МИНИСТЕРСТВО ОБРАЗОВАНИЯ И НАУКИ РФ
__________
ФЕДЕРАЛЬНОЕ АГЕНСТВО ПО ОБРАЗОВАНИЮ
Московский авиационный институт
(государственный технический университет)
__________________________________________________________________________
Кафедра 402
РЕФЕРАТ
Дисциплина: «Информационная безопасность и защита информации»
Тема: «Вокодеры с линейным предсказанием»
Группа: КТ-515
Студент:___________ /Грачев А.А. /
Преподаватель: доц. каф. 402
_________ /Большов О.А./
Москва, 2010 г.
Оглавление
Перечень условных обозначений…………………………………………………………….. 3
В
ведение
………………………………………………………………………………………. 5
Глава 1. Понятие «вокодер». Устройство и основные функции вокодера с линейным предсказанием
………………………………………………………………………………... 6
1.1. Физическое обоснование…………………………………...…………………………... 7
1.2. Вокодеры с линейным предсказанием (липредеры).
.…………………………………10
1.3. Принцип метода линейного предсказания..…………………………………………... 12
Глава 2: Способы преобразования информации в вокодерах с линейным предсказанием
…….…………………………………………………………………………. 15
2.1. Преобразование коэффициентов…….………………………………………………… 15
2.2. Кодирование и декодирование…
………………………………………………………. 16
2.3. Передача параметров с переменной скоростью .........……….……………………….. 19
2.4. Возбуждение синтезатора и выбор коэффициента усиления ……………………….. 20
Глава 3: Виды липредеров на примере устройств с низкой скоростью передачи информации
…………………….…………………………………………………………….. 23
3.1. Липредеры на основе ковариационного метода ……………..………………………. 24
Глава 4:
Методы анализа речи на основе использования вокодеров с линейным предсказанием
……………………………………………………………………………….. 29
Глава 5:
Кодеки
………………………………………………………………………………. 34
Глава 6:
Вокодеры в современности
……....……………………………………………… 41
Заключение
………………………………………………………………………………...... 44
Список используемой литературы
……………………………………………………...... 45
Перечень основных условных обозначений.
АДИКМ
– адаптивно-дифференциальная импульсно-кодовая модуляция;
ВОТ
– выделитель основного тона;
ГОТ
– генератор основного тона;
ГШ
– генератор шума;
ДИКМ
– дифференциальная импульсно-кодовая модуляция;
ИКМ
– импульсно-кодовая модуляция;
КС
– канал связи;
МККТТ
– Международный консультационный комитет по телефонии и телеграфии;
МСЭ
– Международный союз электросвязи;
НЧ
– низко-частотный;
ОТ
– основной тон;
ПЗУ
– постоянное запоминающее устройство;
Т-Ш
– «тон-шум»;
УО
– устройство объединения сигналов;
УР
– устройство разделения сигналов;
ФНЧ
– фильтр низких частот;
ЦАП
– цифро-аналоговый преобразователь;;
ЦПОС
– цифровые процессоры обработки сигналов;
ACELP
– англ. Algebraic Code Excited Linear Prediction -
возбуждениеоталгебраическогокода;
ADPCM
– aнгл. Adaptive differential
pulse-code
modulation
-
адаптивно-дифференциальнаяимпульсно-кодоваямодуляция;
CELP
–англ., Code Excited Linear Predictive
– возбуждениеоткода;
CS-ACELP
- Conjugate Structure - Algebraic Code Excited Linear Prediction
- сопряженнаяструктурасуправляемымалгебраическимкодомлинейнымпредсказанием;
DSP
-
Digital
Signal
Processor
- специализированные цифровые сигнальные процессоры;
GSM
- (от названия группы Groupe
Sp
é
cial
Mobile
, позже переименован в GlobalSystemforMobileCommunications) (русск.
СПС-900) — глобальный цифровой стандарт для мобильной сотовой связи;
ITU
– англ.International Telecommunication Union
– Международныйсоюзэлектросвязи;
LD-CELP
– англ. Low Delay - Code Excited Linear Prediction
- линейноепредсказаниескодовымвозбуждениеми низкойзадержкой;
LPC
– англ., Linear
Predictive
Coding
– кодирование с линейным предсказанием;
LSF
- linear
spectral
frequency
-
линейныеспектральныечастоты;
MIPS
- Million Instructions Per Second
- миллионоперацийвсекунду;
MOS
– aнгл. Mean Opinion Score -
средняясубъективнаяоценка;
MPELP
– англ., Multi Pulse Excited Linear Predictive
– многоимпульсноевозбуждение;
MP-MLQ
- Multy-Pulse - Multy Level Quantization
- множественное импульсное;
PCM
– aнгл. Pulse
Code
Modulation
–
импульснаякодоваямодуляция;
QDU
- Quantization Distortion Units
- параметры ухудшения качества сигнала при квантовании;
RELP
–англ., Residual
Excited
Linear
Predictive
– возбуждение от остатка предвидения;
VAD
- Voice Activity Detector
- детектор активности источника речевого сигнала
многоуровневое квантование.
Введение
Вокодеры – это системы параметрического кодирования речи, широко применяемые в современной цифровой телефонной связи, в том числе – Internet-телефонии. Причиной тому – высокая степень сжатия информации, а также хорошая согласованность вокодеров с системами канального кодирования и шифрования, в результате чего сравнительно легко обеспечивается высокая защищенность систем связи от помех и утечки информации. Недостатком вокодеров является невысокое качество речи, поэтому они применяются главным образом в военной связи, где главное – не натуральность речи, а ее высокая степень сжатия и хорошая разборчивость. В коммерческих системах связи, где ценится натуральность звучания речи, обычно применяют полувокодеры (гибридные вокодеры), сочетающие принципы непараметрического и параметрического методов кодирования. Иные области применения вокодеров – автоматизированная стенография, озвучивание текста, человеко-машинный диалог, биометрия (идентификация диктора).
Знакомясь с современным состоянием вокодерных технологий по литературным источникам и ресурсам Internet, можно выделить следующие области примениения вокодеров:
· программные и программно-аппаратные разработки вокодеров для промышленного, военного и бытового применения;
· программные экспериментальные вокодеры;
· другие перспективные и интересные направления.
Глава 1: Понятие «вокодер». Устройство и основные функции вокодера с линейным предсказанием.
Устройства для параметрического частотного сжатия речи получили название вокодеров.
Вокодер
(от англ. voice - голос и coder – кодировщик голоса) представляет собой устройство (или алгоритм), осуществляющее параметрическое компандирование речевого сигнала.
Компандирование
- способ преобразования речевого сигнала, при котором на передающем конце тракта происходит сжатие по одному или нескольким измерениям (частотный диапазон, динамический диапазон, временной интервал), а на приёмном - восстановление первоначального объёма сигнала путём соответствующего расширения. Компандирование включает преобразования: компрессию (сжатие) и декомпрессию (восстановление) речевого сигнала.
Общий принцип действия вокодера любой системы поясняется на рис. 1.
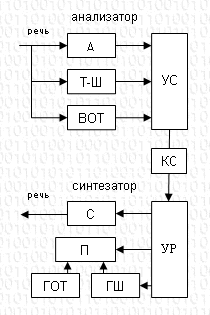 |
Анализатор
А - анализатор спектра
Т-Ш - выделитель сигнала тон-шум
ВОТ - выделитель основного тона
УО - устройство объедин. сигналов
КС - канал связи
Синтезатор
УР - устройство разъед. сигналов
С - синтезатор спектра
П - переключатель вида спектра
ГОТ - генератор основного тона
ГШ - генератор шума
|
Рис. 1.
Обобщенная блок-схема вокодера
Главными частями вокодерного тракта является анализатор, который осуществляющий выделение параметров речевого сигнала, система передачи, обеспечивающая прохождение информации об этих параметрах через канал связи в узкой полосе частот, и синтезатор, восстанавливающий первообразный речевой сигнал.
Анализатор вокодера состоит из устройства для выделения параметров речевого сигнала A1,A2,...,Ak и схемы выделения основного тона(тон(F0) или шум).
1.1.
Физическое обоснование.
Работа вокодера (voice coder) основана на анализе характерных особенностей человеческой речи. На рис. 2 показаны условно частотные характеристики речи как функция от времени.

Рис. 2.
Пример распределения энергии в частотных диапазонах
На рисунке изображены частотные полосы (от 0 до 1 КГц, от 1 КГц до 2 КГц и т. д.) и распределение энергии по ним при произнесении фразы.
Как видно из рисунка, энергия распределяется во времени только в некоторых частотных диапазонах и различается по величине. Отдельные пики энергии, возникающие в одном частотном диапазоне, называются фонемами.
Эта картина может изменяться в больших диапазонах, в зависимости от тембра голоса и особенностей произношения, но нам сейчас важно рассмотреть общие закономерности построения. На рисунке видно, что буквы отличаются не только частотным диапазоном, но и структурой. Для каждого звука характерны пики (резонансы) энергии в определенных частотных диапазонах и провалы в других. Частоты, на которых в данный момент возникают комбинации пиков (фонем), называются "частотами формант" или просто "формантами". Гласные и звонкие согласные звуки речи содержат обычно от трех до четырех формант. Эти свойства и иллюстрируются рис. 2.
Изображенная "спектрограмма" представляет собой распределение энергии речи в виде функции времени и частоты. Горизонтальная ось представляет время, вертикальная — частоту, уровень энергии условно показан частью синусоиды. Периоды между сменами формант составляют от 10 до 30 мс. Изучение образцов речи показало, что в русском языке содержится 42 фонемы: это 6 гласных звуков и остальные согласные. Чтобы закодировать их номера, достаточно 6 битов.
Человек в среднем произносит в секунду 10 звуков. То есть от центральной нервной системы к речевому аппарату сигналы передаются со скоростью 10 [log2±2] = 60 бит/c. Это вычисление порождает иллюзию, что речь имеет небольшой объем информации и может быть передана с небольшой скоростью. Однако если рассмотреть подробнее, как образуется звук, то можно обнаружить, что при передаче речи требуется передать больше информации. При разговоре грудная клетка сжимается и расширяется, поток воздуха проходит через трахею и гортань в полости глотки, рта и носа. Голосовой тракт простирается от голосовой щели (отверстие между голосовыми складками гортани) до губ и в процессе речи его форма меняется. Если произносятся звонкие звуки (гласные, носовые, звонкие согласные), называемые также вокализованными (voiced), голосовые складки в гортани смыкаются и размыкаются с частотой, которая называется частотой основного тона (pitch). Получается последовательность импульсов воздушного потока, которые возбуждают полости голосового тракта. В процессе разговора человек меняет геометрические размеры этих полостей, соответственно меняются и резонаторные частоты, "форманты".
При произнесении глухих невокализированных (unvoiced) звуков голосовые связки расслаблены. Проходя по суженному голосовому тракту, воздух создает турбулентный поток (завихрение), т.е. в полости рта и носа возбуждаются шумоподобные сигналы. Взрывные (смычные, stop) звуки получаются путем кратковременного выхлопа — полного перекрытия речевого тракта, нагнетания давления и внезапного открытия тракта. Взрывные звуки бывают звонкие (б, д, г) и глухие (п, т, к), т.е. могут образовываться с участием голосовых складок и без них. Таким образом, в терминах спектра сигналов, когда человек говорит, он производит спектральновременную модуляцию широкополосного сигнала, генерируемого голосовыми складками и представляющего своего рода несущую. Полезная информация содержится только в интонации (изменении частоты основного тона) и в смене спектра с тонального на шумовой и наоборот.
Линейная модель речеобразования представляет речь как систему, состоящую из генератора возбуждения (генераторная функция) и линейной системы с медленно изменяющимися параметрами (фильтровая функция), которая им возбуждается. В такой модели не учитывается взаимное влияние голосовой щели и голосового тракта. Это не соответствует действительности, зато сильно упрощает анализ и синтез. Для экономичной передачи и хранения речи надо определить параметры генераторной и фильтровой функций. В генераторной функции изменяется частота и амплитуда основного тона (высота и громкость голоса) и происходит смена вида функции (основной тон или шум). У фильтровой функции происходит постоянное изменение коэффициента передачи, проявляющееся в изменении огибающей спектра.
Эта модель представляет речь человека, который "гудит" на одной частоте, периодически изменяя ее на другую и меняя громкость, а основная информация "добавляется" в "подтонах".
Рассматриваемые ранее принципы и реализующая их аппаратура были предназначены в первую очередь для воспроизведения формы входного сигнала на приеме как можно точнее в форму сигнала на выходе приемной стороны. Ниже рассмотрим принципы построения аппаратуры, которая моделирует человеческую речь, используя при этом методы цифрового кодирования. Они называются вокодеры (это слово получено объединением двух английских слов voice coder — кодер речевого сигнала).
По принципу определения параметров фильтровой функции различают следующие типы вокодеров:
· канальные (полосовые, channel);
· формантные;
· ортогональные;
· вокодеры с линейным предсказанием (липредеры — с линейным предсказанием речи).
Ранее вокодеры выполнялись только на основе аналоговой техники на протяжении всего разговорного тракта. Теперь наиболее распространена цифровая техника.
В упрощенном виде вышесказанное выглядит таким образом:
В формировании того или иного звука речи человека участвует та или иная часть этих элементов. Если звук формируется с участием голосовых связок, поток воздуха из легких вызывает их колебание, что порождает звуковой гон. Последовательность формируемых таким образом звуков составляет тоновую речь (или тоновый сегмент речи). Если звук формируется безучастия связок, тон в нем отсутствует, и последовательность таких звуков составляет нетоновую речь (нетоновый сегмент речи). Спектр тонового звука может быть смоделирован путем подачи специальным образом сформированного сигнала возбуждения на вход цифрового фильтра с параметрами, определяемыми несколькими действительными коэффициентами. Спектр нетоновых звуков - практически равномерный, что обусловлено их шумовым характером.
В реальных речевых сигналах не все звуки можно четко разделить на тоновые и нетоновые, а приходится иметь дело с некими переходными вариантами, что затрудняет создание алгоритмов кодирования, обеспечивающих высокое качество передачи речи при низкой скорости передачи информации.
Описанный принцип кодирования получил название LPC (Linear Prediction Coding - кодирование с линейным предсказанием
), поскольку центральным элементом модели голосового тракта является линейный фильтр. Наиболее известный стандартный алгоритм, построенный по описанному принципу, был стандартизован министерством обороны США под названием LPC-10, где число 10 соответствует количеству коэффициентов фильтра. Данный кодер обеспечивает очень низкую скорость передачи информации 2.4 Кбит/с, однако качество воспроизводимых речевых сигналов оставляет желать лучшего и не удовлетворяет требованиям коммерческой речевой связи - речь носит ярко выраженный «синтетический» характер.
В следующих главах детально разберем вокодеры с линейным предсказанием, принципы их устройства, различные методы их работы, области применения и другие аспекты. Также будет затронута тема кодеков, базирующихся на использовании вокодеров.
1.2 Вокодеры с линейным предсказанием (липредеры).
Этот тип вокодера (рис. 3, рис. 4), в отличие от остальных типов, для передачи речи применяет не фильтры, а систему линейного предсказания. В линию передается разностный сигнал между истинным и предсказанным значениями. Коэффициенты предсказания используются для предсказания управлением, восстанавливающим генератором на приеме и добавления генератором шума для передачи глухих и "свистящих" согласных.

Рис. 3.
Схема передающей части вокодера с линейным предсказанием

Рис. 4.
Схема приемной части вокодера с линейным предсказанием
Вокодеры данного типа работают уже с целыми блоками подготовленных отсчетов. Для каждого такого блока значений вычисляются его характерные параметры: частота, амплитуда и ряд других. Затем из значений этих параметров формируется речевой кадр, готовый для передачи. При таком подходе к кодированию речи, во-первых, возрастают требования к вычислительным мощностям ЦПОС, а во-вторых, увеличивается задержка при передаче, поскольку кодирование применяется не к отдельным значениям, а к некоторому их набору, который перед началом преобразования следует накопить в определенном буфере (см. рис. 5).

Рис.5.
Схема функционирования вокодера на основе метода линейного предсказания речи.
Более сложные методы сжатия речи основаны на применении метода линейного предсказания речи в сочетании с элементами кодирования формы сигнала. В этих алгоритмах используется кодирование с обратной связью, когда при передаче сигнала осуществляется оптимизация кода. Закодировав сигнал, процессор пытается восстановить его форму и сравнивает результат с исходным сигналом, после чего начинает варьировать параметры кодирования, добиваясь наилучшего совпадения. Достигнув такого совпадения, аппаратура передает полученный код по линиям связи. На противоположном конце происходит восстановление речевого сигнала. Ясно, что для использования такого метода требуются серьезные вычислительные мощности.
1.3 Принцип метода линейного предсказания.
В вокодерах с линейным предсказанием при анализе речевого сигнала в передающем устройстве определяются коэффициенты предсказания, а в приемном устройстве на основе этих коэффициентов с помощью рекурсивного цифрового фильтра синтезируется эквивалент голосового тракта.
Принцип метода линейного предсказания состоит в том, что прогнозируемая величина речевого сигнала (Pic) в момент выборки h
определяется как линейно взвешенная сумма значений сигнала в моменты предшествующих выборок.
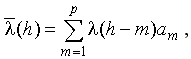 , ,
где 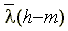 – значения речевого сигнала в моменты предшествующих выборок; m
=1,2…p
; p
– порядок предсказания; am
– коэффициенты предсказания. – значения речевого сигнала в моменты предшествующих выборок; m
=1,2…p
; p
– порядок предсказания; am
– коэффициенты предсказания.
Интервалы времени между моментами выборок определяются частотой дискретизации
th
– th
-1
= 1/f
д
.
В момент h
, когда известны не только предсказанное значения 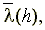 , но и истинное значение речевого сигнала (h
), можно определить ошибку предсказания , но и истинное значение речевого сигнала (h
), можно определить ошибку предсказания 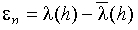 и затем подобрать коэффициенты предсказания таким образом, чтобы ошибка предсказания была минимальной. и затем подобрать коэффициенты предсказания таким образом, чтобы ошибка предсказания была минимальной.
Коэффициенты предсказания, значения которых передаются по каналу связи на приемную сторону, используются в качестве переменных параметров в рекурсивном цифровом фильтре, на вход которого подаются сигналы возбуждения. При воспроизведении вокализованных звуков (гласных) – это последовательность импульсов с частотой основного тона, а при воспроизведении невокализованных звуков (согласных) – это случайная последовательность импульсов, формируемых генератором шума.
При кодировании с линейным предсказанием моделируются различные параметры человеческой речи, которые передаются вместо отсчетов речевого сигнала или их разностей. Это позволяет существенно снизить скорость передачи речевого сигнала по сравнению с методами ИКМ, ДИКМ, АДИКМ.

Рис.6.
Структура синтезатора речи с линейным предсказанием.
Широко применяемый в настоящее время метод кодирования с линейным предсказанием предусматривает формирование блоков отсчетов (кадров), для каждого из которых вычисляется и передается частота основного тона, его амплитуда и информация о типе возбуждающего воздействия (гармоническое, негармоническое). Структура синтезатора речи с линейным предсказанием показана на рис. 6.
Здесь сигналы возбуждения имеют вид последовательности импульсов на частоте основного тона (для вокализованных звуков) или случайного шума (для невокализованных звуков).
Комбинации спектральных составляющих речи, возникающей, в частности, за счет работы голосовых связок, языка и губ человека, могут быть промоделированы цифровым фильтром с изменяющимися параметрами.
При линейном предсказании обычно производится спектральный анализ речи и выполняется построение систем анализа-синтеза. Во всех случаях параметры синтезатора обновляются при смене анализируемых кадров речевого сигнала.
Чтобы избежать эффектов, связанных со скачками значений параметров, необходимо плавно изменять параметры с помощью интерполяции при переходе от одного фрагмента (сегмента) речи к другому.
При кодировании речевых сигналов по методу LPC обычно применяют метод анализа через синтез (Analysis – by – Synthesis (AbS)).

Рис.7.
Иллюстрация метода анализа через синтез (
AbS
), где:
а) кодер
б) декодер (
l
’(
h
) значение
Pic
для момента
h
, полученное после декодирования)
При этом синтезатор (основной элемент декодера речевого сигнала) используется как составная часть устройства кодирования (рис.7). На основе формируемых данных производится синтез речевого сигнала, который сравнивается в процессе передачи с реальным сигналом, поступающим на вход устройства.
Сигнал ошибки e (h
), получаемый в результате вычитания истинного и синтезированного сигналов, используется для уточнения формируемых в кодере данных.
По существу системы, использующие метод LPC, отличаются лишь способами генерирования возбуждающего воздействия и выбора параметров моделирующего фильтра.
Глава 2: Способы преобразования информации в вокодерах с линейным предсказанием.
2.1.
Преобразование коэффициентов.
Основным набором передаваемых параметров в вокодере с линейным предсказанием являются М
коэффициентов фильтра с характеристикой A
(
z
)
для каждого анализируемого сегмента. Эти коэффициенты действительно были использованы учеными Итакура и Саито в вокодерной системе, построенной на основе метода максимального правдоподобия, где каждый параметр кодировался с помощью 9 бит. Исследователи Атал и Ханауэр обсуждали использование коэффициентов фильтра для передачи и отметили, что требуется не только относительно высокая точность (8—10 бит на коэффициент), но, кроме того, при линейной интерполяции параметров в приемнике не гарантируется устойчивость синтезатора. Вычисляя корни A
(
z
)
и передавая их, можно восстановить информацию о спектре сигнала, заключенную в A
(
z
),
используя в среднем 5 бит на параметр. Кроме того, поскольку корни соответствуют устойчивым синтезирующим фильтрам, при их линейной интерполяции гарантируется устойчивость.
Было исследовано и много других преобразований коэффициентов фильтра. Наиболее важным преобразованием является расчет коэффициентов частной корреляции или коэффициентов отражения {
km
}.
Они вычисляются непосредственно в автокорреляционном методе и могут быть получены рекурсивно с помощью процедуры пошагового понижения порядка, если используется ковариационный метод. Необходимым и достаточным условием устойчивости при этом является ограничение этих параметров единицей по модулю. Более того линейная интерполяция параметров устойчивых фильтров приводит в результате к устойчивым фильтрам.
Параметры {
km
}
связаны с площадями сечений неоднородной акустической трубы {
A
т
}.
.
В качестве параметров, удобных для передачи, используются как логарифм отношения функций площадей {
ln
(
A
т
/
A
т
-1},
так и сами функции площадей А{
m
}.
Линейная интерполяция этих параметров приводит к устойчивым фильтрам.
Одним из преобразований, гарантирующих устойчивость синтезирующего фильтра после интерполяции, основано на коэффициентах автокорреляции. При корреляционном методе анализ может быть разделен на вычисление коэффициентов автокорреляции в передатчике и решение автокорреляционных уравнений в приемнике. В ковариационном методе могут быть использованы процедуры пошагового понижения и повышения порядка, , включая применение уравнения в процедуре пошагового повышения порядка получения коэффициентов автокорреляции {
r
(т)}.
В приемнике решаются автокорреляционные уравнения, как если бы процедура была идентична автокорреляционному методу. Устойчивость синтезирующего фильтра, полученного с помощью интерполяции автокорреляционных коэффициентов, следует из того факта, что линейная интерполяция элементов двух положительно определенных теплицевых матриц дает положительно определенную теплицеву матрицу. Такая гарантия устойчивости предлагает безошибочность вычислений, поскольку ошибки при вычислениях могут исказить свойство положительной определенности матриц.
К параметрам, гарантирующим устойчивость при их интерполяции между устойчивыми сегментами, относятся корни функции А(
z
),
параметры {
km
},
функции площади, отношения площадей, логарифм отношения площадей и автокорреляционные коэффициенты. Параметрами, для которых неустойчивость, обусловленная ошибками вычислений, может быть легко обнаружена, являются корни полинома (для обеспечения устойчивости их модули должны быть меньше единицы), параметры {
km
}
(для устойчивости их модули также должны быть меньше единицы), функции площади и отношения площадей (для устойчивости их значения должны быть положительными). Ошибки вычисления логарифма отношения площадей не могут привести к неустойчивости, поскольку экспоненциальность всегда обеспечивает положительные отношения площадей.
2.2. Кодирование и декодирование.
Для вокодеров, возбуждаемых квазипериодическим сигналом, передаваемые параметры представляют собой обычно преобразования сигнала основного тона Р,
коэффициента усиления а и коэффициентов фильтра {аi
}
. На практике кодирование сигнала основного тона и коэффициента усиления обычно осуществляется по логарифмическому закону. Типичным является логарифмическое кодирование сигнала основного тона на 5 или 6 бит и логарифмическое кодирование коэффициента усиления на 5 бит. Основное внимание далее будет уделено коэффициентам отражения {
ki
,}
, представляющим собой преобразование от {
ai
},
и различным нелинейным преобразованиям, поскольку их свойства недостаточно известны.
В вокодерах с линейным предсказанием широко используются коэффициенты отражения (и такие параметры, как логарифм площадей). В автокорреляционном методе они легко получаются как часть результатов анализа, а в ковариационном методе — вычисляются с помощью процедуры пошагового понижения порядка. Необходимым и достаточным условием устойчивости синтезирующего фильтра при этом является то, что значения модулей коэффициентов отражения должны быть меньше единицы. Поэтому линейная интерполяция коэффициентов отражения устойчивых фильтров гарантирует устойчивость полученных в результате интерполяции фильтров.
Коэффициенты отражения имеют неразномерную спектральную чувствительность, причем наибольшая чувствительность будет, когда модуль коэффициента близок к единице. Это свойство было теоретически доказано Грэем и Маркелом. Они показали, что в процедуре пошагового повышения порядка на т-м
шаге изменение логарифмического спектра фильтра 1/
Am
(
z
),
вызванное изменением km
на Δkm
,
будет осциллировать (при изменении частоты от нуля до fJ
2)
между значениями
ln[1+Δkm
/(1+km
)] и ln[1-Δkm
/(1-km
)]
Таким образом, значения km
,
модули которых приближаются к единице, наиболее чувствительны к малым изменениям спектра. Неравномерная спектральная чувствительность была также подробно изучена Висваназаном и Макхоллом.
Известно, что для многих вокализованных звуков первые коэффициенты отражения имеют асимметричное распределение (k1
почти равен — 1, а k2
близок к +1), а коэффициенты более высокого порядка имеют центрированное около нуля распределение, близкое к гауссовскому. Это было замечено эмпирически рядом исследователей. Аналитически (используя аппроксимацию) было показано, что такая асимметрия имеет место для k1
и k2
в случае отсутствия предыскажения для устранения корреляции. Было также замечено, что при низких частотах дискретизации (10 кГц и меньше) величины коэффициентов отражения k
з,
k4
… с высокой вероятностью меньше 0,7.
Линейное квантование коэффициентов отражения на отрезке [—1, 1] нецелесообразно, так как значения, близкие к единице, обычно характерны только для k1
и k
2
.
Поэтому следует применять нелинейное квантование в силу неоднородной спектральной чувствительности. Использовалось несколько схем преобразования и кодирования. Хаски и другие изучили многие типы преобразований и пришли к выводу, что наиболее эффективно логарифмическое кодирование отношений площадей, т. е.:
ln[1-km
/(1+k)].
К такому же заключению пришли Висваназан и Макхолл на основании экспериментальной оценки спектральной чувствительности коэффициентов отражения. Велч использовал модифицированный логарифм отношения площадей ln[F-km
/(F+km
)]со значениями F
более единицы из-за того, что для коэффициентов отражения, близких к единице, квантование логарифма отношений площадей может стать настолько точным, что превысит точность исходных данных.
Для облегчения процедуры синтеза при использовании нормализованной структуры фильтра Маркел и Грэй предложили кодирование коэффициентов отражения по закону арксинуса θ
m
=
sin
-1
(
km
).
При этом достигается большая точность квантования коэффициентов отражения, близких к единице, и такое кодирование является единственным преобразованием, осуществляющим равномерное распределение углов для непосредственного поиска параметров фильтра в приемнике по тригонометрической таблице (такие таблицы в виде стандартных программ имеются в памяти ПЗУ высокоскоростных процессорных систем). Несмотря на то, что такое кодирование не соответствует усредненным кривым чувствительности Висваназана и Макхолла так же, как и кодированию логарифма отношения площадей, тем не менее оно приемлемо и более эффективно, чем линейное квантование коэффициентов отражения. Кодирование по закону арксинуса встречает такую же трудность, связанную с чрезмерной точностью квантования при значениях модулей, близких к единице, как и кодирование логарифма площади.
Некоторые подходы, применяемые для сокращения числа передаваемых двоичных единиц, относительно просты, в то время как другие являются более сложными. Маркел и Грэй устранили смещение k
1
и k
2
(путем добавления и вычитания 0,3 соответственно), а затем равномерно квантовали несмещенные результаты для всех коэффициентов отражения от —0,7 до + 0,7, используя меньшее число бит для коэффициентов отражения высокого порядка. Итакура и Саито применили динамическое программирование для распределения двоичных единиц, предназначенных для кодирования коэффициентов отражения. Было обнаружено, что предыскажение речевого сигнала значительно сокращает разницу между распределением двоичных единиц при динамическом программировании и равномерном распределении. Макхолл и другие использовали метод кодирования Хаффмана применительно к логарифму отношения функции площади для повышения эффективности представления. Эта процедура имеет то преимущество, что используется меньшее число двоичных единиц без какого-либо ухудшения точности представления. Мак-Кендлес использовал метод равномерного кодирования площадей, основанный на гистограммах, полученных статистическим путем. При этом методе требуется отличное от других (но эффективное) кодирование каждого отдельного коэффициента отражения. Специфический вид такого кодирования зависит от статистических средних значений, полученных путем обработки большого числа сегментов данных, и зависит от таких параметров системы, как частота дискретизации, характеристики предыскажающего фильтра и типа записывающей аппаратуры.
Маловероятно, что можно определить единственную оптимальную схему кодирования-декодирования в том смысле, что получится наилучшее субъективное качество восприятия синтезированной речи при самой низкой скорости передачи. Когда критерий качества основывается на восприятии, выбор схемы кодирования-декодирования зависит от разных факторов и всегда имеется различие в мнениях слушателей.
При моделировании неквантованные параметры (при использовании системы счисления с плавающей запятой или целых чисел с максимальной точностью) обычно преобразуются в группу целых чисел {0, 1, ..., 2β
—1}, где β — число бит, используемых для представления параметра. Такое представление соответствует преобразованию множества значений в одно и может быть эффективно выполнено с помощью таблицы, например, на основе двоичного поиска. Эти передаваемые параметры однозначно соответствуют декодируемым параметрам и могут быть, следовательно, использованы в приемнике для табличного декодирования с помощью таблицы.
Специальные примеры передачи речи с минимальной скоростью на основе различных преобразований параметров будут представлены ниже при рассмотрении вокодерных систем и моделирования.
2.3. Передача параметров с переменной скоростью.
Большая часть разговорной речи содержит паузы. Кроме того информация, необходимая для точного представления исходного речевого сигнала, существенно изменяется во времени. Например, при анализе переходов между вокализованными и невокализованными звуками их необходимо разбить на сегменты анализа малой длительности (например, fr
=100 Гц), иначе такое слово, как pea
, при синтезе может звучать как fee
. Однако для протяжных звуков, таких, как в сочетании ahh
, квазистационарный речевой сигнал может быть удовлетворительно представлен при более низкой частоте анализа. Если учесть паузы и переменный во времени характер создания информации в системах с коммутацией сообщений, то скорость передачи параметров речевого сигнала в этом случае можно существенно снизить без потери качества по сравнению со скоростью передачи в системах с коммутацией каналов (например, в телефонной сети).
Для того чтобы использовать изменяющиеся во времени свойства речевого сигнала для снижения скорости передачи, необходимо располагать некоторой мерой этого изменения. С ее помощью можно было бы сравнивать спектры или параметры на каждом новом сегменте анализа с аналогичными характеристиками в уже обработанных сегментах. Если эта мера превышает заданный порог, то отсюда следует, что характеристики сигнала претерпевают достаточно большое изменение, которое требует передачи нового набора параметров. Поскольку наибольший процент передаваемых двоичных единиц приходится на параметры, несущие информацию о спектре (например, коэффициенты отражения или логарифм отношения площадей), то основное внимание должно быть обращено на них.
Можно предложить большое число возможных мер, каждая из которых основана на некоторых характеристиках, описывающих анализируемый сегмент. Такие меры, например, могут основываться на средних значениях, суммах абсолютных разностей или квадратов параметров. Параметрами могут являться коэффициенты отражения, коэффициенты автокорреляции (возможно нормированные для устранения влияния фактора усиления), коэффициенты обратного фильтра или кепстральные коэффициенты.
2.4. Возбуждение синтезатора и выбор коэффициента усиления.
Атал и Ханауэр предложили способ согласования энергии синтезированной речи в пределах периода основного тона с соответствующей энергией речевого сигнала с помощью передачи энергии входного сигнала, измеренной за один период ОТ. Хотя они ограничились рассмотрением ковариационного метода без предыскажающей фильтрации, однако этот способ применим как в ковариационном, так и в автокорреляционном методах и легко может быть модифицирован для случая применения предыскажения и прямой формы синтезирующего фильтра.
Способ основан на том, что каждый отсчет синтезированной речи имеет две основные составляющие: 1). затухающие комплексные экспоненты {
q
(
n
)}
предшествующего синтезированного периода ОТ и 2). выходной сигнал синтезатора {и(п)},
являющийся откликом на возбуждающую последовательность {е(п)},
без учета влияния предшествующего сегмента.
В нашем случае источником возбуждения является либо последовательность периодических единичных отсчетов (следующий за нулевыми отсчетами) при синтезе вокализованных звуков, либо последовательность выходных отсчетов генератора псевдослучайных чисел при синтезе невокализованных звуков (период ОТ для невокализованных звуков считается постоянным). Если ввести коэффициент усиления g
,
то полный отклик синтезатора {
s
(
n
)}
для нового сегмента определяется выражением
s
(
n
) =
q
(
n
) +
gu
(
n
).
Если использовать черту для обозначения суммы N
отсчетов, например,
__ N
-1
u(n) = Σu(n)
n
=0
то требование равенства энергий исходного и синтезируемого сигналов запишется в следующем виде:
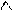 ____ _____ ______________ ___________ ______________ _____ ____ _____ ______________ ___________ ______________ _____
s2
(n)= s2
(n) = [q(n)+gu(n)]2
= g2
u2
(n) + 2gq(n)u(n) + q2
(n)
Это уравнение второго порядка может быть решено относительно g
.
Приведем алгоритм вычисления отклика синтезирующего фильтра прямой формы.
1.Вычислить выходной сигнал фильтра q
(
n
)
при n=0, 1, ..., М
—1 в отсутствие возбуждения (используя только данные из памяти о предшествующем периоде) и без обновления коэффициентов фильтра.
2. Вычислить выходной сигнал фильтра и(п)
при n=0, 1, 1, ..., N
—1 по сигналу возбуждения {е(п)},
а память фильтра обнулить.
3. Вычислить коэффициенты уравнения второго порядка относительно g
и решить его:
___________ ______________ _____ _____
g2
u2
(n) + 2gq(n)u(n) + q2
(n) – s2
(n) = 0
4. Предполагая, что g
действительно и неотрицательно, определить выходной сигнал синтезатора в соответствии с выражением
s(n) = q(n) + gu(n)
при n = 0, 1, .... N—1.
5. Записать в память фильтра прямой формы значения
s
(
N
—
1), s(N—2),..., s
(
N
—
M
).
Вернемся к третьему шагу. Если s
2
(
n
)>
q
2
(
n
),
то корни квадратного уравнения будут иметь противоположные знаки и, следовательно, всегда будет положительный действительный корень. Это условие выполняется, когда истинная энергия больше, чем энергия затухающего переходного процесса. Если это условие не удовлетворяется, что может случиться с сигналом, амплитуда которого уменьшается, то необходимо, чтобы
___________ _____
q(n)u(n) / u2
(n) было отрицательным и, кроме того,

При отсутствии действительных положительных корней модель не имеет физического смысла. Если решения не существует, то Атал и Ханауэр предложили устанавливать g
=0.
Такая процедура требует моделирования работы синтезирующего фильтра дважды, в дополнение к трем суммам по N
отсчетов и решению квадратного уравнения. Передаваемый коэффициент усиления а
определяется по формуле a
2
=
s
2
(
n
).
Алгоритм, описанный выше, затем полностью реализуется в приемнике.
Такой подход можно распространить и на другие структуры синтезирующих фильтров. При этом необходимо осуществлять дополнительные вычисления при преобразовании значений задержанной синтезированной речи в сигналы, содержащиеся в элементах памяти фильтров. Изменение алгоритма при использовании предыскажения заключается в замене коэффициентов A
(
z
)
коэффициентами A
(
z
)
—(1—μ
z
-1
)
, где (1— μ
z
-1
)
определяет характеристику предыскажающего фильтра.
Несколько более простой (и менее точный) метод заключается в возбуждении синтезирующего фильтра входной последовательностью {е(п)},
чтобы вычислить и(п),
где и(п)
теперь содержит отклик как от предшествующего сегмента, так и от текущего сигнала возбуждения
Поскольку в указанных методах непосредственно согласуется энергия сигналов на входе и выходе, то можно ожидать точного согласования огибающих исходной и синтезированной речи. Однако необходимо тщательно следить за тем, чтобы величина разрывов непрерывности была минимальна, поскольку на коэффициенты усиления в конце одного периода ОТ и начале следующего не накладывается никаких энергетических ограничений, кроме косвенных.
Глава 3: Виды липредеров на примере устройств с низкой скоростью передачи информации.
.
Одним из возможных и наиболее важных применений линейного предсказания является низкоскоростная (2400—3600 бит/с) надежная передача речи по телефонным каналам. Так как одноканальная высококачественная передача речи требует скорости от 40 000 до 200 000 бит/с, очевидно, что некоторые характеристики речи должны быть учтены в модели, в то время как другие могут быть исключены с целью уменьшения скорости передачи информации более чем на порядок. Важно понимать все обстоятельства, связанные с этим соображением, чтобы отчетливо представлять возможности и ограничения вокодерных систем с линейными предсказаниями. Некоторые из этих моментов далее будут рассмотрены.
На каждом сегменте необходимо максимально точно оценивать сигнал ОТ (отсутствие вокализованности означает, что Р=0). Эта оценка представляет собой единственный параметр, который обеспечивает наибольшее снижение скорости передачи информации. Если она достаточно точна, то натуральность звучания синтезированной речи снижается незначительно. Однако точное оценивание предполагает, что посторонние шумы должны быть сведены к минимуму. Музыка, лай собак или внятные помехи от разговоров других абонентов приведут к значительному ухудшению точности оценивания сигнала ОТ. Кроме того, диапазон изменения частоты основного тона оказывается ограниченным. Его величина зависит от сложности алгоритма выделения ОТ.
Обычно в процессе выделения ОТ каждый сегмент классифицируется как полностью вокализованный (тон V=1) или как полностью невокализованный шум (V=0). Очевидно, существуют звуки, которые следовало бы рассматривать как промежуточные, например /v/ в слове thieves. Применение бинарного правила классификации обусловлено практическими соображениями. Трудно автоматически установить правильное соотношение между периодической и шумовой компонентами, да и качество синтеза при этом часто ухудшается ненамного.
Если не применяется схема с переменной скоростью передачи информации, при которой учитываются паузы и другие свойства речи, то скорость не может быть уменьшена ниже 1200 — 1400 бит/с. Системы с постоянной скоростью передачи (с синхронной передачей), описываемые в этом параграфе, могут сохранять высокое качество синтеза (при отсутствии операций кодирования, квантования или вычислений с конечной длиной слова) приблизительно до 3300 бит/с, обеспечивая, по существу, незначительное ухудшение качества восприятия. Приблизительно от 1400 до 3300 бит/с ухудшение качества может изменяться от незначительного до существенного, в зависимости от отдельных звуков речи и характерных особенностей говорящего. Ниже 1400 бит/с качество речи значительно ухудшается.
В этой части представлены примеры фраз, переданных по вокодерным системам. Существуют различные виды ЛПС вокодеров – вокодеры на основе метода максимального правдоподобия и частных корреляции, вокодеры на основе автокорелляционного метода и вокодеры на основе ковариационного метода. Для понимания ниже разберем более подробно последние.
3.1. Липредеры на основе ковариационного метода.
Одними из видов липредеров с низкой скоростью передачи являются липредеры на основе ковариационного метода. Атал и Ханауэр вработах и впервые представили результаты анализа-синтеза на основе ковариационного метода линейного предсказания. К статье была приложена звукозапись, чтобы продемонстрировать качество синтеза, полученное при различных информационных скоростях. Исходная речь была записана при большом отношении сигнал/шум, пропущена через НЧ фильтр с частотой среза 5 кГц, а затем дискретизирована с частотой f= 10 кГц. Сегмент анализа устанавливался равным одному периоду Р
основного тона для вокализованных участков и ' 10 мс для невокализованных. Коэффициенты предсказания {а*} рассчитывались на основековариационного метода, причем N
=
Pfs
-
Коэффициент усиления а вычислялся с помощью первой из процедур, описанных выше, так что энергия речи на каждом синтезируемом сегменте согласовывалась с энергией сигнала на соответствующем анализируемом сегменте. Выделение ОТ выполнялось на основе автокорреляционного анализа сигнала, полученного путем фильтрации исходной речи и возведения в куб для подчеркивания участков речевого колебания с большой амплитудой .
Для проверки на устойчивость фильтра с характеристикой 1/
A
(
z
)
на анализируемом сегменте применялась процедура пошагового понижения порядка. Если фильтр неустойчив, то корни функции получались по программе нахождения корней полинома. Пусть функции
М
A(z) = П (1- zm
*
z-1
)
m
=1
опиcывают полиномиальную характеристику фильтра. Если корни zm
лежат вне единичной окружности, т. е. |
zm
|>1
, то заменим zm
на z
*
m
/|
zm
|2
.
Такая замена гарантирует, что форма спектра останется неизменной, хотя исходный критерий минимизации уже не удовлетворяется.
Полином, все корни которого лежат внутри единичной окружности, может быть тогда составлен рекурсивно
A’m
(z) = A’m
-1
(z)*(1-zm
z-1
)
при m=1, 2, ..., М,
причем AM
'(
z
)
заменяет полином A
(
z
).
Отметим, что корень обычно оказывается комплексным. Полученные в результате такого преобразования коэффициентов фильтра параметры кодировались и квантовались двумя различными способами: (1) частота и ширина полос корней zm
на сегменте в целом кодировались 60 двоичными единицами (в предположении, что М=\2)\ 2)
площади акустической трубы Am
кодировались 60 двоичными единицами. Оба этих способа гарантируют устойчивость фильтра синтезатора, даже если применяется линейная интерполяция. Другими передаваемыми параметрами были период Р
основного тона, признак вокализованности «тон-шум» (
V
/
UV
)
и коэффициент усиления, которые кодировались соответственно шестью, одной и пятью двоичными единицами. Поэтому скорость передачи составляла Br
=
fr
*
(6+1+5+60) =72*fr
,.. Так как использовались частоты сегментов, равные 100, 67 и 33 Гц, то результирующие скорости составляли 7200, 4800 и 2400 бит/с соответственно.
Для синтеза речи применялся фильтр прямой формы, управляемый синхронно с периодом ОТ. Функция возбуждения представляла собой выходной сигнал генератора в виде единичных отсчетов в начале каждого периода, умноженных на коэффициент усиления о,
или равномерно распределенных псевдослучайных отсчетов с нулевым средним значением и единичной дисперсией. По признаку вокализованности V
(«тон-шум») определялось, какой вид функции возбуждения применять. Поскольку параметры передаются с постоянной частотой fr
,
то для осуществления синтеза синхронно с периодом ОТ использовалась линейная интерполяция.
Для того чтобы гарантировать устойчивость, последовательность {
ai
}
пересчитывалась в первые М+1
отсчеты автокорреляционной последовательности {
r
(п)}.
После интерполяции последовательность {
r
(п)}
пересчитывалась обратно в интерполированный ряд параметров {ai
}, а затем последний применялся для синтеза в фильтре прямой формы.
Субъективно оцениваемое качество синтезированной речи было очень близко к качеству исходной речи. Некоторые факторы, касающиеся качества синтезированной речи, полученной в этой системе, будут рассмотрены далее. При построении этой системы преследовалась цель получения наивысшего возможного качества при заданной информационной скорости без учета сложности вычислений. Для проведения анализа с длительностью временного окна, зависящей от периода ОТ, требуется очень точно определять этот период. Как отмечал Шредер, частота возникновения ошибок, равная 1%, при выделении ОТ может быть недопустимой. Используемый алгоритм анализа периода ОТ требует много логических операций и обработки четырех или пяти задержанных в буферной памяти сегментов для определения того, классифицировать сегмент как вокализованный или как невокализованный и т. д. Чтобы достигнуть такого же качества синтеза, как в исходной записи, необходимо обеспечить большое отношение сигнал/шум (45—50 дБ). Более того, результаты отчасти зависят от того, насколько хорошо речь описывается комплексно-экспоненциальной моделью в пределах одного периода ОТ. Следует отметить, что все операции выполнялись в режиме с плавающей запятой с полной точностью.
При реализации такой системы можно не получить ожидаемых хороших результатов, если рассчитывать на то, что проведение вычислительных операций с малыми ошибками устранит потери качества восприятия. В настоящее время не существует прямых процедур (в тем смысле, что алгоритм может быть представлен последовательностью алгебраических соотношений) для реализации систем с высоким качеством и низкими скоростями. Например, автокорреляционный анализ является прямым в том смысле, что если при вычислении обеспечивается достаточная точность, то устойчивость фильтра с характеристикой 1/
A
(
z
)
теоретически гарантируется. Но, к сожалению, качество синтеза при этом часто ниже, чем при ковариационном методе при идеальных условиях (например, анализ синхронный с ОТ, большое отношение сигнал/шум). С другой стороны, ковариационный метод требует проведения дополнительных операций для обеспечения устойчивости синтезирующих фильтров (проверка корней полиномов и смещение корней внутрь единичной окружности, после которого критерий минимума ошибки предсказаний уже не удовлетворяется).
Вокодерная система на основе линейного предсказания, использующая такой принцип анализа-синтеза, была исследована Хаски и другими. При этом была поставлена задача оптимизировать систему с точки зрения качества ее работы и точности реализации для самых разных дикторов при скоростях передачи информации 3600 и 7200 бит/с. В этом исследовании речь была ограничена полосой до 4000 Гц и дискретизировалась с частотой fs
= 8000 Гц. Кроме того, длительность сегмента анализа была фиксирована. С целью определения требуемого числа коэффициентов фильтра М
и длины сегмента анализа N
было обработано шесть различных предложений от разных дикторов.
Из набора возможных значений длины сегмента N=64, 128 и 256 отсчетов был выбран сегмент с N= 128 (16 мс). Выбор более короткого интервала приводил к неустойчивости синтезирующего фильтра, в то время как при сегменте большей длительности появлялось чрезмерное сглаживание спектра. Порядок предсказателя М
был выбран равным 12 при частоте дискретизации fs
=8 кГц для обеспечения хорошего качества синтеза в различных условиях. При этом не наблюдалось существенного улучшения в синтезе при частоте сегментов выше 200 Гц и качество речи плавно снижалось при уменьшении частоты анализа от 200 до 30 Гц.
С точки зрения объема вычислений было целесообразно не определять корни полиномов. Вначале характеристика фильтра A
(
z
)
пересчитывалась в характеристику соответствующей акустической трубы. Необходимым и достаточным условием устойчивости фильтра l
/
A
(
z
)
является положительность Затем вычисляется новая функция площадей. Эта процедура продолжается до тех пор, пока модифицированный полином не будет иметь все функции площадей положительными. Кроме того, была установлена необходимость того, чтобы ширина каждой полосы была больше 30 Гц. Это требование удовлетворяется, если сжатие единичной окружности в 1,01 раза не приводит к неустойчивым функциям площадей.
Значительные усилия были приложены для определения эффективного метода кодирования функций площадей. Было установлено, что наиболее эффективным законом кодирования является логарифмическое кодирование отношений площадей. Было найдено, что наилучшим выбором распределения бит при скорости передачи данных 3600 бит/с и частоте анализа fr
=50 Гц является следующее:
отношение площадей 1—2 6 бит;
—»—3—8 5 бит;
—»— 9—12 4 бит;
ОТ и «тон-шум» 8 бит;
коэффициент усиления 5 бит.
Для получения системы со скоростью передачи 7200 бит/с было решено просто удвоить частоту анализа, чтобы получить наилучшие результаты.
Качество восприятия сигнала в системе со скоростью передачи 3600 бит/с оценивалось при помощи сбора мнений слушателей. Было обработано 30 предложений (десять дикторов произносили по три предложения каждый). Слушатели (30) оценивали эти предложения (каждый 2 раза) по тексту, содержащему 60 пунктов, при использовании следующих категорий: отлично, хорошо, удовлетворительно, плохо, очень плохо. Слушатели были «настроены» на экспериментальные категории с помощью прослушивания речи стандартного телефонного канала и речи, полученной в полосном вокодере со скоростью 3600 бит/с. Результаты показывают, что качество, полученное при моделировании системы со скоростью передачи 3600 бит/с, находится между удовлетворительным и хорошим. Имеются основания полагать, что эти оценки чувствительны к дикторам и, в меньшей степени, к тексту. Обычно мужские голоса получают более высокие оценки, чем женские, но существуют и исключения из этого правила. Для большинства дикторов и текстов система со скоростью 3600 бит/с обеспечивает улучшение качества по сравнению с предшествующими полосными вокодерами.
Была проведена также сравнительная проверка для того, чтобы оценить разницу в качестве между системами со скоростями 3600 и 7200 бит/с. Тридцать предложений, использовавшихся при проверке по установлению категорий, были обработаны в модели вокодера со скоростью 7200 бит/с, в которой длительность сегмента была равна 10 мс, причем на сегмент отводилось по 72 двоичных единицы. Предложения для обеих систем (с 3600 и 7200 бит/с) были объединены в тест, включающий 30 разделов.
Результаты для всех дикторов и предложений показали, что в 53% случаев предпочтение было отдано системе с более высокой скоростью передачи данных. Когда же рассматривались только дикторы женщины, в результате получили цифру 58%. Этот результат объясняется ухудшением интерполяции коротких периодов ОТ в сигнале, соответствующем женскому голосу при сегменте анализа длительностью 20 мс. Такое небольшое предпочтение показывает, что нет существенного роста в субъективном качестве при увеличении скорости передачи свыше 3600 бит/с.
Исследование соображений по реализации вокодеров привели кследующей оценке числа операций на сегмент: 4200 операций для передатчика и 5000 операций для приемника (всего 9200 операций на сегмент или, при скорости передачи 3600 бит/с, 461 000 операций в секунду). Предполагалось, что для выполнения всех этих операций необходим процессор, работающий в режиме с плавающей запятой.
Уэлч и другие, основываясь на системе Атала — Ханауэра и исследовании Хаски и других, ввели некоторые модификации, которые позволили реализовать систему при использовании быстродействующего цифрового процессора.
Глава 4: Методы анализа речи на основе использования вокодеров с линейным предсказанием.
Прямое использование предсказания позволяет воспроизводить звук, но с плохим качеством. Поэтому этот метод имеет много различных разновидностей, улучшающих это качество. Эти методы касаются улучшения параметров возбуждения генераторов на приемном конце. Поэтому из трех составляющих системы с предсказанием — аппроксимации, предсказания и методов восстановления (возбуждения генераторов) речи — все усовершенствования метода линейного предсказания касаются последней составляющей. Поэтому они иногда называются гибридными кодерами, ибо представляют собой гибриды вокодеров и кодеров сигнала. Рассмотрим коротко каждый из них.
Все методы анализа речи предполагают достаточно медленное изменение свойств речевого сигнала во времени. Характеристики голосового тракта можно считать неизменными на интервале 10-20 мс, то есть параметры надо измерять с частотой порядка 1/20 мс = 50 Гц.
Известно несколько разновидностей
метода линейного предсказания, а именно:
- с возбуждением от импульсов основного тона- LPC (LinearPredictiveCoding);
- многоимпульснымвозбуждениемMPELP (Multi Pulse Excited Linear Predictive) илиMPLPC (Multi Pulse Excited LPC);
- возбуждениемотостаткапредвидения RELP (Residual Excited Linear Predictive);
- возбуждениемоткодаСELP (Code Excited Linear Predictive).
В кодере LPC сигнал возбуждения передается при помощи трех параметров: периода основного тона (Тот) для звуков, которые вокализованы; сигнала тон-шум (характеризующего наличие в данный момент его параметров или тона, или шума) и амплитуды сигнала.
Кодер с возбуждением от частоты основного тона (ЧОТ) - это кодер LPC, который используется для передачи параметров речевого сигнала со скоростью 2400 бит/с и ниже.
Кодер с возбуждением от ЧОТ не обеспечивает необходимого качества синтезированной речи даже при высокой скорости передачи. Не для всех звуков удается получить точное разделение речи на вокализованную и невокализованную.
Известно, что кроме ЧОТ основного возбуждения, которое имеет место при смыкании голосовой щели, имеется вторичное возбуждение, которое имеется не только при размыкании голосовой щели, но и при смыкании.
В многоимпульсном возбуждении сигнал остатка LPC представляется в виде последовательности импульсов с неравномерно распределенными интервалами и с различными амплитудами (приблизительно 8 импульсов за 10 мс).
Информация о положениях и амплитудах импульсов возбуждения вместе с LPC-параметрами в каждом кадре формируется кодером.
Если используется скорость до10 параметров LPC 1,8 кбит/с (36 бит кадров20 мс), то при скоростях передачи 16 и 9,6 кбит/с на передачу параметров сигнала возбуждения отводятся скорости соответственно 14,2 и 7,8 кбит/с. На скорости 16 кбит/с и даже ниже создается высококачественная синтезированная речь. При скоростях 16 и 9,6 кбит/с синтезированная речь отвечает по качеству ИКМ сигналам (с логарифмическим компандированием) со скоростями передачи 56 и 52 кбит/с.
На скорости 4,8 кбит/с на прием передаются параметры LPC и кроскореляционная функция. Автокореляционная функция воспроизводится с параметров LPC, которые принимаются, после чего определяются положения и амплитуды импульсов возбуждения. Качество синтезированной речи при многоимпульсном возбуждении при скорости передачи 4,8 кбит/с заметно выше, чем при одноимпульсном возбуждении при той самой скорости передачи.
Кодер с линейным предсказанием, в котором в качестве сигнала возбуждения может использоваться остаток предсказания, называется RELP кодером. Остаток предсказания пропускается через ФНЧ с частотой среза 800 Гц при передаче на скорости 9,6 кбит/с и 600 Гц на скорости 4,8 кбит/с. В первом случае сигнал остатка дискретизируется с частотой 7,2 кбит/с и с той же частотой передается. Остаток 9,6-7,2 = 2,4 кбит/с используются для передачи коэффициентов предсказания и усиления. Во втором случае, т.е. при скорости передачи 4,8 сигнал остатка дискретизируется на частоте 2,4 кбит/с и с этой же скоростью передается. Остаток 2,4 кбит/с используются так же, как и в первом случае.
В декодере сигнал возбуждения восстанавливается во всей полосе частот. При этом верхняя половина возобновленного спектра возбуждения становится зеркальным отображением нижней половины.
Сигнал остатка для RELP-кодера может формироваться и во время декодирования. Дело в том, что для передачи этого сигнала нужна достаточно высокая скорость, являющаяся неприемлемой для кодеров LPC, скорость передачи каких 2,4 кбит/с, поэтому необходимо создавать сигнал остатка на прием сигнала ЧОТ.
Сигнал остатка не обладает амплитудным спектром, а имеет те же самые резонансные области, что и реальный речевой сигнал. Именно поэтому сигнал остатка обладает высокой разборчивостью. Амплитуды формант на выходе синтезирующего фильтра LPC часто бывают меньше амплитуд формант в реальном речевом сигнале. Случается это в результате квантирования параметров LPC.
В линейном предсказателе с возбуждением от кода СELP (Code Excited Linear Predictive) сигнал возбуждения представляется в виде вектора, которому присваивается определенный индекс, т.е. код.
Выбор оптимального вектора осуществляется с большого множества векторов-кандидатов, которые составляют кодовую книгу. Определение размера кодовой книги возбуждения имеет определяющее значение для создания необходимого качества восстановления синтезированного языка.
Метод линейного предсказания с кодовым возбуждением обеспечивает высокое качество речевого сигнала при скоростях передачи 4…16 кбит/с.
Данный класс речевых кодеров занимает промежуточное место между кодерами формы сигнала и параметрическими вокодерами. Анализ параметров речи осуществляется на интервалах 10-30 мс, что позволяет эффективно применять CELP при скоростях передачи от 4 до 16 Кбит/c. Как видно из структурной схемы кодера CELP (рис. 8), вместо кодирования сигналов отсчет за отсчетом кодером разностного сигнала применяется "кодовая книга возбуждения". В этом случае каждому разностному сигналу сопоставляется строка (шаблон) сигналов. Эта строка содержит набор отсчетов, соответствующих передаваемой остаточной последовательности на основе полученного значения ошибки. На приемном конце вместо декодера разностного сигнала также применяется "кодовая книга возбуждения".
Существует большое число разновидностей кодовых книг, которые классифицируются:
1. по принципу поиска кодов векторов (с полным перебором, двоичный или последовательный поиск и т.п.);
2. по способам обучения (Фиксированная или адаптируемая книга);
3. по виду хранимой информации (выборки речи или реализация шума).
Алгоритм CELP позволяет воспроизводить речь с высоким качеством. Средняя экспертная оценка: 3,5—3,5. Однако он требует больших вычислительных ресурсов, поэтому на его основе построено много разновидностей кодеров. По отношению к многоимпульсному методу CELP-метод достигает более высоких показателей восстановления речи при одинаковых скоростях.

Рис. 8.
Структурная схема кодера CELP
В США приняты два федеральных стандарта на применение CELP:
- 1015 (LPC-10E, 2400 бит/с);
- 1016 (E-CELP, 4800 бит/с).
ITU (Международный союз электросвязи, МСЭ) разработал рекомендации:
- G.728 на алгоритм LD-CELP (16 кбит/с);
- G.729 на алгоритм CS-ACELP (8 кбит/с).
Характеристики некоторых основных алгоритмов кодирования речи приведены в табл.1.
Таблица 1.
Основные характеристики наиболее известных типов вокодеров
| Название алгоритма |
Рекомендация |
Скорость алгоритма (кбит/с) |
Размер речевого кадра
(октетов)
|
Задержка накопления (мс) |
| CS-ACELP |
ITU G.729 |
8 |
10 |
10 |
| PCM |
ITU G.711 |
64 |
40 |
5 |
| 56 |
35 |
5 |
| 48 |
30 |
5 |
| ADPCM |
ITU G.726 |
40 |
25 |
5 |
| 32 |
20 |
5 |
| 24 |
15 |
5 |
| 16 |
10 |
5 |
| LD-CELP |
ITU G.728 |
16 |
10 |
5 |
| MP-MLQ |
ITU G.723.1 |
6.3 |
24 |
30 |
| ACELP |
ITU G.723.1 |
5.3 |
20 |
30 |
Важной характеристикой любого вокодера является качество воспроизводимой речи. Для того, чтобы оценить это качество, было введено понятие средней субъективной оценки (MOS - mean opinion score) или психологической реакции человека на воспроизводимую речь.
Оценка по шкале MOS определяется путем обработки оценок, даваемых группами слушателей. В табл. 2 приведены оценки MOS для различных методов кодирования.
Таблица 2.
Показатели MOS основных алгоритмов кодирования речи
| Название алгоритма |
MOS |
| G.711 (PCM; 64 кбит/c) |
4,1 |
| G.726 (ADPCM; 32 кбит/c) |
3,8 |
| G.728 (LD-CELP; 16 кбит/c) |
3,6 |
| G.723.1 (ACELP; 5,3 кбит/c) |
3,7 |
| G.723.1 (MP-MLQ; 6,3 кбит/c) |
3,9 |
Наиболее предпочтительным среди приведенных методов кодирования с точки зрения соотношения качество речи
/ скорость потока
является алгоритм G.723.1.
Глава 5: Кодеки.
Рассмотрим теперь более широкое понятие – кодеки. Кодек (англ. codec, от coder/decoder — кодировщик/декодировщик или compressor/decompressor) — это устройство или программа, способная выполнять преобразование данных или сигнала. Специальные голосовые кодеки как раз и используют вокодерные принципы. Данная глава будет несколько дублировать прошлую, однако ее рассмотрение необходимо с целью понимания общей системы кодеков.
Эффективность использования пропускной способности IP-сети существенным образом зависит от выбора оптимального алгоритма кодирования/декодирования речевой информации – кодека.
Все существующие типы речевых кодеков по принципу действия можно разделить на три группы:
· Кодеки с импульсно-кодовой модуляцией (ИКМ) и адаптивной дифференциальной импульсно-кодовой модуляцией (АДИКМ)
, появившиеся в конце 50-х годов и использующиеся сегодня в системах традиционной телефонии. В большинстве случаев они представляют собой сочетание АЦП/ЦАП.
· Кодеки с вокодерным преобразованием речевого сигнала
возникли в системах мобильной связи для снижения требований к пропускной способности радио тракта. Эта группа кодеков использует гармонический синтез сигнала на основании информации о его вокальных составляющих - фонемах. В большинстве случаев, такие кодеки реализованы как аналоговые устройства.
· Комбинированные (гибридные) кодеки
сочетают в себе технологию вокодерного преобразования/синтеза речи (преобразование речевого сигнала в цифровой поток со скоростью от 1,2 до 4,8 Кбит/с), но оперируют уже с цифровым сигналом посредством специализированных цифровых сигнальных процессоров (Digital Signal Processor, DSP).
Кодеки этого типа содержат в себе ИКМ или АДИКМ кодек и реализованный цифровым способом вокодер.
На рис. 9 представлена усредненная субъективная оценка качества кодирования речи для вышеперечисленных типов кодеков.

Рис. 9.
Усредненная субъективная оценка качества кодирования речи для различных типов кодеков
В голосовых шлюзах IP-телефонии понятие кодека подразумевает не только алгоритмы кодирования/декодирования, но и их аппаратную реализацию. Большинство кодеков, используемых в IP-телефонии, описаны в рекомендациях семейства «G» стандарта Н.323 (рис. 10).

Рис. 10.
Стандарты для кодирования речевых сигналов
Рассмотрим некоторые основные кодеки, используемые в шлюзах IP-телефонии операторского уровня.
Кодек G.711
Рекомендация G.711, утвержденная МККТТ в 1984 г., описывает кодек, использующий ИКМ преобразование аналогового сигнала с точностью 8 бит, тактовой частотой 8 Кгц и простейшей компрессией амплитуды сигнала. Скорость потока данных на выходе преобразователя составляет 64 Кбит/с. Для снижения шума квантования и улучшения преобразования сигналов с небольшой амплитудой при кодировании используется нелинейное квантование по уровню (рисунок 11) согласно специальному псевдо-логарифмическому закону: А-закону для европейской системы ИКМ-30/32 или µ-закону для североамериканской системы ИКМ-24.
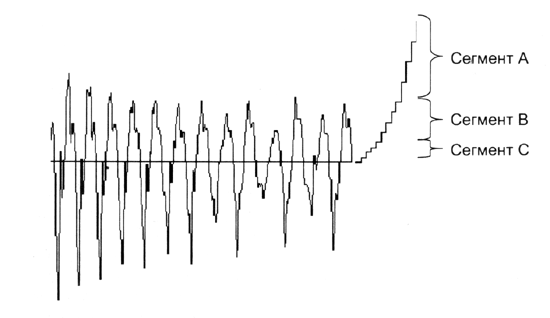
Рис. 11.
Нелинейное квантование по уровню
Первые ИКМ кодеки с нелинейным квантованием появились уже в 60-х годах. Кодек G.711 широко распространен в системах традиционной телефонии с коммутацией каналов. Несмотря на то, что рекомендация G.711 в стандарте Н.323 является основной и первичной, в шлюзах IP-телефонии данный кодек применяется редко из-за высоких требований к скорости передачи (64 Кбит/с) и задержкам в канале передачи. Использование G.711 в системах IP-телефонии обосновано лишь в тех случаях, когда требуется обеспечить максимальное качество кодирования речевой информации при небольшом числе одновременных разговоров.
Кодек G.726
Один из старейших алгоритмов сжатия речи - адаптивная дифференциальная ИКМ (АДИКМ) - был принят в 1984 г. (рекомендация G.726). Этот алгоритм дает практически такое же качество воспроизведения речи, как и ИКМ, однако для передачи информации при его использовании требуется полоса всего в 16-32 Кбит/с. Метод основан на том, что в аналоговом сигнале, содержащем речевую информацию, невозможны резкие скачки интенсивности. Поэтому, если кодировать не мгновенное значение амплитуды сигнала, а ее изменение по сравнению с предыдущим значением, то можно обойтись меньшим числом разрядов. В АДИКМ (ADPCM) изменение уровня сигнала кодируется четырехразрядным числом, при этом частота измерения амплитуды сигнала сохраняется неизменной (8 Кгц). Процесс преобразования не вносит существенной задержки и требует от DSP 5,5-6,4 миллионов операций в секунду (Million Instructions Per Second, MIPS). Кодек G.726 может применяться совместно с кодеком G.711 для снижения скорости кодирования последнего. Кодек G.726 предназначен для использования в системах видеоконференций.
Кодек G.723.1
Рекомендация G.723.1 описывает гибридные кодеки, использующие технологию кодирования речевой информации, сокращенно называемую "множественное импульсное, многоуровневое квантование" (Multy-Pulse - Multy Level Quantization, MP-MLQ). Данный тип кодеков можно охарактеризовать как комбинацию АЦП/ЦАП и вокодера. Своим возникновением гибридные кодеки обязаны системам мобильной связи. Применение вокодера позволяет снизить скорость передачи данных в канале, что принципиально важно для эффективного использования радио тракта и канала в IP-сетях. Основной принцип работы вокодера - синтез исходного речевого сигнала посредством адаптивной замены его гармонических составляющих соответствующим набором частотных фонем и согласованными шумовыми коэффициентами. Кодек G.723 осуществляет преобразование аналогового сигнала в поток данных со скоростью 64 Кбит/с (ИКМ), а затем при помощи многополосного цифрового фильтра/вокодера выделяет частотные фонемы, анализирует их и передает по IP-каналу информацию только о текущем состоянии фонем в речевом сигнале. Данный алгоритм преобразования позволяет снизить скорость кодированной информации до 5,3-6,3 Кбит/с без заметного для пользователя ухудшения качества воспроизведения речи. Кодек имеет две скорости и два варианта кодирования: 6,3 Кбит/с с алгоритмом MP-MLQ и 5,3 Кбит/с с алгоритмом CELP (Code Excited Linear Prediction) - линейное предсказание с кодовым возбуждением. Первый вариант предназначен для сетей с пакетной передачей голоса и обеспечивает лучшее качество кодирования по сравнению с вариантом CELP, но менее адаптирован к использованию в сетях со смешанным типом трафика (голос/данные). Класс речевых кодеров с линейным предсказанием и кодовым возбуждением (CELP) занимает промежуточное положение между кодерами формы сигнала и параметрическими вокодерами. Анализ параметров речевого сигнала осуществляется на интервалах 10-30 мс, что позволяет наиболее эффективно применять CELP при скоростях передачи от 4 до 16 Кбит/с.
Процесс преобразования требует от DSP 16,4-16,7 MIPS и вносит задержку 37 мс. Кодек G.723.1 широко применяется в голосовых шлюзах и прочих устройствах IP-телефонии. Кодек G.723.1 уступает по качеству кодирования речи кодеку G.729a, но менее требователен к ресурсам процессора и пропускной способности канала.
Кодеки G.729
Семейство включает кодеки G.729, G.729 Annex A, G.729 Annex B. Кодер содержит детектор активности источника речевого сигнала (Voice Activity Detector, VAD) и генератор комфортного шума. Детектор активности источника речевого сигнала предназначен для обнаружения и выделения интервалов активности источника или шума без речи. Порог принятия решения в детекторе не должен быть слишком низким, приводящим к частому срабатыванию от шумов. В то же время, порог не должен быть и слишком высоким, так как это приведет к вырезанию начала фразы и ухудшению разборчивости. Кодеки G.729 сокращенно называют CS-ACELP (Conjugate Structure - Algebraic Code Excited Linear Prediction), что переводится как "сопряженная структура с управляемым алгебраическим кодом линейным предсказанием". Процесс преобразования использует DSP 21,5 MIPS и вносит задержку 15 мс. Скорость кодированного речевого сигнала составляет 8 Кбит/с. В устройствах VoIP данный кодек занимает лидирующее положение, обеспечивая наилучшее качество кодирования речевой информации при достаточно высокой компрессии.
Кодек G.728
Гибридный кодек, описанный в рекомендации G.728 в 1992 г., относится к категории кодеков с управляемым кодом линейным предсказанием и малой задержкой (Low Delay - Code Excited Linear Prediction, LD-CELP). Кодек обеспечивает скорость преобразования 16 Кбит/с, вносит задержку при кодировании от 3 до 5 мс. Для его реализации необходим процессор с быстродействием более 40 MIPS. Кодек предназначен для использования, в основном, в системах видеоконференций. В устройствах IP-телефонии данный кодек применяется достаточно редко.
Основные характеристики рассмотренных кодеков приведены в таблице 3.
| Таблица 3
. Основные характеристики кодеков
|
| Кодек
|
Метод компрессии
|
Скорость кодирования
|
Сложность реализации
|
Качество
|
Задержка
|
| G.726 |
ADPCM |
32/24/16 Кбит/с |
Низкая (8 MIPS) |
Хорошее (32 К),
плохое (16 К)/TD> |
Очень низкая (0,125мс) |
| G.729 |
CS-ACELP |
8 Кбит/с |
Высокая (30 MIPS) |
Хорошее |
Низкая (10 мс) |
| G.729A |
CA-ACELP |
8 Кбит/с |
Умеренная (20 MIPS) |
Среднее |
Низкая (10 мс) |
| G.723.1 |
MP-MLQ |
6,4/5,3 Кбит/с |
Умеренная (16 MIPS) |
Хорошее (6,4),
среднее (5,3) |
Высокая (37 мс) |
| G.728 |
LD-CELP |
16 Кбит/с |
Очень высокая (40 MIPS) |
Хорошее |
Очень низкая (3-5 мс) |
Как видно из таблицы, наиболее предпочтительным среди приведенных методов кодирования с точки зрения соотношения качество речи
/ скорость потока
является алгоритм G.723.1.
Количественными характеристиками ухудшения качества речи являются единицы QDU (Quantization Distortion Units): 1 QDU соответствует ухудшению качества при оцифровке с использованием стандартной процедуры ИКМ; значения QDU для основных методов компрессии приведены в табл. 4.
Таблица 4.
Единицы ухудшения качества речи QDU для различных методов компрессии
| Метод компрессии |
QDU |
| ADPCM 32 кбит/с |
3,5 |
| ADPCM 24 кбит/с |
7 |
| LD-CELP 16 кбит/с |
3,5 |
| CS-CELP 8 кбит/с |
3,5 |
Дополнительная обработка речи всегда ведет к дальнейшей потере качества. Согласно рекомендациям МСЭ-Т, для международных вызовов величина QDU не должна превышать 14, причем передача разговора по международным магистральным каналам ухудшает качество речи, как правило, на 4 QDU. Следовательно, при передаче разговора по национальным сетям должно теряться не более 5 QDU. Поэтому для качественной передачи речи процедуру компрессии/декомпрессии желательно применять в сети только один раз. В некоторых странах это является обязательным требованием регулирующих органов по отношению к корпоративным сетям, подключенным к сетям общего пользования. Подавление пауз (silence suppression) - важная функция ATM-коммутаторов. Суть технологии подавления пауз заключается в определении различия между моментами активной речи и молчания в период соединения. В результате применения этой технологии генерация ячеек происходит только в моменты активного разговора. Поскольку в процессе типичного разговора по телефону тишина составляет до 60% времени, происходит двукратная оптимизация по количеству данных, которые должны быть переданы по линии. Объединение технологии сжатия речи и подавления пауз речи в коммутаторах приводит к уменьшению потока данных в канале до восьми раз.
Современные продукты для IP-телефонии применяют самые разные кодеки, стандартные и нестандартные. Конкурентами являются кодеки GSM (13,5 кбит/с) и кодеки МСЭ-Т серии G, использование которых предусматривается стандартом Н.323 для связи по IP-сети. Единственным обязательным для применения кодеком в Н.323-совместимых продуктах остается стандарт G.711: выдаваемые им массивы данных составляют от 56 до 64 кбит/с. В качестве дополнительных высокопроизводительных кодеков стандарт Н.323 рекомендует G.723 и G.729 - последние способны сжимать оцифрованную 16-разрядную ИКМ-речь длительностью 10 мс всего в 10 байт. Стандарт G.729 уже получил широкое распространение в системах передачи голоса по IP; его поддерживают значительное число производителей продуктов для IP-телефонии.
Глава 6: Вокодеры в современности.
В таблице 5 приведены основные виды вокодеров и требуемая пропускная способность канала связи.
Сегодня вокодеры применяют для кодировании телефонных сигналов в военных и коммерческих цифровых системах связи. Перспективно применение вокодеров для организации служебной телефонной связи со скоростью передачи данных 1 200 - 2 400 бит/с. Формантные и полосные вокодеры находят применение также при цифровой передаче телефонных сигналов по КВ-каналам радиосвязи.
 Таблица 5.
Основные виды вокодеров Таблица 5.
Основные виды вокодеров
Современные вокодеры обеспечивают хорошее качество речи при скорости передачи 4 800 - 2 400 бит/с и качество речи, пригодное для ведения служебных переговоров, при скорости передачи 1 200 бит/с.В таблице 6 приведен краткий список вокодеров, которые производятся в настоящее время.
 Таблица 6.
Перечень вокодеров, которые производятся в настоящее время. Таблица 6.
Перечень вокодеров, которые производятся в настоящее время.
Рассмотрим теперь в качестве примера один из выпускаемых вокодеров-липредеров вокодер LSP2400.
Разработчики для скорости 2400 бит/с выбрали вокодер с линейным предсказанием.
Структурно вокодер состоит из двух частей. Первая часть - анализатор, функции которого заключаются в выделении текущих параметров речевого сигнала и их упаковке в кадр соответствующего формата.
Вторая часть - синтезатор по принятому кадру восстанавливает с некоторой ошибкой параметры текущего фрагмента сигнала и с их помощью воспроизводит синтетическую речь.
Цифровой сигнал поступает на предыскажающий фильтр (1-0.9375*z-1) и далее из него посредством полусинхронной с основным тоном процедуры выделяется фрагмент анализа. Предыскажение, кроме компенсации высокочастотной части спектра речевого сигнала, служит для снижения необходимой точности вычислений.
Полусинхронная с основным тоном процедура выделения фрагмента анализа заключается во взвешивании фрагмента треугольным окном переменной длины, зависящей от текущего основного тона. Треугольное окно в данном варианте алгоритма располагается в центре фрагмента. После получения фрагмента анализа коэффициенты линейного предсказания вычисляются путем использования ковариационного метода. Выбор ковариационного метода (среди двух возможных: автокорреляционного и ковариационного) обусловлен тем, что длина фрагмента анализа определяется основным тоном, а при возможных малых значениях длины фрагмента автокорреляционный метод даст значительные искажения текущего спектра сигнала.
Оценка периода основного тона производится по алгоритму, основанному на базе метода Голда-Рабинера.
В канал связи передаются линейные спектральные частоты (LSF). Квантование спектральных частот выполняется на основе метода динамического программирования. В качестве конкретных квантователей использованы неравномерные квантователи из 34-битного независимого квантования LSF стандарта USFS-1016.
В синтезаторе производится задержка на 1 кадр, поэтому сглаживание канальных ошибок производится на основе принятых параметров из трех текущих кадров - прошлого, настоящего и будущего. Степень сглаживания параметров зависит от числа детектированных канальных ошибок. При увеличении числа ошибок в канале степень сглаженности возрастает.
В качестве возбуждения на невокализованных фрагментах используется белый шум, а на вокализованных - импульсный отклик фазового звена.
Синтезирующий фильтр реализуется в прямом виде. Его коэффициенты представлены с 16-разрядной точностью. Выходной сигнал пропускается через фильтр, обратный предыскажающему, и после цифро-аналогового преобразования синтетический сигнал поступает на выход.
Более подробное описание алгоритма речевого кодирования LSP2400 на скорости 2400 бит/с можно найти в книгах:
-Linear-Rrediction Vocoder for Speech Transmission with 2.4(1.2) kbit/sec rate, St.Petersburg State University of Telecommunication DSP Center, St.Petersburg, 1994
-Implementation of HF Modem for Digital Data Transmission, St.Petersburg Bonch-Bruevich State University of Telecommunication DSP Center, St.Petersburg, 1996
Заключение.
Алгоритмы кодирования формы сигнала основываются на наличии корреляционных связей между отсчетами сигнала, которые дают возможность линейного предсказания. В сочетании с адаптивным квантованием этот подход позволяет обеспечить хорошее качество речи при скорости передачи битов порядка 24-32 Кбит/с. По сравнению с другими подобными устройствами LPC-вокодеры
(липредеры) используют простую математическую модель голосового тракта и позволяют использовать очень низкие скорости передачи информации 1200-2400 бит/с, однако ценой «синтетического» характера речи.
Список используемой литературы.
1. Дж.Д.Маркел, А.Х.Грэй, «Линейное предсказание речи», перевод под редакцией Ю.Н.Прохорова и В.С.Звездина, М., изд. «Связь», 1980.
2. Калинцев Ю.К. Разборчивость речи в цифровых вокодерах. - М.: Радио и связь, 1991.
3. М.А.Сапожков, «Акустика.Справочник», М.,изд. «Радио и связь», 1989.
4. Интернет-сайт http://www.intuit.ru. Интернет-Университет Информационных Технологий.
5. Интернет-сайт http://www.bnti.ru/. Бюро научно-технической информации. По материалам 2-ой Всероссийской конференции "Теория и практика речевых исследований".
6. Интернет-сайт http://www.wikipedia.org/. Свободная энциклопедия.
7. Разные интернет-ресурсы, посвященные вокодерным технологиям.
|