m)-мерной области E. Функция может достигать минимального значения как внутри области, так и на ее границе. Однако перейти к (n – m)-мерной системе координат практически никогда не удается, поэтому спуск приходится вести во всем n-мерном пространстве.
Даже если нулевое приближение лежит в области E, естественная траектория спуска сразу выходит из этой области. Для принудительного возврата процесса в область E, например, используется метод штрафных функций: к прибавляются члены, равные нулю в E, и возрастающие при нарушении дополнительных условий (ограничений). Метод прост и универсален, однако считается недостаточно надежным. Более качественный результат дает использование симплекс-методов линейного программирования, однако данный вопрос в рамках настоящего курса не рассматривается.
13. Решение обыкновенных дифференциальных уравнений
Постановка задачи. Типы задач для ОДУ.
Известно, что с помощью дифференциальных уравнений можно описать задачи движения системы взаимодействующих материальных точек, химической кинетики, электрических цепей, и др. Конкретная прикладная задача может приводить к дифференциальному уравнению любого порядка, или к системе уравнений любого порядка. Так как любое ОДУ порядка p
u(
p
)
(x) = f(x, u, u/
, u//
, … u(
p
+1)
) заменой u(
k
)
(x) = yk
(x) можно свести к эквивалентной системе из p уравнений первого порядка, представленных в каноническом виде:
y/
k
(x) = yk
+1
(x) для 0 ≤ k ≤ p–2 (1)
y/
p-1
(x) = f(x, y0
, y1
, … yp–1
), при этом y0
(x) ≡ u(x). (2)
Покажем такое преобразование на примере уравнения Бесселя:
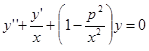
Предполагая тождественную замену y1
(x) ≡ y(x) представим систему ОДУ в следующем виде:
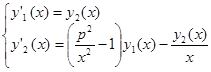
Аналогично произвольную систему дифференциальных уравнений любого порядка можно заменить некоторой эквивалентной системой уравнений первого порядка. Следовательно, алгоритмы численного решения достаточно реализовать для решения системы дифференциальных уравнений первого порядка.
Известно, что система p-го порядка имеет множество решений, которые в общем случае зависят от p параметров {C1
, C2
, … Cp
}. Для определения значений этих параметров, т.е. для выделения единственного решения необходимо наложить p дополнительных условий на uk
(x). По способу задания условий различают три вида задач, для которых доказано существование и единственность решения. Это
1) Задача Коши. Задается координата uk
(x0
) = uk
0
начальной точки интегральной кривой в (p+1) – мерном пространстве (k = 1…p). Решение при этом требуется найти на некотором отрезке x0
≤ x ≤ xmax
.
2) Краевая задача. Это задача отыскания частного решения системы ОДУ на отрезке a ≤ x ≤ b, в которой дополнительные условия налагаются на значения функции uk
(x) более чем в одной точке этого отрезка.
3) Задача на собственные значения. Кроме искомых функций и их производных в уравнение входят дополнительно m неизвестных параметров λ1
, λ2
, … λm
, которые называются собственными значениями. Для единственности решения на некотором интервале необходимо задать p+m граничных условий.
В большинстве случаев необходимость численного решения систем ОДУ возникает в случае, когда аналитическое решение найти либо невозможно, либо нерационально, а приближенное решение (в виде набора интерполирующих функций) не дает требуемой точности. Численное решение системы ОДУ, в отличие от двух вышеприведенных случаев, никогда не покажет общего решения системы, так как даст только таблицу значений неизвестных функций, удовлетворяющих начальным условиям. По этим значениям можно построить графики данных функций или рассчитать для некоторого x > x0
соотвествующие uk
(x), что обычно и требуется в физических или инженерных задачах. При этом требуется, чтобы соблюдались условия корректно поставленной задачи.
Метод Эйлера (метод ломаных).
Рассмотрим задачу Коши для уравнения первого порядка:
u/
(x) = f(x, u(x)), x0
≤ x ≤ xmax
, u(x0
) = u0
. (3)
В окрестности точки x0
функцию u(x) разложим в ряд Тейлора:
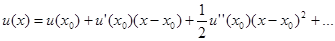 (4) (4)

Идея этого и последующих методов основывается на том, что если f(x,u) имеет q непрерывных производных, то в разложении можно удержать члены вплоть до O(hq
+1
), при этом стоящие в правой части производные можно найти, дифференцируя (3) требуемое число раз. В случае метода Эйлера ограничимся только двумя членами разложения.
Пусть h – малое приращение аргумента. Тогда (4) превратится в
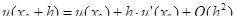
Так как в соответствии с (3) u/
(x0
) = f(x0
, u0
), то
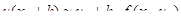
Теперь приближенное решение в точке x1
= x0
+ h можно вновь рассматривать как начальное условие, т.е. организуется расчет по следующей рекуррентной формуле:
 (5) (5)
где y0
= u0
, а все yk
– приближенные значения искомой функции (см. рисунок). В методе Эйлера происходит движение не по интегральной кривой, а по касательной к ней. На каждом шаге касательная находится уже для новой интегральной кривой (что и дало название методу – метод ломаных), таким образом ошибка будет возрастать с отдалением x от x0
.
При  приближенное решение сходится к точному равномерно с первым порядком точности. То есть, метод дает весьма низкую точность вычислений: погрешность на элементарном шаге h составляет ½ h2
y//
( ½(xk
+ xk
+1
)), а для всей интегральной кривой порядка h1
. При h = const для оценки апостериорной погрешности может быть применена первая формула Рунге, хотя для работы метода обеспечивать равномерность шага в принципе не требуется. приближенное решение сходится к точному равномерно с первым порядком точности. То есть, метод дает весьма низкую точность вычислений: погрешность на элементарном шаге h составляет ½ h2
y//
( ½(xk
+ xk
+1
)), а для всей интегральной кривой порядка h1
. При h = const для оценки апостериорной погрешности может быть применена первая формула Рунге, хотя для работы метода обеспечивать равномерность шага в принципе не требуется.
Метод Эйлера легко обобщается для систем ОДУ. При этом общая схема процесса (5) может быть записана так:
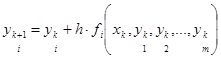 (6) (6)
где i = 1…m – число уравнений, k – номер предыдущей вычисленной точки.
Усовершенствованный метод Эйлера-Коши с уточнением.
Данный метод базируется на предыдущем, однако здесь апостериорная погрешность контролируется на каждом шаге вычисления. Как и в предыдущем случае, рассматриваем задачу Коши на сетке с постоянным шагом h. Грубое значение  вычисляется по формуле (5) и затем итерационным циклом уточняется по формуле вычисляется по формуле (5) и затем итерационным циклом уточняется по формуле
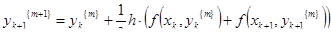 (7) (7)
где m – номер итерации. Итерационный цикл повторяется до тех пор, пока 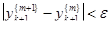 . Данная формула также легко обобщается на решение систем ОДУ. Априорная погрешность метода при m = 1 на каждом шаге порядка h3
. . Данная формула также легко обобщается на решение систем ОДУ. Априорная погрешность метода при m = 1 на каждом шаге порядка h3
.
Блок-схема метода Эйлера-Коши с уточнением

Метод Рунге-Кутты II порядка
Увеличение точности решения ОДУ из предыдущей задачи при заданном шаге h может быть достигнуто учетом большего количества членов разложения функции в ряд Тейлора. Для метода Рунге-Кутты второго порядка следует взять три первых коэффициента, т.е. обеспечить:
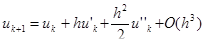 (8) (8)
Переходя к приближенному решению y ≈ u и заменяя производные в (8) конечными разностями, получаем в итоге следующее выражение:
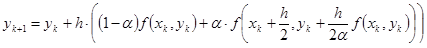 , (9) , (9)
где 0 ≤ α ≤ 1– свободный параметр. Можно показать, что если f(x,u) непрерывна и ограничена вместе со своими вторыми производными, то решение, полученное по данной схеме, равномерно сходится к точному решению с погрешностью порядка h2
.
Для параметра α наиболее часто используют следующие значения:

1) α = 1. В этом случае
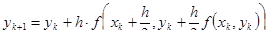
Графически это уточнение можно интерпретировать так: сначала по схеме ломаных делается шаг h/2, и находится значение
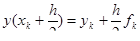
В найденной точке определяется наклон касательной к интегральной кривой, который и будет определять приращение функции для целого шага, т.е. отрезок [AB] (см. рисунок) будет параллелен касательной, проведенной в точке (xk
+ h/2, y(xk
+ h/2) ) к интегральной кривой.
2) α = ½. В этом случае
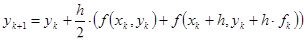
Можно представить, что в этом случае по методу Эйлера сначала вычисляется значение функции и наклон касательной к интегральной кривой в точке xk
+1
. Затем находится среднее положение касательной из сравнения соответствующих наклонов в точках xk
и xk
+1
, которое и будет использоваться для расчета точки yk
+1
.
Метод Рунге-Кутты IV порядка.
Данная схема является наиболее употребительной. Здесь в разложении функции в ряд Тейлора учитываются члены до h4
включительно, т.е. погрешность на каждом шаге пропорциональна h5
. Для практических вычислений используются следующие соотношения, обобщенные в данном случае на решение системы ОДУ:
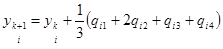
где i = 1…p, p – число уравнений в системе
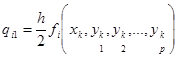
k – номер точки, для которой осуществляется расчет
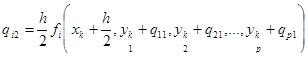 ; ;
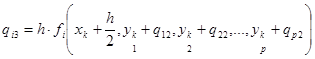 ; ;
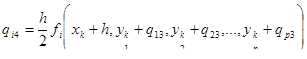
К достоинствам метода следует отнести высокую точность вычислений. Схемы более высокого порядка точности практически не употребляются в силу своей громоздкости. Также немаловажно, что метод является явным, т.е. значение yk
+1
вычисляется по ранее найденным значениям за известное заранее число действий.
Все представленные выше схемы допускают расчет с переменным шагом. Например, шаг можно уменьшить там, где функция быстро изменяется, и увеличить в обратном случае. Так, метод Рунге-Кутты-Мерсона позволяет оценивать погрешность на каждом шаге и, в зависимости от полученной оценки принимать решение об изменении шага. Автоматический выбор шага позволяет значительно сократить время вычислений.
Метод Рунге – Кутта - Мерсона.
Этот метод отличается от метода Рунге – Кутта четвертого порядка возможностью оценивать погрешность на каждом шаге и в зависимости от этого принимать решение об изменении шага. Один из вариантов формул:
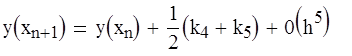
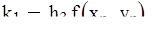 ; ; 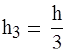
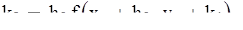
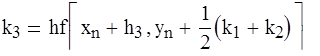
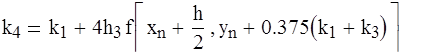
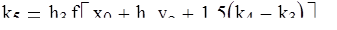
Rn
+1
= 0.2k4
– 0.3k3
– 0.1k5
- погрешность на каждом шаге.
Пусть задана максимальна погрешность 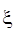 . Если . Если 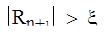 , h = h/2 , и n+1 цикл расчета повторяется (с точки xn
, yn
) c новым шагом. Если же , h = h/2 , и n+1 цикл расчета повторяется (с точки xn
, yn
) c новым шагом. Если же
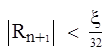 , h = 2h , h = 2h
Автоматический выбор шага позволяет значительно сократить время решения ОДУ.
Схема РКМ обобщается на системы ОДУ аналогично классической схеме Рунге – Кутта.
Метод Адамса.
Метод основан на аппроксимации интерполяционными полиномами правых частей ОДУ.
Пусть с помощью любого из методов, рассмотренных выше, вычислено решение заданного дифференциального уравнения в точках x1
, x2
, x3
(а в точке x0
решение и так известно – поставлена задача Коши). Полученные значения функции обозначим как y0
, y1
, y2
, y3
, а значения правой части дифференциального уравнения как f0
, f1
, f2
, f3
, где fk
= f(xk
, yk
). Начиная с четвертой точки, на каждом шаге интегрирования дифференциального уравнения вычисления осуществляются по схеме
P(EC){
m
}
E
где P – прогноз решения; Е – вычисление f(x,y); С – коррекция решения; m – количество итераций коррекции. Схемы такого типа называют «прогноз-коррекция»: это подразумевает сначала приблизительное вычисление решение по формуле низкого порядка, а затем уточнение с учетом полученной информации о поведении интегральной кривой.
Прогноз осуществляется по экстраполяционной формуле Адамса:
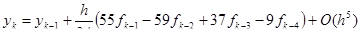 . (10) . (10)
Коррекция осуществляется по интерполяционной формуле Адамса:
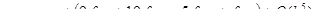 . (11) . (11)
Вычисление осуществляется по формуле:
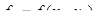
Количество итераций m ≤ p, где p – порядок используемого метода. В ходе каждой итерации решается нелинейное уравнение (11) относительно неизвестной y4
(обычно методом простых итераций).
Иногда в методе Адамса используется схеме PECE на каждом шаге процесса интегрирования, т.е. осуществляется только одна коррекция. В силу сложности вычислений метод используется только в мощных программных пакетах численного анализа. Формулы метода также легко переносятся на решение систем ОДУ первого порядка.
Постановка краевой задачи. Метод стрельбы.
Краевая задача – задача отыскания частного решения системы
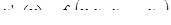 (12) (12)
1 ≤ k ≤ p, на отрезке a ≤ x ≤ b, на котором дополнительные условия налагаются на значения функции uk
(x) более чем в одной точке этого отрезка. В качестве примера моно привести задачу нахождения статического прогиба u(x) нагруженной струны с закрепленными концами:
 , a ≤ x ≤ b, u(a) = u(b) = 0 , a ≤ x ≤ b, u(a) = u(b) = 0
Здесь f(x) имеет смысл внешней изгибающей нагрузки на единицу длины струны, деленной на упругость струны.
Найти точное решение краевой задачи в элементарных функциях удается редко: для этого надо найти общее решение системы (12) и суметь явно определить из краевых условий значения входящих в него постоянных. Одним из методов, предполагающих численное решение поставленной задачи, является метод стрельбы, в котором краевая задача для системы (12) сводится к задаче Коши для той же системы.
Рассмотрим систему двух дифференциальных уравнений первого порядка
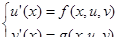 (13) (13)
с краевыми условиями
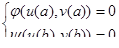 (14) (14)
Сначала выберем некоторое значение  , так что , так что 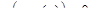 . Это уравнение мы можем решить и определить . Это уравнение мы можем решить и определить 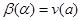 . Таким образом у нас появились два числа . Таким образом у нас появились два числа  и β, которые будут определять задачу Коши и β, которые будут определять задачу Коши 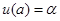 , ,  для системы (13), удовлетворять левому краевому условию, но не удовлетворять второму уравнению (14). Тем не менее, решим систему ОДУ с задачей Коши каким-либо из известных нам численных методов. Получим решение вида для системы (13), удовлетворять левому краевому условию, но не удовлетворять второму уравнению (14). Тем не менее, решим систему ОДУ с задачей Коши каким-либо из известных нам численных методов. Получим решение вида
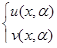 (15) (15)
зависящее от как от параметра.
Теперь мы должны каким-либо способом менять параметр до тех пор, пока не подберется такое значение, для которого будет выполнено условие  (16), т.е. правое краевое условие. Для этого случайным образом берут значения (16), т.е. правое краевое условие. Для этого случайным образом берут значения  до тех пор, пока среди величин до тех пор, пока среди величин  не окажется разных по знаку. не окажется разных по знаку.
Если это осуществилось, пара таких значений определяет интервал 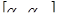 , который можно обработать методом дихотомии до получения корня уравнения (16). Нахождение каждого нового значения функции (16) требует нового численного интегрирования для решения ОДУ, что делает этот метод достаточно медленным. , который можно обработать методом дихотомии до получения корня уравнения (16). Нахождение каждого нового значения функции (16) требует нового численного интегрирования для решения ОДУ, что делает этот метод достаточно медленным.
Решение уравнений в частных производных.
К уравнениям в частных производных приводят задачи газодинамики, теплопроводности, переноса излучения, электромагнитных полей, процессов переноса в газах, и др. Независимыми переменными в физических задачах обычно являются время t, координаты 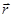 , скорости частиц , скорости частиц 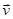 . Пример – уравнение теплопроводности . Пример – уравнение теплопроводности
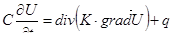 (17) (17)
где U – температура, 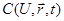 – теплоемкость, – теплоемкость, 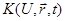 – коэффициент теплопроводности, q – плотность источников тепла. – коэффициент теплопроводности, q – плотность источников тепла.
Для решения дифференциальных уравнений в частных производных применяется сеточный метод, суть которого – в разбиении области, в которой ищется решение, сеткой узлов заданной конфигурации, после чего составляется разностная схема уравнения и находится его решение, например методом разностной аппроксимации.
Рассмотрим в качестве примера одномерную задачу, близкую по смыслу к (17):
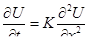 . (18) . (18)
Здесь 0 ≤ x ≤ a, 0 ≤ t ≤ T.
Граничные условия:
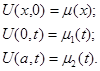
Для одной и той же задачи можно составить много разностных схем. Метод разностной аппроксимации заключается в том, что каждая производная, входящая в дифференциальное уравнение и краевые условия, заменяется разностным выражением, включающим в себя только значения в узлах сетки.
Введем равномерную прямоугольную сетку по x и t с шагом h и τ соответственно и заменить производные соответствующими разностными отношениями. Тогда
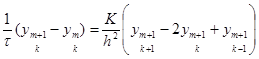 . (19) . (19)
Здесь 1 ≤ k ≤ N-1 – число точек по координате x; 0 ≤ m ≤ M – число точек по координате t. Число неизвестных в (19) больше числа уравнений, недостающие уравнения выводятся из начальных и граничных условий:
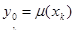 ; 0 ≤ k ≤ N. ; 0 ≤ k ≤ N.
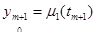 ; ; 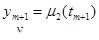 ; 0 ≤ m ≤ M. ; 0 ≤ m ≤ M.
Схема (19) содержит в каждом уравнении несколько неизвестных значений функции. Такие схемы называют неявными. Для фактического вычисления решения следует переписать схему так:
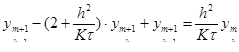 , где 1 ≤ k ≤ N-1. , где 1 ≤ k ≤ N-1.
; . (20)
Теперь схема представляет собой систему линейных уравнений для определения величин  ; правые части этих уравнений известны, поскольку содержат значения решений для предыдущего индекса времени. ; правые части этих уравнений известны, поскольку содержат значения решений для предыдущего индекса времени.
Другим вариантом решения сеточной задачи является использование интегро-интерполяционных методов (методов баланса), в которых дифференциальное уравнение интегрируют по ячейке сетки, приближенно вычисляя интегралы по квадратурным формулам.
Приложение 1
Случайные величины в компьютерном моделировании.
Параметры случайных величин.
Величину ξ называют случайной с плотностью распределения ρ(x), если вероятность того, что величина примет значения между x1
и x2
, равна
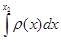
Псевдослучайные распределения. Иллюстрация возможностей Mathcad.
Моделирование броуновского движения в системе MathLab.
Литература
1. Н. Бахвалов, Н. Жидков, Г. Кобельков. Численные методы. М., 2002, 632
2. Н. Калиткин. Численные методы. М., 1972,
3. А. Мудров. Численные методы для ПЭВМ на языках Бейсик, Фортран и Паскаль. Томск, 1992, 270с.
4. А. Самарский. Введение в численные методы. М., , 270с.
5. Ю. Тарасевич. Численные методы на Mathcad’е. Астрахань, 2000, 70с.
6. Г. Коткин, В. Черкасский. Компьютерное моделирование физических процессов с использованием MathLab. Новосибирск, 2001.
7. М. Лапчик, М. Рагулина, Е. Хеннер. Численные методы.М., 2004, 384с.
Во всех делах твоих помни о конце твоем и во век не согрешишь. Библия, «Книга Премудрости Иисуса, сына Сирахова» (некан.), 7, 39
|