Взаимосвязи эк перемен-х.
С того вр-ни как эк-ка стала самост наукой, исслед-ли пытаются дать предст-ия о возм-ых путях разв-ия эк-ки, предвидеть буд знач эк пок-лей, найти инст-ты, позволяющие изм-ть ситуацию в желат-м напр-ии и спрогнозир-ть ее развитие.
Но разл эк школы предлаг-т разные, а зачастую противопол-е методы решения этих задач. Пол-ки или управ-ие выбир-т 1 из предлаг-х методов решений. В рез-теполуч-т какой-то эффект. Плох он или хорош и м.б. дьбиться лучшего рез-та проверить затруд-но, т.к. эк ситуация никогда не повт-ся точно, т.е. нет возм-ти применить 2 разные стратегии при одних и тех же усл-ях и сравнить конеч рез-ты.
Поэтому 1-й из центр задач эконометр анализа яв-ся предсказ-ие или прогнозир-ие развития 1 и то1 же ситуации при создании тех или иных усл-ий.
Поведение люб эк пок-ля зависит от мно-ва фак-ров. Все их учесть реально невоз-но, но в этом и не возн-т необ-ти. Обычно только огран кол-во фак-ров возд-т на исслед-й эк пок-ль. Доля влияния ост-х незнач-на.
Введение в модель огрнан кол-ва ф-ров реально доминир-х в эк процессе яв-ся серьез-й предпосылкой для качест анализа прогнозир-я и упр-ия ситуацией.
Эк теория выявила мно-во устойч завис-тей. Нап-р хорошо изучена зав-ть спроса или потр-ия от ур-ня дохода и цен на товары; зав-ть м/у безраб-й и инфл-ей…
Люб эк пол-ка закл-ся в регул-ии эк перем-х и д базир-ся на знании того как эти перем-ые связаны с др ключевыми для принимаемого решения политиком или предприн-лем.
Пр-р:
Нельзя непоср-но регул-ть темп инфл-ии, но на нее м возд-ть ср-ми фискальной и монетар пол-ки. Поэтому прежде всего изуч-ся взаимосвязь м/у предл-ем дененг и ур-нем цен.
Но в реал ситуации даже устоявшиеся зав-ти м прояв-ся по-разному. Еще более слож задачей яв-ся анализ малоизуч и вновь возн-их нестаб-х завис-тей в эк-ке. Именно для них наиб-ее актуально построение эконометр моделей. Их невоз-но строить, проверять и совершен-ть без стать анализа реал эмпир данных. Но сам по себе стат анализ не вскрывает ситуации, возн-ей в эк-ке, он дает только соот-ие не показ-ыя в силу каких причин 1 перем-ая влияет на др.
Решение этой задачи яв-ся рез-том качест анализа получ-х соот-ий, кот-ый д сопровож-ся либо предшест-ть стат анализу.
В естест науках иссл-ли имеют дело со строго устан-мися зав-тями, когда опр знач-ю 1-й перем-й соот-т вполне опр знач-е др y=f(x). В бол-ве эк завис-ях такой взаимосвязи нет. Пр-р: нет строгой зав-ти м/у ур-нем дохода и потр-ия. Это связано со сно-вом причин. В част-ти с тем, что при анализе не учит-ся целый ряд р ф-ров, влияющих на переем-ые.
Кроме того влияние м.б. не прямым, а опосред-м. В треьих нек-ые влияния оказ-ся просто случ-ми, поэтому в эк-ке гов-т не о функц-х, а о коррел-х или стат завис-тях.
Корреляционная зависимость.
Стат наз-ся зав-ть
, пр кот-й изм-ие 1-й из величин влечет изм-ие распред-ия др вел-ны. В част-ти стат зав-ть, прояв-ся в том, что при изм-ии 1-й вел-ны, изм-ся матем ожидание (ср знач) др вел-ны, наз-ся корреляц-м
.
Поэтому сущность коррел анализа
м.б. продемонстр-на на 2-х вар-тах взаимосвязи м/у перем-ми.
I
).
Предпол-м, что мы рассм-ем поведение 2-х перем-х У и Х, кот-ые яв-ся равноценными в том смысле, что среди них нельзя выделить первичную (независ) и вторичную (завис) перем-ую. Нап-р: спрос на товар и его цена. При иссл-ии силы зав-ти м/у такими перем-ми обращ-ся к коррел анализу, основ-й мерой в кот-м яв-ся коэф-т выбороч коррел-ии -1≤rxy≤1.
Вполне вер-но, что связь в этих случаях м не носить направ хар-ра, а м показ-ть и одинак направ-ть, когда рост 1-й перем-й сопр-ся ростом знач-я др перем-й или наоборот.
II
).
Когда мы м выделить так назыв-ю объясняющ (независ) перем-ю и объясняемую (завис). В этом случае изм-ие 1-й из них яв-ся причиной для изм-ия 2-й, но такая зав-ть не яв-ся одннознач. Пр-р: выдел-ся неск-ко семей с одинак составом ее членов и одинак ур-нем дохода Х. Ур-нь потр-ия в этих семях м.б. разным у1,у2…ук., т.е каждому значению Х соот-т нек-ое случ распред-е У, т.е. У – яв-ся случ вел-ной (СВ).
Анализ-ся как в среднем объяняющ перем-я Х влияет на знач-ие объясняемой перем-й У.
М(у/х)=f(х). М – мат ожидание. m=1. Такое выраж-е наз-ся ф-ией регр-ии у на х.
Если мы рассм-м пару пок-лей Х и У, то речь идет о парной регрессии
.
Если мы рассм-м ф-ию, в кот-й поведение У зав-т от нек-го мно-ва фак-в М(У/х1,х2…х
m
)=
f
(
x
1,x2…
xm
),
то мы имеем дело с множест регр-ей.
Для отражения того факта, что реал знач-я завис перем-й не всегда совпадают с ее усл мат ожиданием, эта зав-ть доп-ся нек-м слогаемым, являющ-ся случ вел-ной, что указ-т а стахостич (стат) суть этой зав-ти.
У=М(У/х)+ε
У=М(У/х1,х2…хn)+ε
В таком виде записи, соот-ия наз-ся регрессионными урав-ми лин регресс моделями.
Осн причинами включ-ия в модель случ ф-ра (откл-ия) яв-ся:
1). Невключ-е в модель всех объясняющ перем-ых.
Любая модель – вседа упрощ-е реал ситуации и поэтому мы не м однозн-но гов-ть о знач-ях объясняемой перем-й в этих ситуациях.
2). Неправ-й выбор функц формы модели
, что зачастую возн-т в усл-ях слабой изучен-ти эк процесса.
III
). Агрегир-ие перем-ых.
Во многих моделях исп-ся зав-ти м/у какими-то фак-ми, кот-ые сами предс-т слож комб-ии др более простых фак-ров. Изм-ие этих простых фак-ров м оказать влияние на поведение обопщенных пок-лей, но мы в модели этого не учтем. Пр-р: сов спрос и сов предл.
IV
). Ошибки изм-ий
, кот-ые отраж-ся на несоответ-тт модел знач-й эмпир данным (з/п в конверте).
V
). Огранич-ть стат данных.
Мы строим лин модель, являющ-ся непрерыв-й, но для ее постр-ия исп-ем огран выборку из массива ген сов-ти данных, что наклад-т огран-ия на соот-ие модели эмпир данным.
VI
). Непредказ-ть чел фак-ра
.
Эта причина м испортить люб самую качест модель.
Т.о. случ слогаемые в модели отраж-т влияние мно-ва субъек-ых ф-ров. И решение задачи постр-ия модели, соот-ей эмпир данным и целям иссл-ия яв-ся слож многоступен-й процессом, кот-ый м разбить на 3 этапа:
1).
Выбор формы урав-ия регр-ии.
2).
Опр-ие парам-в выбранного ур-ия.
3).
Анализ кач-ва постр-го ур-ия и проверка его соотв-ия (адекват-ти) эмпир данным, на основе кот-ыхвозм-но соверш-ие ур-ий.
Выбор формы зав-ти – спецификация ур-ия
.
В лучае парной регр-ии он осущ-ся с помощью постр-ия коррел поля.
График
В осях коор-т y=M(У/x)+ε для зав-ти наносятся точки выборки х1у1; х2у2; х3у3…хiyi…xnyn. (xiyi) i=1;n.
Получили коррел поле или диаграмму рисования.
Возм-ны разл ситуации.
3 Графика
На 1) связь м/у х и у близка к лин-й.
На 2) ее нельзя предст-ть как лин зав-ть Скорее всего это парабола.
На 3) явная зав-ть м/у х и у отсут-т. Какую бы зав-ть мы не выбрали рез-ты моделир-ия б неуд-ны.
В случае множест регр-ии У=М(У/х1,х2…хn)+ε
Задача опр-ия вида зав-ти услож-ся.
Парная линейная регрессия.
Если ф-ия регр-ии линейна, то гов-т о лин регр-ии, кот-ая соот-т требованию линей-ти отн-но ее парам-ра.
В таких моделях теорет ур-ие регр-ии У=М(У/х)+ε =β0+β1х+ε, коэф-ты β0 и β1 наз-ся теоретич коэф-ми
, ε – случ теорет откл-ие.
Для любой выбороч пары х и yi, yi= β0+β1хi+ε, т.е. индив знач-е у предст-ны в виде суммы 2-х компонентов: систем-ой
β0+β1хi и случайной
εi.
В соот-ии с общей генер сов-тью всевозм-х сочетаний у и х, модель запис-ся в форме У= β0+β1Х+ε
и задача построения урав-ия сост-т в том, чтобы по имеющ-ся выборке огран-го объема (хi;yi) i=1,n получить эмпир ур-ие регр-ии ỹ
=
b
0+
b
1
x
, где b0 и b1 – оценки для коэф-тов теорет ур-ия.
Тогда по данным выборки ỹi=b0+b1xi, получ-е знач-е для у б.отл-ся от теорет-го на нек-ую вел-ну, харак-ую точность оценки эмпир урав-ем теорет знач-ия завис-й переем-ой yi
-
ỹ
i
=
ei
.
=> в общем виде мы получ-м yi=b0+b1xi+ei.
Но т.к. оценки для коэф-та β0→b0 и β1→b1 расч-ся по конкр-м выборкам, то для разных выборок из одной и той же генер сов-ти м.б. получ-ны отличающ-ся знач-ия.
Задача сост-т в том, чтобы найти наилучшие из этих оценок.
Т.к. нас не интер-т разность знач-ий завис перем-й по теорет и эмпир ур-иям (мы не знаем теорет Ур-ия), то под откл-ми б.понимать М(У/хк)-ук (теорет откл-ие) = εк. εк- это откл-ие точки выборки от ее теорет вел-ны, а ук-ỹк=ек – (эмпир откл-ие) откл-ие эмпир знач-я от соотв-ей вел-ны, получ-ой по построй-ой модели. И не б.ставить около ук выборки.
Задача моделир-я сост-т в том, чтобы минимиз-ть все откл-ия эмпир знач-ий завис переем-ой от соот-их вел-н рассчит-х по модели.
Это м сделать за счет минимизации 1-й из след-х ∑:
1).
∑ei=∑(yi-ỹi)= ∑(yi-b0-b1xi)
Минимум такой ∑ не м. яв-ся мерой кач-ва урав-ия, т.к. сущ-т мно-во прямых линий, для кот-ых ∑ei=0, в част-ти у=у ср
2).
∑|ei|=∑|yi-ỹi|= ∑|yi-b0-b1xi|. Обычно называют методом наименьших модулей (МНМ). Реализ-ия этой задачи дел-ся методом градиентного спуска.
3).
∑ei²=∑(yi-ỹi)²= ∑(yi-b0-b1xi)²
Минимизация такой ∑ яв-ся наиболее разраб-й. Получила название метода наименьших квадратов (МНК). Вычисл процедуры наиболее просты по срав-ию со всеми ост-ми методами. И при выпол-ии опр-х предпосылок оценки парам-ов ур-ия b0 и b1 облад-т оптим св-вами.
Кроме 3-х названных еще исп-ся метод момента (тер вер) и методы max правдоподобия.
Метод наименьших квадратов (МНК).
Состоит в минимизации нек-й ф-ии Q(bo,b1)=∑ei²=∑(yi-bo-b1xi)². Всегда, когда ничего др не указано, суммир-ие от 1 до n. Из урав-ия очевидно, что это квадрат-я ф-ия, у кот-ой сущ-т экстремум в форме минимума. Ф-ия Q непрер-на и вогнута ↓.
Необх-м усл-ем для нахожд-я точки ее min яв-ся рав-во произв-х ф-ий по пар-рам bo, b1, 0. ∂-част произ-ая.
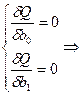
Когда перем-я только одна вел-на, а все ост-ые знач-ия xi рассм-ся как const.
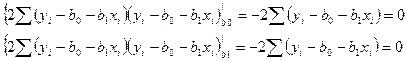
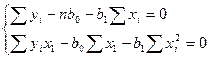
bo и b1 – const, поэтому они вынос-ся из знака ∑.
Разделим оба ур-ия на n.

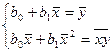
Получили сис-му из 2-х ур-ий с 2 неизв-ми. Она имеет единст рещение, если ее опр-ль ≠0.
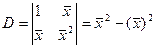
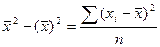
- дисп-ия разброса объясн-й перем-й. Она в случ выборках никогда ≠0. А если это происх-т, то дост-но из выборки изъять 1 пару или добавить и усл-ие б вып-ся.
D≠0
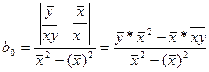
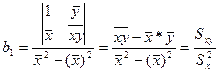
Выраж-е, стоящее в числ-ле предс-т собой ковариацию м/у перем-ми х и у.
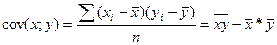
Отсюда ковариация перем-ой самой с собой предст-т дисп-ию
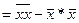
Чтобы получить bo его знач-ия
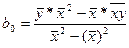
В числ-ле прибавим и отнимем 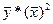
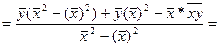
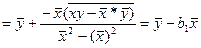
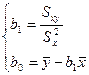
=> bo и b1 расч-ся по выборке и bo только гаран-т прохождение линии регр-ии ч/з ср точку выборки.
Рас-м коэф-т 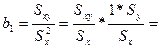
Умножим и разделим на Sу/
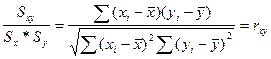
Это коэф-т выбороч корре-и м/у х и у.
=> b1 пропорц-ен коэф-ту выбороч коррел-и, а коэф-м пропорц-ти яв-ся отн-ие стандартов откл-ий рассматр-х фак-ров, что позволяет соизмерить эти ф-ры даже при усл-ии, что они яв-ся разноразмерными вел-ми.
Т.е. в лин ур-ии ỹ=bo+b1x х и у м иметь разн ед-цы изм-ия. Допустим х – тыс руб, у -%. Если r уже рассчитан, то мы м легко найти ур-ия парной регр-ии у на х и построить ур-ие х на у.
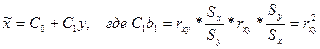
Отсюда 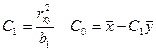
Проведенные рассуж-ия позволяют сделать неск-ко выводов:
1).
Оценки коэф-тов по МНК позв-т их легко расч-ть, т.к. яв-ся ф-ями от выборки.
2).
Оценки яв-ся точечными (числовыми) оценками теорет-х коэф-в.
3).
Вычисления коэф-та bo всегда пок-т, что люб ур-ие регр-ии всегда проходит ч/з ср точку выборки 
4).
Ур-ие регр-ии строится так, что ∑ei=0 => 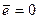
Покажем это. Из сис-мы ур-ий для коэф-в д вып-ся усл-ие
-2∑(yi-bo-b1xi)=0
-2∑(yi-ỹi)=0
-2∑ei=0 =>∑ei=0
5).
Случ откл-ия ei некоррел-ны (не зависят) со случ вел-ми yi.
6).
Случ откл-ие ei не коррел-т с объясняющими перем-ми, т.е. Sxe=0.
Для опр-ия вида зав-ти построим поле коррел-ии.
Для вычисления по МНК стр-ся табл.
Для анализа правил-ти опр-ия коэф-в необ-мо расч-ть ỹi и ei=(yi-ỹi)
Для анализа силы лин зав-ти вычисляем коэф-т коррел-ии.
Под интерпретацией пон-ся словесное описание получ-х рез-тов с трактовкой найденных коэф-в так, чтобы получ зав-ть стала понятна ч-ку, не имеющего навыков эконометр анализа. После интерпретации рез-тов всегда встает вопрос о кач-ве оценок и самого ур-ия в целом.
Проверка качества уравнения регрессии.
Регресс-й анализ позвол-т найти точечные оценки коэф-в ур-ий регр-ии. При этом мы знаем, что знач-е завис-й перем-й yi=βo+β1xi+εi зависит от случ откл-ий εi=> У случ вел-ны, завис-ие от этих откл-ий. И пока мы не опр-м какому закону распред-ия подчинены случ вел-ны εi, мы не м.б. уверены в кач-ве оценок коэф-в урав-ия, а => и самого ур-ия ỹ=bo+b1x.
Причем б показано, что 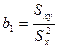 , т.е. это тоже случ вел-на, причем если х м считать экзогенным
(задав-м из вне) фак-ром, то у – случ вел-на. , т.е. это тоже случ вел-на, причем если х м считать экзогенным
(задав-м из вне) фак-ром, то у – случ вел-на.
Теорет-ки b1 м разложить на неслуч и случ составл-ую. Для этого рассм-м ковариацию м/у х и у.
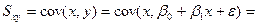
и воспол-ся нек-ми правилами для вычисл-ия ковариации:
1). cov(u,a)=0
2). cov(u, av)= a cov(u,v)
Тогда = cov(x,βo) +cov(x,β1x)+cov(x,ε) = β1cov(x,x)+cov(x,ε) = β1S²x+cov(x,ε)
Отсюда 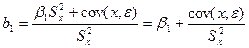
β1 – нек-ая const, а 2 слогаемое предст-т случ составл-ую, входящую в вел-ну коэф-та.
Но т.к. мы не знаем теоретич-х откл-ий ε, то рассч-ть это слогаемое непоср-но нельзя.
Точно также м показать, что коэф-т do имеет случ и неслуч состав-ую.
Доаказано, что для получения по МНК наилуч-х рез-тов необ-мо, чтобы выпол-ся ряд требований отн-но случ вел-ны ε.
Предпосылки МНК (условия Гаусса-Маркова).
1).
Матем ожидание случ откл-ия ε=0 для всех набл-ий М(εi)=0 для люб εi. Это усл-ие озн-т, что в ср случ откл-ие не оказ-ют влияние на завис переем-ую, хотя в каждом из набл-ий они м.б. положит или отрицат, больш или малыми, но не д.б. причины, чтобы εi имело системат-ие откл-ия.
2).
Дисп-ии откл-ий пост-ны.
D(εi)=D(εj)=σ²=const i≠j.
Подразумевает, что несмотря на то, что в каждом из набл-ий случ откл-ия м.б. различ-ми, нет никакой причины, вызывающей большую или меньшую ошибку при опр-ии откл-ий.
Выполнимость этой предпосылки наз-т гомоскедастичность
, ее невыпол-ие гетероскедастичность
.
Рассм-м, что это озн-т.
D(εi)=M(εi-M(εi))²=
По 1 усл-ию M(εi)=0, поэтому = M(εi)²
И => усл-ие м записать M(εi)²=σ².
Причины и последствие невыпол-ия этой предпосылки б рассм-ть в общем анализе.
3).
Случ откл-ие εi и εji≠j не зависят др от др. Это означает, что отсут-т систем-я связь м/у 2 любыми парами откл-ий, т.е.

Если это усл-ие вып-ся, то гов-т об отсут-ии а/коррел м/у случ откл-ми.
Это соотн-ие еще перепис-т в форме M(εi,εj)=0 (i≠j).
4).
Случ откл-ие д.б. незав-мо от объясняющ-х переем-х. Обычно это усл-ие вып-ся автомат-ки, если объяснящие перем-ые – известные вел-ны.
Но м показать, что в принципе это выпол-ся в любых мделях данного типа.

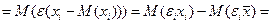
Пояснение 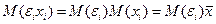
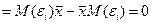
5).
Модель яв-ся линейной отн-но ее парам-ов βо β1.
Теорема Гаусса-Маркова.
Основ-ся на предпосылках МНК.
Если все 5 предпос-к вып-ся, то оценки коэф-в, получ-е с помощью МНК облад-т след сво-вами:
А).
Оценки яв-ся несмещенными, т.е.
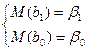
Б).
Оценки яв-ся состоятельными, т.к. дисп-ии их с ростом объема выборки стрем-ся к 0.
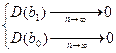
Т.е. ↑ объема выборки приводит к устойчивости оценок коэф-в ур-ия. Сч-ся, что объем выборки д удовл-ть соот-ию n>3m-1, где m-кол-во объясняющих переем-х.
В).
Оценки эфф-ны, т.е. они имеют наименьшую дисп-ию разброса отн-но теорет-х вел-н по срав-ию с такими же оценками полученных с примен-м и люб др методов расчета.
В англоязыч науч лит-ре эти оценки получ-ли название BLUE
(голубые оценки) по первыем буквам (наилуч лин состоят эффект). Если наруш-ся предпосылки 2 и 3, то дисп-ии откл-ий не пост-ны, случ откл-ия связаны др с др и коэф-ты теряют св-ва несмещен-ти и эффек-ти.
При этос б сделаны след предположения:
1). Объясняющ перем-ые не яв-ся случ.
2). Случ вел-ны εi имеют норм распр-ие с пар-ми 0 и ε²
εi²~N(0;σ²)
Число набл-ий n>3m-1 сущ-но > числа объясняющ перем-х. Отсут-т ошибки специф-ии. М/у объясняющ перем-ми в случае m≥2 отсут-т зав-т (мультикол-ть).
Анализ точности определения оценок коэффициентов регрессии.
Изв-но, что мат ожидания расчет коэф-в совпадают с их теоретич вел-ми
При этом чем < откл-ие оценок от этих теоретич вел-н, тем надежнее построенное ур-ие.
Покажем, что дисп-ии оценок D(b1) и D(bo) непоср-но связаны с дисп-ей случ откл-ий в теоретич модели D(εi)=D(εj)=σ²=consti≠j.
Для этого запишем вел-ну b
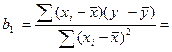
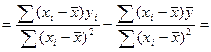
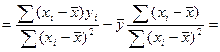
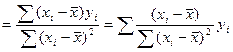
Обозначим за 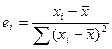
=∑Сiyi
Аналог-но преобр-м знач-е для bo.
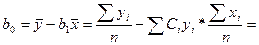
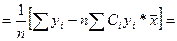
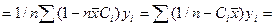
Обозначим 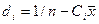
=∑diyi
Причем Ci и di –нек-ые const рассчит-е по выборке, что очевидно из их обозначений.
Оценим теперь вел-ну дисп-ий для коэф-та b1
D(b1)=D(∑Ciyi)=
И т.к. мы знаем значение для дисп-ии разброса случ откл-ий, то м записать
=σ²∑Сi²=
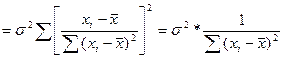
Т.о. мы нали знач-ие дисп-ии на основе дисп-ии теоретич откл-ия ε.
Аналог-но для bo.
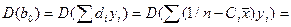
Мы м получить, что она равна
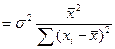
D(bo)=D(b1)x²
Т.о. дисп-ия разброса коэф-та прямопропорц-на дисп-ии случ откл-ий => чем > фак-р случ-ти, тем менее точными б оценки и чем > число набл-ий в выборке, тем меньше б эти вел-ны разбросаны.
Кроме того дисп-ии обратнопропорц-ны выбороч дисп-ии объясняющ перем-й S²x, т.е. чем шире область изм-ий объясняющ перем-й, тем точнее б оценки. Но в силу того, что дисп-ии случ теоретич откл-ий σ² нам неиз-ны, мы б их заменять несмещен-й дисп-ей расчет случ откл-ий.
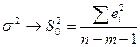 , ,
где m- число объясняющ переем-х. Для парной регр-ии 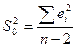 . .
Тогда стандарт откл-ия 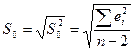
Наз-ся стандартной ошибкой в случ откл-ии. И для того, чтобы рассч-ть дисп-ию разброса коэф-в эмпир-го ур-ия регр-ии, мы б исп-ть формулы
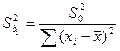
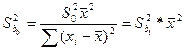
Проверка гипотез относ-но коэф-ов лин ур-ия регр-и.
Эмпир ур-ия регр-ии строятся на основе конеч выборки, извлеч-й из генер сов-ти случ образом, поэтому как б показано коэф-ты ур-ия яв-ся случ вел-нами.
При проведении эк анализа перед иссл-лями оч часто возн-т необ-ть сравнить расчет коэф-ты bo и b1 с нек-ми теоретич коэф-ми βо и β1.
Это срав-ие осущ-ся по схеме проверки гипотез. Предпол-м, провер-ся гипотеза Но:, состоящая в том, что эти вел-ны совпадают.
Но:=b1=β1. Тогда с ней конкурир-ая гипотеза Н1: не совпадает. Как изв-но из тер.вера для проверки таких гипотез рассч-ся t стат-ка Стьюдента, кот-ая при справед-ти гипотезы но имеет распред-ие Стьюдента с числом степеней свободы с парной регр-ей
tb1= (b1-β1)/Sb1
ν=n-2 (n-m-1)
n – объем выборки
m– кол-во объясняющ перем-х
Гипоеза Но б отклонена, если расчет знач-ие по модулю, т.к. нам безрал-но в какую сто-ну произошло откл-ие, окаж-ся > или = вел-ной, найденной из табл Стьюдента.
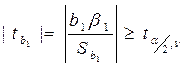
α-ур-нь знач-ти.
Сч-ся, что в эк задачах α м принимать знач-я 0,05 или 0,01, т.е. мы поверяем гипотезу с вер-тью 95 или 99%.
α/2 берется в связи с тем, что откл-ие м.б. как отриц, так и положит.
При невып-ии этого усл-ия сч-ся, что нет осн-ий для откл-ия гипотезы Но. Однако вел-ны теорет коэф-в как правило неиз-ны, поэтому на начал этапе анализа рассм-ся задача о наличие зав-ти м/у фак-ми х и у. Эта проблема провер-ся на основе гипотезы Но:b1=0 связи нет. С ней конкур-т H1:b1≠0 связь присут-т.
В такой пост-ке гов-т, что провер-ся гипотеза о стат знач-ти коэф-та ур-ия регр-ии.
Если приход-ся принять гипотезу Но, то мы гов-м коэф-т незначим (слишком близок к 0) и соответ-ю объясняющ перем-ую скорее всего из ур-ия следует искл-ть. В против случае коэф-т стат-ки значим. Н указ-т на наличие опр-й лин зав-ти м/у фак-ми.
Тогда расч-ся стат-ка Стьюдента по соотн-ю 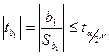 и по таблицам Стьюдента находят соответ-но вел-ну и по таблицам Стьюдента находят соответ-но вел-ну 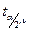 . .
Если она ≤ расчет вел-ны, то мы м сказать, что есть осн-ия отклонить гипотезу Но и принять Н1.
Коэф-т отличен от 0. Для парной регр-ии мы не б проверять стат знач-ть bo, т.к. он только гаран-т прохождение линии регр-ии ч/з ср точку выборки.
Сущ-т грубое правило, позвол-ее делать первонач выводы о поведении коэф-в ур-ия при отсут-ии таблиц Стьюдента.
По нему срав-ся вел-на ошибки Sb1, допущенной при нахождении коэф-та с вел-ной этого коэф-та.
А).
Если станд ошибка > чем коэф-т, то 0<|tb1|≤1. В этом случае гов-т коэф-т незначим.
Б).
Если ошибка не превосх-т половины вел-ны коэф-та, то 1<|tb1|≤2. Гов-т коэф-т слабозначим.
В).
Если они соот-ся в диапозоне 2<|tb1|≤3, то коэф-т значим.
Г).
Если ошибка <1/3 коэф-та, то 3<|tb1|, коэф-т сильно значим. Это гарантия наличия практ-ки лин зав-ти м/у изучаемыми фак-ми.
Безусл-
но на tb1 сущест влияние оказ-т объем выборки n.
Чем >n, тем <погр-ть.
Но при n>10 выписанное грубое правило оценки раб-т практически всегда.
Интервальные оценки коэффициента линейного уравнения регрессии.
Если для эмпир ур-ия выпол-ся предпос-ки Гауса-Маркова, то мы м утвер-ть, что найденные оценки коэф-в б подчин-ся норм закону распред-ия, в соот-ии с кот-м теоретич откл-ие εi распр-ны нормально с пар-ми 0 и σ².
εi~N(0;σ²)
Это усл-ие соглас-ся с усл-ми центр предел теоремы тер.вера
, в соот-ии с кот-ой если случ вел-на испыт-т влияние оч большого числа независ-х случ вел-н, влияние каждой из кот-ых на эту случ вел-ну мало, то рассматр-ая случ вел-на имеет распред-ие близкое к нормальному (асимптотически нормальное).
А мы пок-ли, что εi как раз отражают влияние, оказываемое на завис перем-ую фак-ми не включ-ми в модель, кот-ых в эк-ке как правило оч много. Но их влияние на у мало, иначе мы д.б. бы их вкл-ть в модель.
=> если n≥3-1, то у нас вып-ся усл-ия центр пред теоремы. Мы м гов-ть, что εi распр-ны нормально, а это позв-т не только найти наилучшее BLUE оценки для коэф-та, но и построить для них интервальные оценки, что дает опред-ые гарантии проверки точности нахождения коэф-в при смене исход-й выборки.
Причем к-т b1=∑Ciyi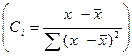 также как и у объясн-я перем-я, являясь лин комб-ей его выбороч вел-н yi при Ci=const, также б иметь норм распред-ие. Причем мы пок-ли уже, что его мат ожидание совп-т с вел-ной теорет к-та, а дисп-ия также как и у объясн-я перем-я, являясь лин комб-ей его выбороч вел-н yi при Ci=const, также б иметь норм распред-ие. Причем мы пок-ли уже, что его мат ожидание совп-т с вел-ной теорет к-та, а дисп-ия
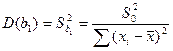
=> к-т b1 имеет норм распр-ие с пар-ми β1, D(d1).
Поэтому t стат-ка для коэф-та подчинена распр-ию Стьюдента с доверит-й вер-тью γ=1-α, что соот-т утвер-ию
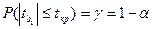
Тогда мы м записать, что вер-ть
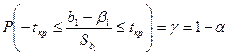
Преобр-м выраж-ие, стоящее в скобках
-tкрSb1≤b1-β1≤tкрSb1
-b1-tкрSb1≤-β1≤tкрSb1-b1
-b1-tкрSb1≤β1≤b1+tкрSb1
Получ соот-ие дает доверит-й инт-л, кот-ый с надеж-тью 1-α покрывает теорет коэф-т β1.
Доверительные интервалы для зависимой переменной.
Одной из осн-х задач эконометр анализа яв-ся прогнозир-ие знач-ий завис перем-ой при опр-ых знач-ях Хпр объясн-й перем-ой.
Здесь возм-н двоякий подход. Либо предсказ-ся усл-ое мат ожидание объясн-й перем-ой при нек-ой объясн-й перем-ой Хпр. М(У/х=Хпр). Либо прогноз-ся нек-ое конкр значение завис перем-ой при извест-м значении объясн-й перем-ой. Тогда гов-т о предсказании конкр вел-ны
1). Предсказание ср значения.
Предпол-м, что мы построили нек эмпир значение парной регр-ии ỹi=b0+b1xi, на основе кот-го хотим предсказать ср вел-ну завис перем-й у при х=Хпр. В данном случае рассчит-ое по урав-ию вел-на ỹпр=b0+b1xпр яв-ся только оценкой для искомого мат ожидания.
Встает вопрос насколько м эта оценка откл-ся от ср мат ожидания для того, чтобы ей м.б. доверять с надеж-тью γ=1-α.
Чтобы построить доверит инт-л, покажем, что случ вел-на ỹпр имеет норм распр-ие с нек-ми конкр переем-ми.
Мы знаем, что ỹпр=b0+b1xпр. Подставим в это ур-ие знач-ие для bo и b1, найденное в виде лин комбинаций выборочных вел-н объясн-й перем-й yi.
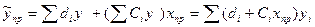
Т.е. мы пок-ли, что расчет вел-на яв-ся лин комб-ей нормально распред-й случ вел-ны yi=> она дейст-но имеет норм распред-ие и мы м рассч-ть пар-ры этого распред-ия М(Ỹпр) и D(Ỹпр).
М(Ỹпр)=M(bo+b1Xпр)= М(bo)+XпрM(b1) = βo+Xпрβ1
D(Ỹпр)=D(bo+b1Xпр) =
Т.к. bo вычисл-ся ч/з значение для b1, то они м/у собой зависят и поэтому
= D(bo)+X²прM(b1)=2cov(bo,b1Xпр)***=
Рас-м вел-ну ковариации.
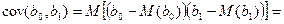
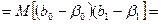
Заменим вел-ну bo ч/з правило ее вычисления из эмпир ур-ия регр-ии, аналог-но поступим со знач-ем βо, записав его знач-ие ч/з теорет ур-ие регр-ии.
Тогда получаем
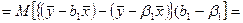
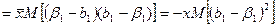 - -
это дисп-ия для значения b1 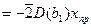
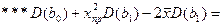
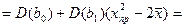
Мы знаем вел-ну дисп bo и b1. Подставим сюда их значения:
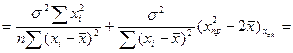
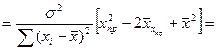
Преобразуем данное выр-ие прибавив и отняв к скобке 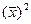

 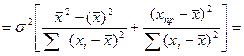
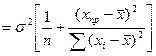
В этом выр-ии заменяем σ² несмещенной оценкой по эмпир ур-ию регр-ии σ²=∑ei²/n-2 и тогда мы м рассчитать Т стат-ку
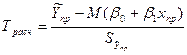
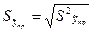 , получаемого из значения теорет дисп-ии заменой дисп теорет откл-ия σ² на So², вычис-ое по выборке ∑ei²/n-2. А тогда мы м, используя табл Стьюдента, выч-ть вер-ть того, что |T|≤tрасч , получаемого из значения теорет дисп-ии заменой дисп теорет откл-ия σ² на So², вычис-ое по выборке ∑ei²/n-2. А тогда мы м, используя табл Стьюдента, выч-ть вер-ть того, что |T|≤tрасч
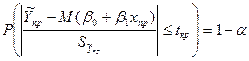
Тогда 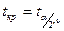 ν=n-2. ν=n-2.
И м посчитать, сделав такие же преобр-ия как для коэф-в ур-ия, что мат ожидание нах-ся в инт-ле:
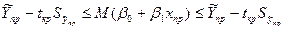
2). Предсказание индив знач-ий завис перем-й.
Предположим, что нас интер-т нек-ое конкр-е знач-ие вел-ны завис-й перем-й yo. При ее сопост-ии со знач-м, кот-ое м.б. рассч-но по ур-ию регре-ии.
Мы знаем, что yo б норм распр-но с пар-ми ỹ~N(βo+β1xпр;σ²). Одновр-но с этим
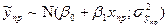 с таким же ср и дисп-ей, рассч-й для ỹпр. с таким же ср и дисп-ей, рассч-й для ỹпр.
Построим нов перем-ую U= ỹo- ỹпр и нас б интер-ть поведение такой случ вел-ны.
М(ỹо- ỹпр)= М(ỹо)-М(ỹпр)=0
D(ỹо- ỹпр)= D(ỹо)+D(ỹпр)=>
Каждую из кот-ых мы м оценить, используя выбор значения.
=>S²(ỹj-ỹпр)= S²(ỹо)+S²(ỹпр)
Каждая из них нам изв-на. Первая вел-на оцен-ся
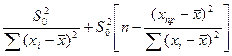
Т.о. мы м расч-ть стандарт ее откл-ия в рез-те чего получили Трасч данной случ вел-ны.
Проверка общего кач-ва ур-ия регрессии. Коэф-т детерминации
R
².
Расчет ур-ие регр-ии всегда проходит так, что не все точки выборки принадлежат этой прямой. Обычно оно лишь частично объясняет поведение точек выборки. Сущ-т диаграмма Венна, позволяющая интерпретир-ть ур-нь этой оценки.
5 графиков:
На счеме 1 х никак не влияет на поведение У. 2;3;4 пок-т все усиливающееся влияние объясняющей перем-й на объясняемую. На 5 ф-р х полностью объясняет поведение У.
Суммарной мерой общего кач-ва ур-ия регр-ии яв-ся коэф-т детерминации R².
Поясним его смысл и покажем методику вычисления.
Предпол-м, что мы рассч-ли эмпир ур-ие рер-ии ỹ=bo+b1x. Тогда yi=ỹ+ei.
Рассм-м вел-ну откл-ия точек выборки завис-й перем-й от их ср вел-ны.
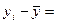 Преобразуем эту разность прибавив и отняв от нее соответ-е знач-ие, рассчит-е по ур-ию регр-ии. Преобразуем эту разность прибавив и отняв от нее соответ-е знач-ие, рассчит-е по ур-ию регр-ии.
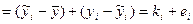
Тогда 2 слогаемое – та часть, кот-ая не объяснена в этом откл-ие ур-ем регр-ии, а 1 это часть объясненная ур-ем регр-ии. Получ выр-ие возведем в квадрат.
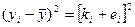 и просуммир-м по всем знач-м i. и просуммир-м по всем знач-м i.
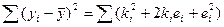
Рассм-м сред слогаемое

Мы получили знач-ие для мат ожидания вел-ны
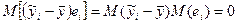
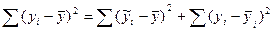
Разделим это рав-во на лев часть.
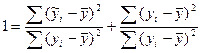
В лев сто-не записана доля разброса точек выборки отн-но ур-ия регр-ии и доля разброса не объясненная этим ур-ем.
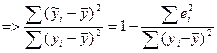
Т.е. объясненная доля разброса, если ее принять за коэф-т детер-ии ур-ия б опр-ся как
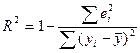
Очевидно, что 0≤R²≤1, т.е. когда ∑ei²=0, все точки выборки лежат а прямой линии регр-ии, то R²=1 идеальный вар-т.
А если 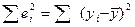 совпадает с дисп-ей разброса объясняемой перем-й, т.е. ур-ие регр-ии ничего не объяснило в поведении завис перем-й R²=0. совпадает с дисп-ей разброса объясняемой перем-й, т.е. ур-ие регр-ии ничего не объяснило в поведении завис перем-й R²=0.
Возм-ны усл-ия наруш-ия этого соотн-ия, при кот-ых R²≤0. Они связаны с тем, что неправ-но выбрана специф-ия модели, т.е. вид зав-ти м/у х и У.
Если модель строится на основе данных врем-х рядов, то R² как правило нах-ся в диапазоне 0,6≤R²≤0,7.
Покажем как в случае парной регр-ии коэф-т детер-ии связан с вел-ной выбороч-й коррел-ии м/у перем-ми х и У.
Для этого выпишем долю разброса, объясненную ур-ем регр-ии.
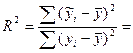
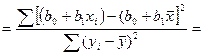
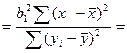
Запишем вместо b1 его вел-ну:
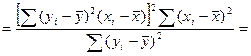
Числ-ль и знам-ль преоб-м для чего умножим их на ∑ квадратов откл-ий по объясняющ перем-й
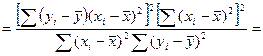
Заметим, что 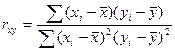
Тогда мы в нашем выраж-ии
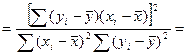
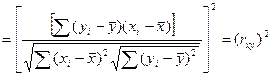
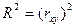
Множественная линейная регрессия.
Общеиз-но, что на люб эк пок-ль чаще всего оказ-т влияние не 1, а какие-то мно-во ф-ров. Тогда мы д исп-ть ур-ие множест регр-ии y=βo+β1x1+β2x2…+βmxm+ε, те.е знач-ие у зависит от m ф-ров.
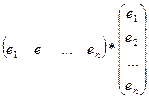
При m≥2, регр-ия сч-ся множест-й. Если мы составим нек-ый вектор
 m х 1, то мы м рассм-ть как ур-ие заданное в векторно-матричной форме, сформировав из значений объясняющ-х перем-ых некую матрицу, строками кот-ый яв-ся значения объясн-й перем-й, входящие в 1 выборочную компоненту. m х 1, то мы м рассм-ть как ур-ие заданное в векторно-матричной форме, сформировав из значений объясняющ-х перем-ых некую матрицу, строками кот-ый яв-ся значения объясн-й перем-й, входящие в 1 выборочную компоненту.
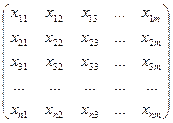
Столбцы представлены наборами значений каждого из фак-ров, входящих в модель.
Тогда сов-ые знач-ия завис перем-й м.б. предст-ны в виде в-ра столбца.
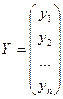
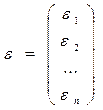
Случ откл-ия также м рассм-ся как нек-ый столбец
Но исходя из того, что в модели при βо всегда коэф-т =1, то матрицу значений объясн-их перем-ых пополняют 1-м столбцом, состоящим из 1 и обознач-т за Х.
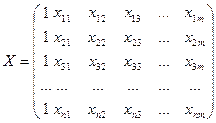
Эта матрица имеет размерность nx (m+1).
Ур-ие регр-ии в матрично-вей форме мы м представить как У=Хβ+ε
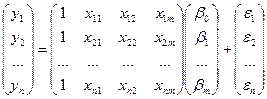
При этом д вып-ся усл-ие n≥3m-1 и все усл-ия Гауса-Маркова, кот-ые кратко запишем в форме
1).
М(εi)=0 для люб i.
2).
D(εi)=D(εi)=σ² для люб i и j
3).
Отсут-т связь м/у откл-ми 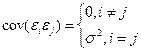
4).
Случ откл-ия не зависят от объясняющ перем-ых cov(εi;xi)=0.
5).
Модель линейна отн-но расчет пар-ов, но в ур-ях множест регр-ии возн-т необ-ть выпол-ия еще одного усл-ия.
6).
В модели отсут-т соверш мульт-ть м/у объясняющ перем-ми. Нап-р: в модель нельзя одновр-но включать данные годовые и квартальные в этом же году, т.к. годовые склад-ся из поквартальных.
7).
Как уже б показано для исп-ия t стат-ки и расчета стандартов откл-ий д вып-ся требование о том, что случ откл-ия εi имеют норм распр-ие εi~N(0;σ²). Выполнимость этой предпосылки дает возм-ть при соотв-ии модели осн требованиям модели Гауса-Маркова утвер-ть, что мы нашли наилучшие оценки коэф-в ур-ия, чем м бы их получить, используя люб др метод нахождения.
Предпол-м, что мы вычислили оценки коэф-та, тогда ур-ие множест регр-ии, построенное на основе выборки, б запис-ть в форме аналогич записи в парной регр-ии.
ỹ=bo+b1x1+b2x2+…+bmxm
y=bo+b1x1+b2x2+…+bmxm+e, где е – вектор расчетных откл-ий
И для любого набора значений ф-ров в выборке б вып-ся
ỹi=bo+b1xi1+b2xi2+…+bmxim
yi- ỹi=ei
А тогда по методу МНК мы м опр-ть ф-ию Q=∑ei²= ∑(yi-bo-b1xi1-b2xi2-…-bmxim)²
И найти от этой ф-ии част производные по ее парам-м (коэф-там ур-ия).
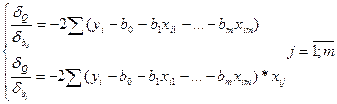
Получаем сис-му из m+1 ур-ия с m+1 неизв-м. Если ее приравнят к 0, то получим сис-му лин ур-ий отн-но коэф-в ур-ия регр-ии, кот-ая всегда б иметь единств решение, т.к. мы м добиться того, чтобы опр-ль сис-мы был ≠0.
Но в тех случаях, когда кол-во объясняющ перем-х m>2, решение таких сис-м нач-т вызывать трудности, поэтому расчет коэф-в делают в матрчно-вект-й форме.
Расчет коэффициентов множественной линейной регрессии.
Предпол-м, что исход выборка предст-на как
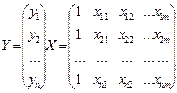
Век-р искомых коэф-в и вектор откл-ий
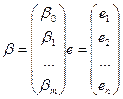
Тогда вел-на Q м.б. запис-на в виде произв-ия 2-х век-ров как 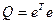
А Ỹ б опр-ся как
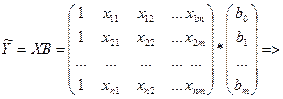
=> е=У-Ỹ
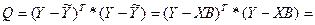
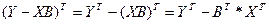 , т.к. транспонирование озн-т, что строки стан-ся столбцами и наоборот. , т.к. транспонирование озн-т, что строки стан-ся столбцами и наоборот.
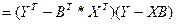
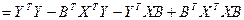
Но т.к. Q –нек-ое число, то каждое из выраж-й здесь также из себя предс-т число.
При трансп-ии матрица сост-ая из 1 эл-та переходит сама в себя.
Воспол-ся этим св-вом и докажем, что 2 и 3 слогаемое в выр-ии совп-т. Для этого транспон-ем любое из них.
2).
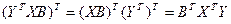
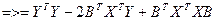
Найдем производную от этого выр-ия по любой из компонент в-ра В.
Распишем в явном виде значение для 2 и 3 выраж-ий, т.кк производ от 1-го слог-го по люб bj=0.
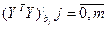
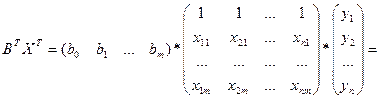
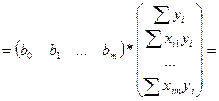
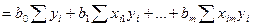
Тогда производ-я по люб из значений bj м.б. предст-на как эл-ты произведения 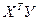 из соответ строки этой матрицы (век-ра-столбца), т.е. из соответ строки этой матрицы (век-ра-столбца), т.е.

Рассм-м теперь последнее из слогаемых, но сначала распишем матрицу

Размер-ть 1-й (m+1)n, 2-й n(m+1)
Размер-ть итоговой (m+1)(m+1)
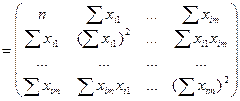
Полученная матрица всегда симметр-на отн-но глав диагонали, т.к. под знаком суммир-я множители м поменять местами.
Б считать, что эл-ми матрицы Z яв-ся Zij, причем, чтобы не запис-ть нулевые строку и столбец, добавленные в выборку.
Z=(Zij) i=1, m+1
j=1, m+1
Б считать, что эл-ты Z имеют индексы:
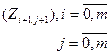 , ,
где индекс 0 соотнес с этой добавленной строкой и столбцом.
Тогда все выраж-ие 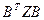 б равно б равно
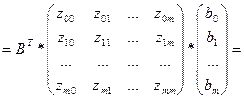
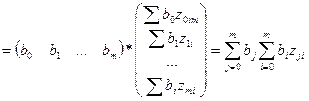
Тогда при вычил-ии производ-й от такого выраж-ия каждая производ-я по bj б встреч-ся дважды: 1-й раз во внеш суммир-ии, 2-й во внутр.
Поэтому производ-й от 3-го слогаемого б рав-на:
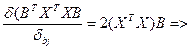
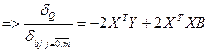
И чтобы найти значи-я для век-ра В, мы д эту производ-ю приравнять к 0.
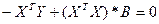
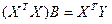
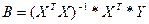 Общее выражение для нахождения коэф-в в ур-ях множест регрессии.
Общее выражение для нахождения коэф-в в ур-ях множест регрессии.
Значения для эл-тов век-ра B при m=1 и m=2получить на практике в общем матричном виде, что позволит понять принцип нахож-ия коэф-в ур-ий с люб кол-вом объясняющ перем-ых.
Но при решении задач с 2 объясняющ перем-ми (m=2) мы б польз-ся преобразован-ми знач-ми, получ-ми из общего вида m=2 в форме:
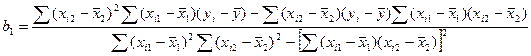
Для b2 получаем симметрично
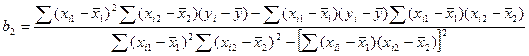
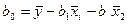
bo – усл-ие прохождения ч/з среднюю точку выборки.
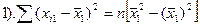
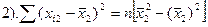
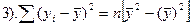
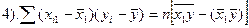
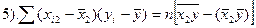
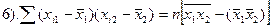
1-3 (дисп-ии откл-ий) не м.б. отрицат. 4-6 (ковариации) м.б. люб
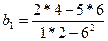
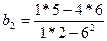
Дисперсии и стандартные ошибки коэффициентов.
Их знание позвол-т анализ-ть точность найденных оценок коэф-в, строить их доверит интер-лы и проверять соответ-ие гипотезы.
Наиболее удобным для такой проверки знач-я дисп-ий и станд откл-ий, запис-й в матр-но-векторной форме.
Если мы запишем вектор теорет откл-ий
,
введем вспомогат век-р I, состоящий из ед-ц
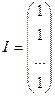 , ,
то мы сможем, используя единич матрицу, записать матрицу ковариаций случ откл-ий в форме:
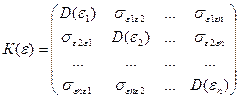
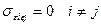
D(εi)=D(εj)=σ²
Исходя из этого К(ε)=σ²Е, где Е- единич матрица.
Усл-ия Гауса-Маркова б выглядеть:
1). Мε)=0
2). D(ε)=σ²I (век-р единич)
3). К(ε)=σ²Е
Рассм-м, когда знач-я для коэф-в с учетом их соотн-ия с теоретич коэф-ми из ур-ия регр-ии.
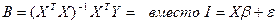
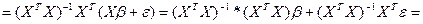
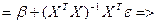
Откл-ие теорет век-ра от расчет
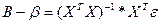
Построим ковариационную матрицу для теорет коэф-в, использую получ-е соот-ие.

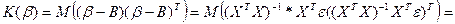
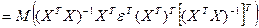
Т.к. матрица 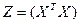 симметр-на относ-но глав диагонали, то обрат к ней матрица тоже симмет-на=> симметр-на относ-но глав диагонали, то обрат к ней матрица тоже симмет-на=>
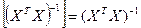
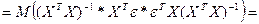
Кроме ε все значения яв-ся const из выборки. Поэтому множ-ли можно вынести из мат ожидания, сохранив порядок умножения.
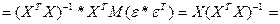
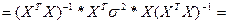
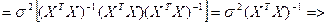
=> для люб знач-ия коэф-та bj мы можем представить единич дисп-ию его вел-ны ч/з выбороч знач-я, зная что оценкой для σ² яв-ся
σ²→So²=∑ei²/n-m-1, а из матрицы обратной мы возьмем соответ-й эл-т с глав диаг-ли матрицы Z.
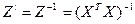
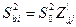
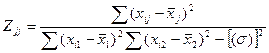
А тогда мы получ-ем возм-ть рассч-ть t-стат-ку.
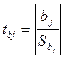
При проверке гипотез отн-но коэф-в ур-ие множ регр-ии также как и для ур-ия парной регр-ии. Отличие состоит в том, что при построении доверит инт-ла отн-но завис-й перем-й у.
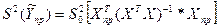 . Для мат ожидания → . Для мат ожидания → 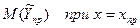
В остальном, выраж-е для доверит интер-в полностью соот-т значению доверит инт-в в ур-ях парной регр-ии.
Анализ качества эмпирических уравнений и множества линейных регрессий.
Построение эмпир ур-ия яв-ся начальным этапом эмпир анализа. 1-ое построенное Ур-ие по имеющейся выборке оч редко яв-ся удовл-м по всем хар-м. Поэтому след важнейшая задача – проверка кач-ва ур-ия.
В экономет-ке принята устоявшаяся схема такого анализа. Она провод-ся по след напр-ям:
1).
Проверка стат знач-ти коэф-в рассматр-го ур-ия регр-ии.
2).
Проверка общего кач-ва ур-ия.
3).
Проверка св-в данных, выполнимость кот-ых предназначалась при оценивании ур-ий, т.е. это проверка усл-ий Гауса-Маркова.
1). Проверка стат знач-ти коэф-в рассматр-го ур-ия регр-ии.
Как и в парных ур-иях, эта проверка дел-ся на основе t-статистик.
Т.е. рассч-ся tbj=|bj/Sbj|.
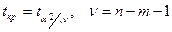
И если |tbj|>tкр, то коэф-т сч-ся значимым.
Если |tbj|<tкр, коэф-т не значим, т.е. он стат-ки близок к нулю. Это значит, что фактор xj прак-ки не связан линейно с завис переменной.
Его присут-ие в ур-ии неоправданно со стат т.зр., и он м лишь искажать реальн картину взаимосвязей. Поэтому рекоменд-ся такие ф=ры из ур-ия исключать.
Зачастую, строгую проверку м не делать. Достаточно и грубой оценки.
|tbj|≤1 – не значим
1<|tbj|≤2 – слабо значим
2<|tbj|≤3 значим
3<|tbj| - сильно значим.
Коэф-т искл-т, если |tbj|≤1
2). Проверка общего кач-ва ур-ия.
Для этого, как и в парной регр-ии, исп-ся F стат-ки.

Fкр=Fα1,υ1,υ
υ1=mυ2=n-m-1
И также, как в t стат-ке, если Fрасч>Fкр, то ур-ие сч-ся значимым.
Как б показано, 0<R²<1.
Но для того, чтобы соотнести ур-нь детермин-ии с каждым из объясн-их ф-ров, его коррет-т на число степеней свободы в исходной выборке. Вводят скоррек-й коэф-т
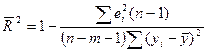
Т.е. в знаменателе записана несмещенная оценка общей дисп-ии независ-й перемен-й. А в числ-ле мы расс-м вел-ну, соответ-ую So²=∑ei²/(n-m-1).
В этом случае соот-ие м.б. предст-но ч/з исходное значение коэф-та детерминации:
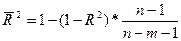
Обычно привод-ся данные как для одного, так и для др коэф-та детерм-ии. Но абсолютизировать эти пок-ли нельзя.
Сущ-т мно-во вар-тов, когда при высоком знач-ии R² (R²→1), не б вып-ся усл-ий Гаусса-Маркова, и ур-ие окаж-ся низкого кач-ва.
Анализ статистической значимости коэффициента детерминации.
Он провер-ся по Fтат-ке. Проверка соот-т гипотезе Ho:β1=β2-…βm=0.
Если Fрасч≤Fкр, то десается вывод, что совокуп влияние всех объясн-х переем-х, исп-х в модели, не зависимую пере-ю стат-ки не значит. У ур-ия низкое кач-во.
Если же гипотеза откл-ся (Fр>Fкр), то объясненная дисп-ия разброса завис-ой переем-й соизмерима с дисп-ей, вызванной случ откл-ми. Очевидно, что R и R²=0 или ≠0 одновр-но. А это значит, что по МНК наилуч-я линяя регр-ии ỹ=yср, а => у лин не зависит от объясн-их переем-х.
В случаях парной регр-ии, проверка нулевой гипотезы для R² равносильна проверке на стат значимость t стат-к из соотношения

т.к. m=1, ar²=(rxy)²
Проверка равенства 2-х коэффициентов детерминации.
Основана на исп-ии стат-ки Фишера для проверки необх-ти включения или искл-ия в ур-ии множест регр-ии доп объян-их переем-х.
Предположим, что изнач-но построено ур-ие, содерж-ее m объясн-их переем-х:
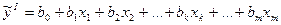
и для него вычислим коэф-т детерм-ии R²I. Исключим из исх-ой выборки все объясняющ переем-ые, имеющие номер > чем к. Тогда, по ост выборке мы м построить др ур-ие регр-ии:
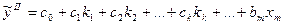
ŷ и для него опр-м R²II. Всегда R²II≤R²I, т.к. включ в модель кажд доп пере-й объясн-т еще какую-то долю ее разброса отн-но ур-ия регр-ии. Тогда нас интер-т на сколько кач-во одного ур-ия отлич-ся от кач-ва др ур-ия.
Поэтому гипотеза Но состоит в том, что коэф-ты детер-ии совпадают (кач-во одинаковое), а с ней конкур-т Н1.
R²I= R²II – кач различно.
В соответ-ии с ними рассч-ся R²стат:
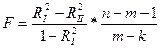
, где m-k – кол-во исключ объясн-х переем-х.
Если Fрасч≤Fкр, то кач-во ур-ий приблизит одинаково, значит переем-ые исключ-ны правильно.
Если F расч>Fкр, кач-во ур-ий сущ-но разл-но, и мы не д.б.исключать эти переем-ые.
Замечание:
обычно на практике не искл-ся одновр-но несколько объясн-х переем-ых. Их берут по одному и каждый раз сч-т F стат по соотн-ю:
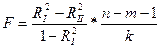
, где k – кол-во исключ объясн-х переем-х. Как правило k =1.
При этом м искл-ть не последующие объясн переем-е, а любую, начиная с тех, у кот-ых mint стат.
Таким же образом м идти проверка целесообр-ти включения доп объясн-х переем-х в исход модель.
Допустим, что это б модель I, и мы к ней добавили Р объясн-х переем-х.
Расч-ли 3-ю модель:
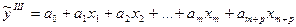
и у него коэф-т детерм-ии R²III.
Тогда сч-т Fстат= (R²III-R²I)/(1-R²III) * [n-(m+p)]/p и ее проверяют по F кр Фишера.
Проверка гипотезы о совпадении уравнений 2-х различных выборок.
Это еще одно напр-ие исп-ия F-стат Фишера. Такая проверка дел-ся тестом Чоу, кот-ый сост-т в:
Пусть имеется 2 выборки объема n1 и n2. У каждой постоено свое ур-ие регр-ии
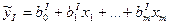 для n1 для n1
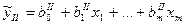 для т2. для т2.
И мы хотим проверить отл-ие 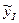 и и 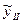
Тогда: 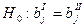
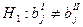
Предположим, что мы рассч-ли ∑ квадратов откл-ий для этих ур-ий
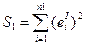

Потом по объед-й выборке (n1+n2) построим ур-ие регр-ии.
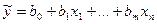 и для него также вычислим и для него также вычислим
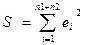 и затем считаем Fстат, сравнивающую эти суммы квадратов откл-ий. и затем считаем Fстат, сравнивающую эти суммы квадратов откл-ий.
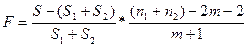 . Тогда Fкр=Fα. υ1=m+1 υ2=(n1+n2)-2m-2. Потому что для S мы имеем (n1+n2)-m-1 степеней свободы. . Тогда Fкр=Fα. υ1=m+1 υ2=(n1+n2)-2m-2. Потому что для S мы имеем (n1+n2)-m-1 степеней свободы.
Для + 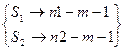 степеней свободы степеней свободы
= (n1+n2-2m-2).
Тогда, если Fрасч<Fкр, то мы м утвер-ть, что эти ур-ия имеют одинак ур-нь кач-ва, Но не откл-ся.
И мы м исп-ть любое из ур-ий, рассч-х по этим выборкам, т.е. выборки м.б. объединять.
Такую проверку приход-ся делать при построении дин рядов. Предположим, мы строим ур-ие парной регр-ии объмов продаж. min авто с to до t2. При этом знаем, что в t1 изменены пошлины, те.е. изм-сь институц среда.
За (to до t1) есть выборка n1 и ур-ие .
За (t1; t2) выборка n2 и ур-ие 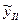
А потом по объед выборке строим обязат ур-ие ỹ
График.
Если Но не откл-ся, то мы реально м строить ỹ по сов-й выборке без учета институц изм-ий и исп-ть его для прогноза на ((t2-to)/3)
Проверка выполнимости предпосылок МНК.
Проверка на отсут-ие а/коррел остатков (ста-ка DW)
Стат знач-ть коэф-в ур-ия регр-ии и близость ед-цы к-та детерм-ии еще не гаран-т выс кач-во построенного ур-ия, т.к. м не вып-ся какие-то из предпосылок Гауса-Маркова.
Одной из таких предпос-к яв-ся незав-ть случ откл-ий др от др, что гаран-ся усл-ем
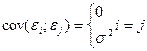
Послед-ая коррел-я откл-ий наз-ся а/коррел и показ-т, что если построена упорядоч-я по вр-ни (или номерами выборки) послед-ть откл-ий, то это озн-т, что или в выборке испол-ны перекрест знач-я или задан времен-й ряд, в кот-м послед-ие вел-ны генерир-ся предыд-ми. Поэтому в выкладках м исп-ся обозначеия
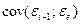 , т.е. откл-ия соседние по вр-ни. , т.е. откл-ия соседние по вр-ни.
В эк задачах как правило встреч-ся положит а/коррел 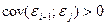 и очень редко возм-на отрицат. и очень редко возм-на отрицат.
В больш-ве случаев это связано с тем, что в модели отсут-т нек-ый ф-р, кот-ый возд-т на объясн-ую переем-ую в постоян напр-ии.
Сущность а/коррел
м объяснить на след примере.
Предпол-м иссл-ся спрос У на прохлад напитки в зав-ти от дохода Х для домохоз-ва по среднемес данным. Предпол-м, что трендовая зав-ть, построен-я по этой выборке в виде ур-ия парной регр-ии.
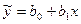 б опис-ся нек-ой линией б опис-ся нек-ой линией
График.
Но реал потреб-ие прохлад напитков безусл-но зависит от вр-ни года. Т.е. фактич-е т выборки в зав-ти от сезона года б нах-ся или все выше или все ниже линии.
Аналог картина набл-ся в макре по циклам деловой акт-ти.
Положит а/коррел озн-т, что в бол-ве случаев за положит откл-ми след-т полож, а за отриц отриц-ые, что и озн-т однонапр-ую связь м/у откл-ми – ковариация полож-на.
Среди осн-ых причин, вызыв-х наличие а/коррел
обычно выд-т:
1). Ошибки специф-ии модели
, т.е. не учет в модели какой-то важной объясн-й переем-й или неправ-й выбор формы зав-ти.
2).
Инерция в изм-ие эк пок-лей
. Многие эк пок-ли (инф-ия, безр-ца, объем ВНП) облад-т опр-й циклич-тью, связ-й с волнообр-тью.
Нап-р эк подъем приводит к росту занят-ти, сокр инф-ии, ↑ ВНП. Он продол-ся до тех пор, пока изм-ия конъюнктуры рынка и ряда др эк хар-к рынка не приведут к замедл-ию роста, затем его ост-ке и дальней-му снижению пок-лей. Но в люб случае эта трансфо-ия осущ-ся замедл-но и облад-т опр-й инерцией.
3). Эффект паутины.
Во многих эк процессах и в пр-ве пок-ли реаг-т на изм-ие эк усл-ий с временным лабом.
Нап-р: предл-ие с/х прод-ии реаг-т на изм-ие цены на нее с запазд-ем = периоду до получения нов урожая.
Большая цена в прошлом году вызовет рост про-ва в этом году. Скорее всего произ-т ее перепро-во => цена ↓, в след году б исп-ны под зерновые < площадей => цена ↑ и т.д. пока не уст-ся равновесие.
4). Сглаживание данных
. Общеизв-но, что врем тренды стр-ся на основе сглаж-ия данных по врем рядам.
=> каждая след-ая средняя в нашем вар-те входить 2 предидущ знач-ия, т.е. ср зав=т др от др. И это служит причиной наличия положит а/коррел у врем рядов.
Последствия и способы обнаружения автокорреляции. Графический метод.
Если регресс-я модель рассч-сь по МНК, то
1). Оценки пар-ров ур-ия оставаясь несмещ-ми отн-но среднего перестают быть эф-ми, т.е. наилучшими из всех возм-х.
2). Дисп-ии этих оценок вычисл-ые по станд формулам б смещенными в сто-ну убывания, что повлечет за собой увелич-е t-статистик.
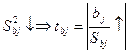
что м привести к признанию стат-ки знач-ми (tbj>tкр) тех переем-х в ур-ии, кот-ые такими не яв-ся.
3). Вел-на So²=∑ei²/(n-m-1) также окаж-ся смещенной отн-но теоретич дисп-ии откл-ий σ², а поэтому применение t и F статистик окаж-ся необоснов-м, б получены неправ-е выводы по модели и ухуд-ся ее прогозные кач-ва.
Чтобы обнаружить а/коррел исп-т неск0ко методов.
Графический метод.
В этом случае стр-ся графики, связыв-ие номер выбора выборочной компоненты или время, для кот-го взята переем-я и соответ-ие знач-ия для откл-ий, получ-х исходя из рассчит-го ур-ия регр-ии.
4 графика.
На первых 3-х графиках изобр-на нек-ая зав-ть вел-ны откл-ия от № выборочной пары. М предпол-ть, что в модели присут-т а/коррел остатков. На 4 графке такой зав-ти нет, поэтому мы м предпол-ть отсут-ие а/коррк. Причем сч-ся, что ≈ 10% точек м.б. неподчинены осн зав-ти и а/коррел отсут-т.
Метод Дарбина-Уотсона.
По нему рассч-ся к-т а/коррел остатков первого пор-ка, кот-ый совп-т со знач-м коэф-та выбороч-й коррел
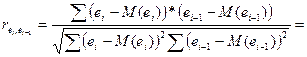
Но мы знаем, что мат ожидания (ср знач) откл-ий =0 в методе МНК => получили
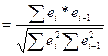
Но на практике для такого анализа исп-т стат-ку DW, для кот-й сущ-т расчет-е таблицы
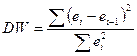
Покажем, что эти вел-ны дейст-но совп-т. Для этого преобр-м числ-ть
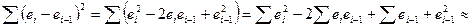
Последняя ∑ отл-ся от первой на 1 слогаемое. А т.к. знач-е ei невелики, то мы м предпол-ть, что они м/у собой совп-т. Тогда
≈2∑ei² -2∑eiei-1
Тогда
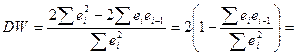
А т.к. мы предпол-ли, что ∑ei² ≈∑ei-1², то
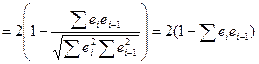
=> ста-ка DW б вести аналог-но поведению выбор коэф-та коррел м/у откл-ми.
Если r eiei-1 =1, DW=0
r eiei-1 =0, DW=2
r eiei-1 =-1, DW=4
Т.е. все знач-я этой стат-ки нах-ся в инт-ле (0;4) при 2 а/коррел остатков отсут-т. И вопрос закл-ся в том, насколько м эта стат-ка откл-ся от 2, чтобы мы м утвер-ть, что а/коррел отсут-т.
Таблицы DW построены с.о., что в соот-ии с заданным n выбир-ся опр-ая таблица, входами в кот-ую яв-ся m-число объясняющих переем-х и n- объем выборки
Таблица
Предпол-м n=k и в модели исп-ны m=2. Тогда из таблицы б найдены 2 числа dl и du, dl<du<2. Мы сможем отложить на шкале их значения.
В зав-ти от того, куда попадет значение DW, мы м делать выводы о наличие или отсут-ии а/коррел остатков в модели. Но т.к. по этому методу мы ничего не м сказать окончат-но при попадании в зоны неопр-ти.
Метод рядов.
Основан на учете чередования знаков у отклонений ei. Для этого поступают с.о. Нап-р для нашей задачи, рассч-й для парной регр-ии, выставим посл-ть знаков по откл-ию.
(--)(++)(--)(+++)(-)(++) n=12
Затем объед-ся инт-лы совпадающих знаков. Каждая из образ-ых послед-тей наз-ся рядов (ряд одинак знаков). В нашей задаче к=6. Кол-во одинак знакв в отдел-м ряду наз-ся длиной ряда. Если рядов сущ-но мало по отн-ию к объему выборки n, то вер-на положит а/коррел, а если их много, то возм-на отрицат а/коррел.
Для более детального анализа поступ-т с.о. Пусть n – объем выборки. n1 – кол-во положит знаков. n2 – отрицат. В нашем случае n1=7 n2=5.
При достаточно большом кол-ве наблюдений n>20, мы м посчитать мат ожидание кол-ва рядов знаков.
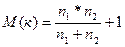 и дис-ию разброса этого кол-ва рядов и дис-ию разброса этого кол-ва рядов
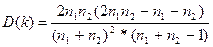
Тогда, если принять, что мат ожидание м оценить ч/з таблицы распред-ия кол-ва рядов, кот-ое д нах-ся в инт-ле  , то при попадании в этот инт-л а/коррел остатков б отсут-ть. В противном случае, если , то при попадании в этот инт-л а/коррел остатков б отсут-ть. В противном случае, если 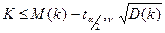 , то у нас положит а/коррел, а если k≥ - отрицат. Для такого распред-я б построены таблицы Экхарда, в соот-ии с кот-ми м опр-ть нижнюю и верхнюю гр-цу числа К. К1<K<K2 по 2 входам +n1 и –n2. , то у нас положит а/коррел, а если k≥ - отрицат. Для такого распред-я б построены таблицы Экхарда, в соот-ии с кот-ми м опр-ть нижнюю и верхнюю гр-цу числа К. К1<K<K2 по 2 входам +n1 и –n2.
Таблицы имеют стр-ру
Нижняя граница К1
Таблица имеет своб поля. Если попадаем в своб поле, то к1 выбираем наименьший в этой строке.
Верхняя гр-ца К2.
Выбор осущ-ся также как для К1 и знач-я берутся для своб полей также как и в 1 случае.
В отл-ии от критерия DW этот метод дает однознач ответ, причем н помнить, что метод DW не применим для регресс моделей, содерж-х в кач-ве объясн-х переем-х нек-ые лаговые объясн вел-ны. Даже если этот лаг имеет 1 пер-д. Нап-р в модели 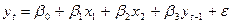 . Для таких моделей исп-ся спец n-стат-ка Дарбина, по кот-й . Для таких моделей исп-ся спец n-стат-ка Дарбина, по кот-й 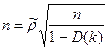 , где , где 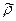 - вычис-ся из стат-ки DW. Обычно ее принимают =1-1/2DW, т.к. - вычис-ся из стат-ки DW. Обычно ее принимают =1-1/2DW, т.к.  . .
обычно при-т равной квадрату станд-й ошибки коэф-та при лаговой переменной. В нашем примере 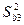 . .
Методы устранений автокорреляции.
Изв-но, что осн причиной наличия в ур-ие регр-ии случ откл-ия яв-ся не учет всех объясняющ перем-х в модели и ошибки в выборе зав-ти.
Поэтому устранять а/коррел нач-т с того, что пробуют ввести в модель еще какую-то сущест (значимую) объясняющ переем-ую. Если это не помогает, то пытаются исходя из теоретич знаний изм-ть форму зав-ти в модели.
Но если все разумные приемы совершенст-я модели исчерпаны, а а/коррел все-таки сохр-ся, то м предпол-ть, что она связана с какими-то внутр св-вами переем-й.
Тогда в моделях прибегают к а/регрессионным преобр-м, суть кот-ых закл-ся в след-ем.
А/регр преобр-е 1 пор-ка получ-т с.о. Запис-т теорет модель для нек-го года t
yt=βo+β1xt+εt
Тогда для предыдущего года она б иметь вид
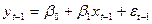
Вычтем из 1 ур-ия 2.
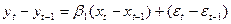
В этом случае мы получаем модель, построенную на приращенных переем-х в году t.
Δyt=β1Δxt+Ut, где Ut – случ вел-на = εt – εt-1
Для таких моделей исход выборка сокр-ся на 1 и если n-1>3m+1, то мы м построить новую модель включающую в себя своб член bo, кот-ый б гаран-ть прохождение ч/з ср точку нов выборки.
Δỹt=bo+b1Δxt+Ut
Δỹt*=bo+b1Δxt*+Ut
В такой модели а/коррел остаткв уже наверняка б отсут-ть. Если же объем выборки не позвол-т уменьшить ее на 1, то прибегают к вспом преобр-ям исх-х переем-х с исп-ем стат-ки DW.
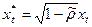
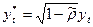
В этих случаях также а/крел из модели б.устран-ся.
Кроме метода разности прим-ся еще неск-ко методов. Нап-р когда в кач-ве нов переем-й вводятся неполн полусуммы значений переем-х по выборке, а только их половинные вел-ны.
yt*= (yt + yt-1)/2
xt*= (xt + xt-1)/2
Метод исп-ия сглаж по люб кол-ву интервалов изм переем-ых. Но все-таки прежде чем исп-ть эти вспом методы, необ-мо сначала попроб-ть изм-ть специф-иб модели.
Мультиколлиниарность.
Если объясняющ переем-ые связаны строгой лин зав-тью, то гов-т, что м/у ними сущ-т соверш мульт-ть. На практике м столконуться не с соверш, а с сильной мульт-тью, т.е. когда ур-нь коррелир-ти м/у объясняющ-ми переем-ми >0,7.
|rxkxj|>037

0≤|rxkxj|≤1
Мульт-ть яв-ся проблемой для ур-ий множест регр-ии. Покажем как она прояв-ся в ур-ии множест регр-ии при m=2 и при усл-ии, что м/у х2 и х1 сущ-т строгая лин зав-ть.
х2=γo+γ1x1
Тогда ỹ=βo+β1x1+β2x2+ε
ỹ=βo+β1x1+β2(γo+γ1x1)+ε = (βo+β2γo)+ (β1+β2γ1)x1+ε =
Обозначим выр-ия, чтоящие в скобках за АО и а1 =АО+а1х1+ε
Получили ур-ие парной регр-ии, в соот-ии с кот-м, используя метод МНК, найдем значения для оценок а0 и а1. Но от этих оценок мы не сможем перейти к оценкам коэф-в исх ур-ия βo β1 β2, т.к. получили для их опр-ия всего 2 ур-ия.
{аО= βo+β2γo
{а1= β1+β2γ1
γo и γ1 нам изв-ны.
Т.о. соверш муль-ть не позвол-т однозначно опр-ть коэф-ты в ур-ии множест регр-ии, т.к. таких коэф-в всегда б на 1 >, чем ур-ий => не сможем сделать выводы о знач-ти этих коэф-в и не сможем опр-ть какой вклад дает каждая из объясн-х перем-х в поведение завис перем-й.
Но соверш мульт-ть бывает только на теории, на практике обычно возм-на сильная мульт-ть. В этом случае зав-ть наз-ся несоверш мульт-ть.
Графически это сост-ие м проиллюстр-ть с.о.:
4 графика:
1) Муль-ть отсут-т. Каждая из объясн-х перем-х оказ-т изолир-е влияние на у. 2) и 3) м/у х1 и х2 сущ-т зав-ть, кот-ую м изм-ть ч/з коэф-т выбороч коррел rх1х2.
Тогда 1) |rx1x2|<0,3
2) 0,3≤|rx1x2|≤0,7 – м/у объясн-ми перем-ми возм-на несоверш мульт-ть.
3). |rx1x2|>0,7 – м/у перем-ми сущ-т несоверш мульт-ть.
Посл-ия
наличия мульт-ти:
1).
Большие вел-ны дисп-ии оценок, а => станд ошибок коэф-в. Это расшир-т инт-лы для коэф-в ур-ий и м повлиять на правильность вывода о стат знач-ти коэф-та.
2).
Т.к. ↓ t стат-ка, то мы м неверно опр-ть стат знач-ть объян-их перем-х и не взять в модель ту из них, кот-ая дейст-но опр-т поведение завис перем-й. Кроме того коэф-ты ур-ия стан-ся очень чувствит-ми к любым изм-ям в выборке.
3).
Возм-но получение неверного знака и коэф-та уравнения.
Определения мультиколлиниарности.
Сущ-т неск-ко методов, по кот-м м.б. уст-но наличие в модели мульт-ти переем-х. Косвенными признаками ее наличия м.б:
1).
К детерм R² высок, но нек-ые из коэф-тов регр-ии стат не значимы, т.е. имеют низкие t стат-ки.
2).
Парная коррел-я м/у объясняющ перем-ми rxixj дост-но высока. Этот признак б надеж-м только в случае 2-х объясн-х переем-х. При их > кол-ве более целесообр-но испол-ие частн коэф-в коррел-ии.
3).
Част к-ты коррел высоки. Они опр-т силу лин зав-ти м/у любыми 2 перем-ми без учета влияния на них др переем-х.
Измер-е силы такой лин зав-ти, когда rxy очищен от влияния всех ост-х переем-х наз-т част коэф-м коррел.
Нап-р, в случае ур-ия множест регр-ии с 3 объясняющ переем-ми, мы м рассчитать коэф-т част коррел м/у переем-ми х1 и х2 без учета влияния 3 перем-ой. Такой коэф-т обознач-ся
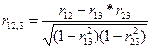
Из этого соотн-ия уже м сделать вывод, что коэф-т част коррел сущ-но отл-ся от коэф-та парной коррел-ии r12.
В общем случае коэф-т част коррел м/у объясн-ми переем-ми xi и xj при усл-ии, что i<j обознач-т 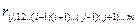 . .
Приведем без док-ва формулу для расчета люб к-та част коррел в модели, содерж-й m-объясн-х переем-х.
Для этого запишем матрицу парных коэф-в коррел
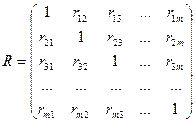
Причем эта матрица симмет-на, т.к. rij=rji.
Затем к этой матрице состав-т обратную матрицу
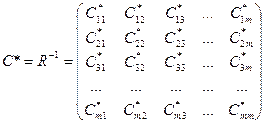 , ,
кот-ая также симмет-на отн-но гл диагонали.
Тогда к-т 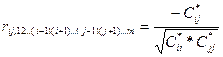
И в этом случае квадрат такого к-та б опр-ть част коэф=т детерм-ии, кот-ый опр-т % изм-ия i переменной в след-ии влияния на нее перем-й с №j, что позвол-т при усл-ии, что мы 1-й № зафиксир-ли за завис-й перем-й, а 2-1 соотнесли с х1, а 3-й с х2, выяснить влияние только одной из этих перем-х на завис-ю перем-ю без учета влияния др перем-й.
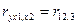
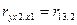
Тогда коэф-т част детерм-и  , а , а 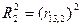
4). Сильная вспомогат (доп) регр-ия.
Мульт-ть м.б. рез-том того, что какая-либо из объясн-х перем-х яв-ся лин комб-ей др объясн-х перем-х.
Чтобы это выяснить для каждой из объясн-х перем-х стр-ся ур-ия регр-ии этой перем-й отн-но ост-х перем-ых.
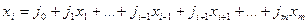
Ур-ие множест регр-ии m-1 объяс-й перем-й.
Для такого ур-ия 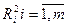 вычисл-т f-стат-ку как вычисл-т f-стат-ку как
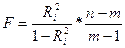
И если оказ-ся, что F стат-ка Fр≤Fкр, то мы говорим, что R² незначим, лин зав-ти xi от ост-х объясн-х переем-х нет, муль-ть отсут-т.
Если Fр>Fкр, то мы откл-ем гипотезу об отсут-ии такой зав-ти, гов-им, что она присут-т в модели => имеет место мульт-ть.
Методы устранения мультиколлиниарности.
Прежде чем рассм-ть эти методы, необ-мо отметить, что в нек-ых случаях мульт-ть не яв-ся таким серьез препятствием для исп-ия модели, чтобы прилагать усилия к ее опр-ию и устранению.
Если осн задача моделир-ия сост-т в прогнози-ии буд знач-ий завис переем-й, то при дост-но больших вел-нах к-та детерм-ии (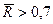 или R²≥0,9) мульт-ть никак не скаж-ся на кач-ве прогноза. или R²≥0,9) мульт-ть никак не скаж-ся на кач-ве прогноза.
Если же целью иссл-ия яв-ся выявл-ие каждой из объясн-х перем-ых на завис перем-ую мульт-ть не позволит этого сделать, т.к. она искозит t стат-ки, т.е. стан-ся серьез проблемой.
Единого метода устранения мульт-ти в модели не сущ-т. Это связано с тем, что причины наличия мульт-ти неоднозначны. В многих случаях она зав-т от имеющ-ся выборки.
Рас-м наиболее часто применяемые методы устранения мульт-ти объясн-х переем-х в моделях множ лин регр-ии.
1). Исключение перем-й из модели.
Наиболее простой метод, когда из модели искл-ся 1 или неско-ко переем-х, но при его прим-ии необ-ма остор-ть, т.к. возм-ны ошибки специф-ии.
Нап-р: мы строим модель спроса на какое-то благо, выбирая в кач-ве объясн-х перем-х его цену и цены товаров-заменит. Эти цены часто коррел-т др с др. Но если из модели искл-т цену заменит-ля, то мы скорее всего допустим ошибку специф-ии, получим смещен оценки и сделанные выводы окаж-ся неверн.
Поэтому в приклад-х эконометр-х иссл-х желат-но не искл-ть объяс-е перем-е до тех пор пока их коллин-ть не станет серьез-й проблемой. В част-ти в рассмот-й модели, если необ-м прогноз объема реал-ии искл-ть цену замен-ля нельзя, но если хотим оценить при каком соотн-ии цен на благо и его замен-ли спрос б наибол-м, необ-мо макс-но снижать ур-нь зав-ти м/у этими объясн-ми перем-ми.
2). Получение доп данных или нов выборки.
Т.к. мульт-ть непоср-но зависит от выборки, то возм-но что при изм-ии выборки она перестанет быть серьез пробл-й. Иногда для этого дост-но ↑ объем выборки или сокр-ть вел-ну периодич-ти набл-ий, т.е. от погодовой выборки перейти к покварт или помесяч, иногда ежеднев.
Но получение нов выборки или расшир-е старой возм-но не всегда или связано с большими матер затратами.
Кроме того такой подход, устранив мульт-ть, с вызвать наличие в модели а/коррел-ю остатков, что огран-т возм-ть применения этого метода.
3). Изм-ие специф-ии модели.
Когда или меняется форма зав-ти или добавл-ся объясн перем-е не учтенные в превонач модели, но при этом они д оказать сущест влияние на объясн-ю перем-ю, т.е. если Хк – доп перем-я, то |ryxk|≥0,3. Испол-ие такого метода приводит к уменьшению ∑ квадратов откл-ий в модели ∑ei² ↓, тем самым сокр-ся станд откл-ия к-та Sbi и как след-ие возраст-т стат знач-ть этих к-тов и растет R².
4). Испол-ие предвар инф-ии о нек-ых парам-х модели.
Речь идет о том, что при построении модели множест регр-ии исходя из уже испол-ия моделях парной регр-ии ỹ=bo+b1x1, когда b1=0,82, мы добав-м в модель объян-ю перем-ю х2, кот-ая м.б. корред-на с объясн-й перем-ой х1. Теоретич ур-ие регр-ии с 2 объясн-ми перем-ми сразу запишем в форме y=βo+0,82x1+β2x2+ε
В этом случае ур-ие факт-ки б яв-ся ур-ем парной регр-ии, для кот-го проблемы мульт-ти не сущ-т. Огранич-ть испол-ия этого метода обусл-на тем, что:
1. зачастую затруднено получение достовер предварит инф-ии.
2. Вер-ть того, что принятый изв-й коэф-т б одним и тем же в разн моделях не высок
5). Преобразование переем-х.
Этот метод в нек-ых случаях позвол-т полностью устр-ть мульт-ть. Предпол-м, что по имеющ-ся выборке мы рассч-ли эмпир ур-ие регр-ии ỹ=bo+b1x1+b2x2 и выяснили, что х1 и х2 коррел-ны м/у собой.
В этой ситуации м опр-ть регул-ие зав-ти отн-но каждой из этих переем-ых в отдел-ти, используя в кач-ве нов выборки не абсолют вел-ны перем-х, а их отн-ия. Тогда исход выборку (xi1, xi2, yi) i=1;n, мы делим или на правую или на 2 из объясн-х перем-х.
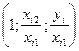 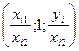
Тогда в соот-ии с этими выборками мы сможем построить или ур-ие 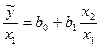 или или 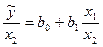
Вполне вер-но, что в такой модели мульт-ть уже б отсут-ть.
Гетероскедастичность
Нарушение предпосылки о том, что в модели отсут-т связь м/у случ откл-ми и объян-ой переем-й.
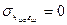
Возн-т вопрос о киках дисперсиях Д(εi) Д(εj) идет речь. Дело в том, что задача реш-ся по конкр-й выборке сформул-й на основе генер-й сов-ти и м/у знач-ми вошедшими в выборку м нах-ся любое кол-во эл-тов и ген сов-ти.
Предпол-м, что на основе выборки б построено ур-ие регр-ии.
График
Тогда отн-но т пересечения линии регр-ии с прямой x=xii=1;n. Для точек, лежащих м/у xi и xi+1 в каждом из подинт-в разбиения в свою очередь м.б. расч-на дисп-ия разброса откл-ий этих точек от линии регр-ии.
Именно о таких дисп-ях, а не о дисп-ях самих откл-ий в модели идет речь в усл-ях
Гаусса-Маркова, что все норм распред-ия в промежутках д.б. одинаковы.
Если это требование не вып-ся, то т.к. в кач-ве оценки для σ² по выборке So²=∑ei²/(n-m-1), то возн-т необ-ть проверить сущ-т ли связь м/у отд-ми знач-ми ei и xi хотя бы в нашей выборке.
Естест-но если она есть, то норм распр-ие при переходе от одной т. Выборки к др б менять свое пведение.
Если же этот эф-т отсут-т, то мы м предпол-ть с нек-м ур-нем достовер-ти, что он отсут-л и в генер сов-ти. То же самое касается мат ожидания конкр значения М(εi)=0.
Обнаружение гетероскедастичности. Графический метод.
В нек-ых практич ситуациях зная хар-р данных, появление проблемы гетероск-ти м предвидеть заранее и попытаться устранить эту причину заранее, но чаще ее прих-ся решать уже после постр-я ур-ия регр-ии.
Обнаружение гетероск-ти яв-ся сложной задачей, т.к. для расчета дисп-ии откл-ий по ур-ию σ²(ei) необ-мо знать распред-ие случ вел-ны У при опр-м значении xi.
Как правило в выборке встреч-ся min эл-тов, в кот-ых одному значению объяс-й переем-й соот-т неп-ое мно-во значений У.
А поэтому мы не м оценить как ведет себя эта случ вел-на, т.к. в табл конкр-му знач-ю xi соот-т единст или 2, а max 3 знач-я для yi. А поэтому мы не м выбрать единств метод.
Графический метод.
Обычно исп-ся для ур-ий парной регр-ии. Когда стр-ся графики квадратов откл-ий по соответ-их им знач-ям объясн-й переем-й.
5 графиков
В этом случае, если кол-во т имеющих откл-ие или не вошедших в общую закономер-ть не превышает 10% объемов выборки, то мы м сделать дост-но достовер выводы.
На 1 графике все квадраты откл-ий не зав-т от знач-ия xi, т.к. нах-ся в 1 и том же диапазоне. Мы м сказать, что у парной регр-ии в этом случае гетер-ть отсут-т.
На всех ост-х графиках прослеж-ся зав-ть вел-ны квадрата откл-ия от вел-ны объясн-ся переем-й.
На 2 и 3 – это прямая зав-ть. На 4 они сначала возр-т, потом убыв-т с какого-то знач-ия х. На 5 они убыв-т с ростом xi.
Т.е. сущ-т какая-то зав-ть, поэтому м сделать предпол-е, что гетер-ть остатков в модели присут-т.
Но как правило граф метод сопровож-т др специф-ми методами обнаруж-я гетероск-ти.
Тест ранговой корреляции Спирмена.
Зав-ть м/у откл-ем ei и переем-й xi опр-ся на основе t стат-ки отн-но коэф-та выбор-й коррел-ии.
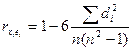
, где di – разность номеров мест, кот-ые зан-т I значения объясн переем-й и откл-ия из одной и той же выборочной пары при ранжировании этих пок-лей по возраст-ю.
Тогда расч-ся t стат-ка.
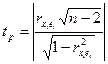
И если оказ-ся по грубой оценке, что tр≤1, мы м наверняка не используя табл Стьюдента утвер-ть, что коэф-т выбор коррел-ии не значим, гетер-ть остатков в модели отсут-т.
При люб др знач-х необ-мо срав-ть расчет знач-е с критич.
tкр= tα/2, υ
И если tp<tкр, то гетер-ть отсут-т. В против случае она присут-т в модели.
Тест Парка.
Он предпол-л опр-ть гетер-ть на основе срав-ия знач-ия σ²(ei), где i- любое с нек-ой функц зав-тью
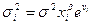
, где vi – вел-ны откл-ий для данной нелин зав-ти, кот-ая м.б. сведена к линейной методом логарифмирования.
lnσ²i= lnσ²+βlnxi+Vi.
И если мы обозначим соответ-ие знач-ия за нек-ые вел-ны, то получим лин модель.
Zi=αo+βxi* +Vi, кот-ую м оценить методом МНК, если вместо σ²i взять вел-ны ei², а xi* найти прологарифмировав исх-цю выборку zi=lnei².
Если окаж-ся, что коэф-т при переем-ой xi* значим, то связь м/у объясн-й переем-й и квадратами откл-ий сущ-т, а => в модели присут-т гетер-ть остатков. Сущ-т еще неск-ко тестов, являющ-ся разновид-тью теста Парка.
Тест Голдфельда-Квандта.
Все набл-ия в выборке упорядоч-ся отн-но вел-ны объяс-й переем-й xi.
Затем выборка разбив-ся на 3 необяз-но равные части k, n-2k, k, но так, чтобы 3m+1≤k≤n/3 и отдельно оцен-ся ур-ие регр-ии для 1 и 3 части выборки, для кот-ых затем оцен-ся ∑ квадратов откл-ия
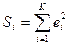 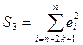
и стр-ся Fстат-ка для вел-ны
F= (S3/k-m-1)/(S1/k-m-1)= S3/S1.
Нах-ся Fкр=Fα, υ1=υ2=k-m-1 и если Fр>Fкр, то гетер-ть в модели присут-т. В против-м случае она отсут-т.
Замечание:
Если при расчетах оказ-сь, что S1>S3, то стр-ся обрат вел-на, т.к. в этом случае зав-ть б вида 5 (граф метод), а в исх вар-те вида 2 или 3.
Методы смягчения проблемы гетероскедастичности.
Метод взвешенных наименьщих квадратов МВНК.
Основан на педпол-ии, что нам изв-ны знач-ия σi² для генер сов-ти.
Тогда исход урав-ие y=βo+β1xi+εi делят на соответ-ю вел-ну.
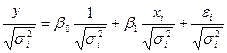 , ,
т.е. мы стандартизируем каждый эл-т исх-й вел-ны стандарта откл-ия объясн-й перем-й отн-но ур-ия регр-ии (xi/σi; yi/σi)
Но в этом случае в модели появ-ся еще 1 объясн-я перем-ая zi=1/σi, кот-ую также необ-мо расч-ть.
Итоговое ур-ие эмпир регр-ии б содер-ть 2 объясн-ие перем-ые, но в нем не б своб члена. Кач-во оценок коэф-в такого ур-ия б гарантир-м.
Но т.к. знач-ие σi² для генер сов-ти в подавл-ем бол-ве случаев неизв-ны, то исп-т 2 др метода, в кот-ых дисп-ии откл-ий неизв-ны.
|