1.
2.
Задание на проектирование
Необходимо разработать однокристального RISC процессора общего назначения, предназначенного для использования в качестве центрального процессора рабочей станции, ориентированной на работу в многопользовательском режиме, либо процессор для встроенных применений, который может использоваться в составе систем управления в реальном масштабе времени.
Общие требования
1. Операции обращения к памяти отделены от операций, связанных с обработкой данных.
2. Операции преобразования данных выполняются по принципу регистр-регистр
3. Поддерживаются операции над данными представленными в формате с фиксированной точкой и плавающей точкой.
4. Должен быть предусмотрен механизм работы с виртуальной памятью, а так же возможность работы в многозадачном режиме.
Исходные данные
Формат данных – 8 разрядов с ФТ
16 разрядов с ФТ
32 разряда с ФТ
64 разряда с ФТ
Система команд – трехадресная
Способы адресации – непосредственная
относительная
прямая
Регистровая память кол-во –8
Тип – универсальные
Разрядность – 32
Шина адрес - данные - совмещенная
Наличие сопроцессора – Да
Основная память Объем –32
Разрядность – 32
Ввод – вывод - изолированный
Прерывания – равный приоритет
2. Введение
Термин "архитектура системы" часто употребляется как в узком, так и в широком смысле этого слова. В узком смысле под архитектурой понимается архитектура набора команд. Архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту или разработчику компиляторов. Следует отметить, что это наиболее частое употребление этого термина.
В широком смысле архитектура охватывает понятие организации системы, включающее такие высокоуровневые аспекты разработки компьютера как систему памяти, структуру системной шины, организацию ввода/вывода и т.п.
Применительно к вычислительным системам термин "архитектура" может быть определен как распределение функций, реализуемых системой, между ее уровнями, точнее как определение границ между этими уровнями. Таким образом, архитектура вычислительной системы предполагает многоуровневую организацию.
Архитектура первого уровня определяет, какие функции по обработке данных выполняются системой в целом, а какие возлагаются на внешний мир (пользователей, операторов, администраторов баз данных и т.д.). Система взаимодействует с внешним миром через набор интерфейсов: языки (язык оператора, языки программирования, языки описания и манипулирования базой данных, язык управления заданиями) и системные программы (программы-утилиты, программы редактирования, сортировки, сохранения и восстановления информации).
Интерфейсы следующих уровней могут разграничивать определенные уровни внутри программного обеспечения. Например, уровень управления логическими ресурсами может включать реализацию таких функций, как управление базой данных, файлами, виртуальной памятью, сетевой телеобработкой. К уровню управления физическими ресурсами относятся функции управления внешней и оперативной памятью, управления процессами, выполняющимися в системе.
Следующий уровень отражает основную линию разграничения системы, а именно границу между системным программным обеспечением и аппаратурой. Эту идею можно развить и дальше и говорить о распределении функций между отдельными частями физической системы. Например, некоторый интерфейс определяет, какие функции реализуют центральные процессоры, а какие - процессоры ввода/вывода.
Архитектура следующего уровня определяет разграничение функций между процессорами ввода/вывода и контроллерами внешних устройств. В свою очередь можно разграничить функции, реализуемые контроллерами и самими устройствами ввода/вывода (терминалами, модемами, накопителями на магнитных дисках и лентах).
Архитектура таких уровней часто называется архитектурой физического
ввода/вывода.
Архитектура системы команд.
Классификация процессоров (CISC и RISC )
Как уже было отмечено, архитектура набора команд служит границей между аппаратурой и программным обеспечением и представляет ту часть системы, которая видна программисту или разработчику компиляторов.
Двумя основными архитектурами набора команд, используемыми компьютерной промышленностью на современном этапе развития вычислительной техники являются архитектуры CISC и RISC . Основоположником CISC-архитектуры можно считать компанию IBM с ее базовой архитектурой /360, ядро которой используется с1964 года и дошло до наших дней, например, в таких современных мейнфреймах как IBM ES/9000.
Лидером в разработке микропроцессоров c полным набором команд (CISC - Complete Instruction Set Computer) считается компания Intel со своей серией x86 и Pentium. Эта архитектура является практическим стандартом для рынка микрокомпьютеров. Для CISC-процессоров характерно: сравнительно небольшое число регистров общего назначения; большое количество машинных команд, некоторые из которых нагружены семантически аналогично операторам высокоуровневых языков программирования и выполняются за много тактов; большое количество методов адресации; большое количество форматов команд различной разрядности; преобладание двухадресного формата команд; наличие команд обработки типа регистр-память.
Основой архитектуры современных рабочих станций и серверов является архитектура компьютера с сокращенным набором команд ( RISC - Reduced Instruction Set Computer). Зачатки этой архитектуры уходят своими корнями к компьютерам CDC6600, разработчики которых (Торнтон, Крэй и др.) осознали важность упрощения набора команд для построения быстрых вычислительных машин. Эту традицию упрощения архитектуры С. Крэй с успехом применил при создании широко известной серии суперкомпьютеров компании Cray Research. Однако окончательно понятие RISC в современном его понимании сформировалось на базе трех исследовательских проектов компьютеров: процессора 801 компании IBM, процессора RISC университета Беркли и процессора MIPS Стенфордского университета.
Разработка экспериментального проекта компании IBM началась еще в конце 70-х годов, но его результаты никогда не публиковались и компьютер на его основе в промышленных масштабах не изготавливался. В 1980 году Д.Паттерсон со своими коллегами из Беркли начали свой проект и изготовили две машины, которые получили названия RISC -I и RISC -II. Главными идеями этих машин было отделение медленной памяти от высокоскоростных регистров и использование регистровых окон.
В 1981году Дж.Хеннесси со своими коллегами опубликовал описание стенфордской машины MIPS, основным аспектом разработки которой была эффективная реализация конвейерной обработки посредством тщательного планирования компилятором его загрузки.
Эти три машины имели много общего. Все они придерживались архитектуры, отделяющей команды обработки от команд работы с памятью, и делали упор на эффективную конвейерную обработку. Система команд разрабатывалась таким образом, чтобы выполнение любой команды занимало небольшое количество машинных тактов (предпочтительно один машинный такт). Сама логика выполнения команд с целью повышения производительности ориентировалась на аппаратную, а не на микропрограммную реализацию. Чтобы упростить логику декодирования команд использовались команды фиксированной длины и фиксированного формата.
Среди других особенностей RISC -архитектур следует отметить наличие достаточно большого регистрового файла (в типовых RISC -процессорах реализуются 32 или большее число регистров по сравнению с 8 - 16 регистрами в CISC-архитектурах), что позволяет большему объему данных храниться в регистрах на процессорном кристалле большее время и упрощает работу компилятора по распределению регистров под переменные. Для обработки, как правило, используются трехадресные команды, что помимо упрощения дешифрации дает возможность сохранять большее число переменных в регистрах без их последующей перезагрузки.
Развитие архитектуры RISC в значительной степени определялось прогрессом в области создания оптимизирующих компиляторов. Именно современная техника компиляции позволяет эффективно использовать преимущества большего регистрового файла, конвейерной организации и большей скорости выполнения команд. Современные компиляторы используют также преимущества другой оптимизационной техники для повышения производительности, обычно применяемой в процессорах RISC : реализацию задержанных переходов и суперскалярной обработки, позволяющей в один и тот же момент времени выдавать на выполнение несколько команд.
Следует отметить, что в последних разработках компании Intel (имеется в виду Pentium P54C и процессор следующего поколения P6), а также ее последователей-конкурентов (AMD R5, Cyrix M1, NexGen Nx586 и др.) широко используются идеи, реализованные в RISC -микропроцессорах, так что многие различия между CISC и RISC стираются. Однако сложность архитектуры и системы команд x86 остается и является главным фактором, ограничивающим производительность процессоров на ее основе.
3. Методы адресации и типы данных
В машинах к регистрами общего назначения метод (или режим) адресации объектов, с которыми манипулирует команда, может задавать константу, регистр или ячейку памяти. Для обращения к ячейке памяти процессор прежде всего должен вычислить действительный или эффективный адрес памяти, который определяется заданным в
команде методом адресации.
Адресация непосредственных данных и литеральных констант обычно рассматривается как один из методов адресации памяти (хотя значения данных, к которым в этом случае производятся обращения, являются частью самой команды и обрабатываются в общем потоке команд). Адресация регистров, как правило, рассматривается отдельно. В данном разделе методы адресации, связанные со счетчиком команд (адресация относительно счетчика команд) рассматриваются отдельно. Этот вид адресации используется главным образом для определения программных адресов в командах передачи управления.
Ниже на примере команды сложения (Add) приведены наиболее употребительные названия методов адресации, хотя при описании архитектуры в документации разные производители используют разные названия для этих методов.
Метод адресации
|
Пример
команды
|
Смысл команды
метода
|
Использование
|
| Регистровая |
Add R4,R3 |
R4=R4+R5 |
Требуемое значение в регистре |
Непосредственная или литеральная
|
Add R4,#3 |
R4=R4+3 |
Для задания констант |
| Базовая со смещением |
Add R4,100(R1) |
R4=R4+M[100+R1] |
Для обращения клокальным переменным
|
| Косвенная регистровая |
Add R4,(R1) |
R4=R4+M[R1] |
Для обращения по указателю или вычисленному адресу
|
| Индексная |
Add R3,(R1+R2) |
R3=R3+M[R1+R2] |
Иногда полезна при работе с
Массивами: R1 - база, R3 - индекс
|
| Прямая или абсолютная |
Add R1,(1000) |
R1=R1+M[1000] |
Иногда полезна для обращения к статическим данным |
| Косвенная |
Add R1,@(R3) |
R1=R1+M[M[R3]] |
Если R3-адрес указателя p, то выбирается значение по этому указателю |
| Автоинкрементная |
Add R1,(R2)+ |
R2=R2+d
R1=R1+M[R2]
|
Полезна для прохода в цикле по массиву с шагом: R2 – началомассива
В каждом цикле R2 получает приращение в
|
| Автодекрементная |
Add R1,(R2)- |
R1=R1+M[R2]
R2=R2-d
|
Аналогична предыдущей |
| Базовая индексная со смещением имасштабированием |
Add R1,100(R2)[R3] |
R1=R1+M[100]+R2+R3*d |
Для индексации массивов
|
4. Типы команд
Команды традиционного машинного уровня можно разделить на несколько типов
| Тип операции
|
Примеры
|
| Арифметические и логические |
Целочисленные арифметические и логические операции: сложение, вычитание, логическое сложение, логическое умножение и т.д. |
| Пересылки данных |
Операции загрузки/записи |
| Управление потоком команд |
Безусловные и условные переходы, вызовы процедур и возвраты |
| Системные операции |
Системные вызовы, команды управления виртуальной памятью и т.д. |
| Операции с плавающей точкой |
Операции сложения, вычитания, умножения и деления над вещественными числами |
| Десятичные операции |
Десятичное сложение, умножение, преобразование форматов и т.д. |
| Операции над строками |
Пересылки, сравнения и поиск строк |
5.Формат команд
Существует несколько видов форматов команд, а точнее 3
- одноадресная
- двухадресная
- трехадресная
Желательно чтобы команда имела 32-х разрядный формат. В задании на проектирование было указанно использование 3-х адресной команды.
Она имеет следующий вид:

31 0
КОП- 7- разрядное поле кода операции. Позволяет определить что за операция должна выполняться.
R0, R1, R2 – регистр-приемник и регистры-источники данных.
R0 и R1 – 3-разряда
R2- 19-разрядов.
Содержимое поля R2 интерпретируется не только как номер регистра, но и как смещение при операциях обращения к памяти. И адрес памяти определяется как A=<R1>+R2.
6.Форматы данных
В процессоре могут использоваться числа с фиксированной точкой и плавающей точкой.
Числа с ФТ представляют собой целые со знаком или без знака. Старший бит числа является знаковым. Нулевое значение этого бита указывает на то, что число положительное, единичное на то, что число отрицательное.
Целые со знаком представляются в дополнительном коде. Положительные числа в дополнительном коде записываются просто как двоичные числа без знака, а отрицательные выражаются числом которое будучи добавлено к положительному числу той же величины даст в результате ноль. Для получения отрицательного числа нужно для каждого бита положительного числа сформировать дополнение до 1 или обратный код, т.е. вместо 0 записать 1 и наоборот, а затем к полученному результату прибавить 1(это даст дополнительный код).
Целые без знака используют так же для представления адресов.
Числа с ПТ имеют один знаковый бит, 8 битов порядка и 23 бита мантиссы. При работе с ними необходимо предусмотреть несколько исключительных ситуаций
+0: s=0; p=0..0; M=0..0;
-0: s=1; p=0..0; M=0..0;
-¥: s=0; p=1..1; M=0..0;
+¥: s=1; p=1..1; M=0..0;
NAN: s=X; p=1..1; M=X..X( кроме 0,,0).

1 байт - знаковый 7 6 0
 -беззнаковый -беззнаковый
7 0
состоит из 8 разрядов и изменяется от –127 до +127

2 полуслово - знаковое 15 14 0
-беззнаковое
15 0
состоит из 16 разрядов и изменяется от -32768 до +32768
3 слово -знаковое
31 30 0
-беззнаковое
31 0 состоит из 32 разрядов
 
4 число с ПТ
31 30 23 22 0
7. Виртуальная память
Виртуальная память и организация защиты памяти
Концепция виртуальной памяти
Общепринятая в настоящее время концепция виртуальной памяти появилась достаточно давно. Она позволила решить целый ряд актуальных вопросов организации вычислений.
Прежде всего к числу таких вопросов относится обеспечение надежного функционирования мультипрограммных систем. В любой момент времени компьютер выполняет множество процессов или задач, каждая из которых располагает своим адресным пространством. Было бы слишком накладно отдавать всю физическую память какой-то одной задаче тем более, что многие задачи реально используют только небольшую часть своего адресного пространства.
Поэтому необходим механизм разделения небольшой физической памяти между различными задачами. Виртуальная память является одним из способов реализации такой возможности.
Она делит физическую память на блоки и распределяет их между
различными задачами. При этом она предусматривает также некоторую схему защиты, которая ограничивает задачу теми блоками, которые ей принадлежат.
Большинство типов виртуальной памяти сокращают также время начального запуска программы на процессоре, поскольку не весь программный код и данные требуются ей в физической памяти, чтобы начать выполнение.
Другой вопрос, тесно связанный с реализацией концепции виртуальной памяти, касается организации вычислений на компьютере задач очень большого объема. Если программа становилась слишком большой для физической памяти, часть ее необходимо было хранить во внешней памяти (на диске) и задача приспособить ее для решения на компьютере ложилась на программиста. Программисты делили программы на части и затем определяли те из них, которые можно было бы выполнять независимо, организуя оверлейные структуры, которые загружались в основную память и выгружались из нее под управлением программы пользователя. Программист должен был следить за тем, чтобы программа не обращалась вне отведенного ей пространства физической памяти. Виртуальная память освободила программистов от
этого бремени. Она автоматически управляет двумя уровнями иерархии памяти: основной памятью и внешней (дисковой) памятью.
Кроме того, виртуальная память упрощает также загрузку программ, обеспечивая механизм автоматического перемещения программ, позволяющий выполнять одну и ту же программу в произвольном месте физической памяти.
Системы виртуальной памяти можно разделить на два класса: системы с фиксированным размером блоков, называемых страницами, и системы с переменным размером блоков, называемых сегментами.
Ниже рассмотрен первый тип организации виртуальной памяти.
Страничная организация памяти
В системах со страничной организацией основная и внешняя память (главным образом дисковое пространство) делятся на блоки или страницы фиксированной длины.
Каждому пользователю предоставляется некоторая часть адресного пространства, которая может превышать основную память компьютера и которая ограничена только возможностями адресации, заложенными в системе команд. Эта часть адресного пространства называется виртуальной памятью пользователя. Каждое слово в виртуальной памяти пользователя определяется виртуальным адресом, состоящим из двух частей: старшие разряды адреса рассматриваются как номер страницы, а младшие - как номер слова (или байта) внутри страницы.
Управление различными уровнями памяти осуществляется программами ядра операционной системы, которые следят за распределением страниц и оптимизируют обмены между этими уровнями. При страничной организации памяти смежные виртуальные страницы не обязательно должны размещаться на смежных страницах
основной физической памяти. Для указания соответствия между виртуальными страницами и страницами основной памяти операционная система должна сформировать таблицу страниц для каждой программы и разместить ее в основной памяти машины. При этом каждой странице программы, независимо от того находится ли она в основной памяти или нет, ставится в соответствие некоторый элемент таблицы страниц. Каждый элемент таблицы страниц содержит номер физической страницы основной памяти и специальный индикатор. Единичное состояние этого индикатора свидетельствует о наличии этой страницы в основной памяти. Нулевое состояние индикатора означает отсутствие страницы в оперативной памяти.
Для увеличения эффективности такого типа схем в процессорах используется специальная полностью ассоциативная кэш-память, которая также называется буфером преобразования адресов ( TLB traнсlation-lookaside buffer). Хотя наличие TLB не меняет принципа построения схемы страничной организации, с точки зрения защиты памяти, необходимо предусмотреть возможность очистки его при переключении с одной программы на другую.
Поиск в таблицах страниц, расположенных в основной памяти, и загрузка TLB может осуществляться либо программным способом, либо специальными аппаратными средствами. В последнем случае для того, чтобы предотвратить возможность обращения пользовательской программы к таблицам страниц, с которыми она не связана, предусмотрены специальные меры. С этой целью в процессоре предусматривается дополнительный регистр защиты, содержащий описатель (дескриптор) таблицы страниц или базово-граничную пару.
База определяет адрес начала таблицы страниц в основной памяти, а граница - длину таблицы страниц соответствующей программы. Загрузка этого регистра защиты разрешена только в привилегированном режиме. Для каждой программы операционная система хранит дескриптор таблицы страниц и устанавливает его в регистр защиты процессора перед запуском соответствующей программы.
Отметим некоторые особенности, присущие простым схемам со страничной организацией памяти. Наиболее важной из них является то, что все программы, которые должны непосредственно связываться друг с другом без вмешательства операционной системы, должны использовать общее пространство виртуальных адресов. Это относится и к самой операционной системе, которая, вообще говоря, должна работать в режиме динамического распределения памяти. Поэтому в некоторых системах пространство виртуальных адресов пользователя укорачивается на размер общих процедур, к которым программы пользователей желают иметь доступ. Общим процедурам должен быть отведен определенный объем пространства виртуальных адресов всех пользователей, чтобы они имели постоянное место в таблицах страниц всех пользователей. В этом случае для обеспечения целостности, секретности и взаимной изоляции выполняющихся программ должны быть предусмотрены различные режимы доступа к страницам, которые реализуются с помощью специальных индикаторов доступа в элементах таблиц страниц.
Следствием такого использования является значительный рост таблиц страниц каждого пользователя. Одно из решений проблемы сокращения длины таблиц основано на введении многоуровневой организации таблиц. Частным случаем многоуровневой организации таблиц является сегментация при страничной организации памяти.
Необходимость увеличения адресного пространства пользователя объясняется желанием избежать необходимости перемещения частей программ и данных в пределах адресного пространства, которые обычно приводят к проблемам переименования и серьезным затруднениям в разделении общей информации между многими задачами.
8. Регистровая модель процессора

Flags


Регистровая модель процессора состоит из
1 PC- 32-x разрядный счетчик команд; C его помощью устройство выборки команд считывает слова, начиная с адреса на 1 большего значения записанного в PC
2 BVA- 32-разрядныйрегистр в него записывается адрес плохой страницы. Т.е. когда идет обращение к какой то странице памяти не находящейся в оперативной памяти происходит запись адреса этой страницы в BFA, а затем с помощью этого адреса происходит загрузка страници в ОП.
3 Flags – 8-разрядный регистр регистр флажков. Если происходит одно из событий, которые могут отражаться в этом регистре, то происходит установка того или иного флажка.
Z- признак нулевого результата
C- признак переноса из старшего разряда
S- знак результата
O- признак переполнения
I- флаг прерывания
T- флаг ловушки
U- флаг пользователь/супервизор
PL- флаг уровня привелегий
4 TLBP- 32-разрядный регистр указатель на таблицу переадресации
5 TINT – 32-разрядный регистр указатель на таблицу векторов прерываний
6 8 - 32-разрядных регистров общего назначения
9. Сопроцессор
Сопроцессор нужен для выполнения операций над числами с плавающей точкой.
Схема совместной работы ЦП и сопроцессора выглядит следующим образом.
wait
 
Вариант организации работы:
1. Оба процессора просматривают поток команд и каждый выбирает свою
2. Все операции с адресами делает ЦП
3. С точки зрения ЦП набор команд с ПТ это одна команда
4. Сигнал wait необходим для проверки того занят ли сопроцессор вычислениями или нет.Он проверяет вход busy.
Форматы данных
Как было сказанно выше сопроцессор нужен для работы с числами пре дставленными в формате с плавающей точкой.
Существует три вида чисел с плавающей точкой
1. 32- разрядное
2. 64- разрядное
3. 80 – разрядное (для внутренних вычислений)
Вид чисел с ПТ См выше (глава типы данных).
10. Регистровая модель сопроцессора
FR0
FR1
FR2
.
.
.
.
.
.
.
FR6
FR7
|
|
    
| B Z S O I IR PE UE OE ZE IE |
|


Регистровая модель сопроцессора состоит из
1 8 32- разрядных РОН
2 SR- регистр статуса. В нем отражаются все процессы и события происходящие в сопроцессоре.
B- бизи-бит показывает свободен или занят сопроцессор
Z- флаг нуля
S- флаг знака
O-переполнени
I-разрешение прерывания
IR-запрет прерывания
PE-потеря точности
UE-денормализация
OE-переполние
ZE-деление на ноль
IE-недействительный операнд.
3 CR- регистр управления. С его помощью происходит управление арифметическими операциями происходящими в сопроцессоре
IC – тип арифметики: 0- афинная
1- проекционная
Афинная – обычная арифметика и ±¥
Прекционная только ±¥
RC-режим округления
00- к ближнему целому
01- к -¥
10- к +¥
11- к 0
PC-способ выдачи информации
00-80-разрядов
01- 32 - разряда
10- 64-разряда
Masks- позволяет маскировать прерывания.
4 ER- регистр ошибок в него записывается КОП, адрес команды и операции, которые вызвали ошибки.
11. Система команд процессора и сопроцессора
| № |
Name |
Содержание |
Функция |
Флаги |
Код |
| Z |
C |
S |
O |
I |
T |
U |
| Обращение к памяти по чтению и записи |
| 1. 1 |
RDB |
Чтение байта |
R0<= <R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
000000 |
| 2. |
RDHW |
Чтение полуслова |
R0<= <R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
000001 |
| 3. |
RDW |
Чтение слова |
R0<= <R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
000010 |
| 4. |
WRB |
Запись байта |
<R0>=> <R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
000011 |
| 5. |
WRHW |
Запись полуслова |
<R0>= ><R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
000100 |
| 6. |
WRW |
Запись слова |
<R0>=> <R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
000101 |
| 7. |
IN |
Чтение из порта |
R0<=порт<R1> |
- |
- |
- |
- |
- |
- |
- |
000110 |
| 8. |
OUT |
Запись в порт |
R0=>порт<R1> |
- |
- |
- |
- |
- |
- |
- |
000111 |
| 9. |
MOV |
Обмен RG<>RG |
<R0><=<R1> |
- |
- |
- |
- |
- |
- |
- |
001000 |
| 10. |
MOVI |
Занос в регистр значения |
<R0><= R2 |
- |
- |
- |
- |
- |
- |
- |
001001 |
| Арифметические операции с ФТ |
| 11. |
ADD |
Сложение |
<R0><= <R1>+<R2> |
+ |
+ |
+ |
+ |
- |
- |
- |
001100 |
| 12. |
SUB |
Вычитание |
<R0><= <R1>-<R2> |
+ |
+ |
+ |
+ |
- |
- |
- |
001101 |
| 13. |
MUL |
Умножение |
<R0><= <R1>*<R2> |
+ |
+ |
+ |
+ |
- |
- |
- |
001110 |
| 14. |
DIV |
Деление |
<R0><= <R1>/<R2> |
+ |
+ |
+ |
+ |
- |
- |
- |
001111 |
| 15. |
ADDI |
Сложение с неп оп. |
<R0><= <R1>+R2 |
+ |
+ |
+ |
+ |
- |
- |
- |
010000 |
| 16. |
SUBI |
Выч. с неп оп. |
<R0><= <R1>-R2 |
+ |
+ |
+ |
+ |
- |
- |
- |
010001 |
| 17. |
MULI |
Умн/ с неп оп. |
<R0><= <R1>*R2 |
+ |
+ |
+ |
+ |
- |
- |
- |
010010 |
| 18. |
DIVI |
Деление с неп оп. |
<R0><= <R1>/R2 |
+ |
+ |
+ |
+ |
- |
- |
- |
010011 |
| Логические оперции с ФТ |
| 19. |
AND |
«И» |
<R0><= <R1>&<R2> |
+ |
- |
+ |
- |
- |
- |
- |
010100 |
| 20. |
OR |
«ИЛИ» |
<R0><= <R1>v<R2> |
+ |
- |
+ |
- |
- |
- |
- |
010101 |
| 21. |
XOR |
Искл «ИЛИ» |
<R0><= <R1>+<R2> |
+ |
- |
+ |
- |
- |
- |
- |
010110 |
| 22. |
NOT |
«НЕ» |
<R0><= ~<R1> |
+ |
- |
+ |
- |
- |
- |
- |
010111 |
| 23. |
RCL |
Циклический сдвиг влево |
- |
+ |
- |
+ |
- |
- |
- |
011000 |
| 24. |
RCR |
Циклический сдвиг вправо |
- |
+ |
- |
+ |
- |
- |
- |
011001 |
| Команды переходов и прерываний |
| 25. |
CLI |
Очистить флаг разрешения прерываний |
0 |
011010 |
| 26. |
INT |
Вызов прерывания |
<R7><=PC
<R6><=flags
|
+ |
+ |
+ |
+ |
+ |
+ |
+ |
011100 |
| 27. |
IRET |
Возврат из прерывания |
<PC><=R7
flags<=R6
|
- |
- |
- |
- |
- |
- |
- |
011101 |
| 28. |
CALL |
Вызов подпрограммы |
<R7><=PC
PC<=<R1>+R2
|
- |
- |
- |
- |
- |
- |
- |
011110 |
| 29. |
RET |
Возврат из подпрограммы |
<PC><=R7
|
- |
- |
- |
- |
- |
- |
- |
011111 |
| 30. |
JMP |
Безусловный переход |
PC<=<R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
100000 |
| 31. |
JZ |
Переход по нулю |
PC<=<R1>+R2 |
+ |
- |
- |
- |
- |
- |
- |
100001 |
| 32. |
JNZ |
Переход не по нулю |
PC<=<R1>+R2 |
+ |
- |
- |
- |
- |
- |
- |
100010 |
| 33. |
JO |
Переход по переполнению |
PC<=<R1>+R2 |
- |
- |
- |
+ |
- |
- |
- |
100011 |
| 34. |
JNO |
Переход по не переполнению |
PC<=<R1>+R2 |
- |
- |
- |
+ |
- |
- |
- |
100100 |
| 35. |
JC |
Переход по переносу |
PC<=<R1>+R2 |
- |
+ |
- |
- |
- |
- |
- |
100101 |
| 36. |
JNC |
Переход не по переносу |
PC<=<R1>+R2 |
- |
+ |
- |
- |
- |
- |
- |
100110 |
| 37. |
JS |
Переход переход по меньше нуля |
PC<=<R1>+R2 |
- |
- |
+ |
- |
- |
- |
- |
100111 |
| 38. |
JNS |
Переход переход по не меньше нуля |
PC<=<R1>+R2 |
- |
- |
+ |
- |
- |
- |
- |
101000 |
| Специальные операции |
| 39. |
RFL |
Чтение флагов |
R1<=Flags |
- |
- |
- |
- |
- |
- |
- |
101001 |
| 40. |
WFL |
Запись флагов |
<R1>=>Flags |
+ |
+ |
+ |
+ |
+ |
+ |
+ |
101010 |
| 41. |
RTLBR |
Чтение TLBP |
R1<=TLB |
- |
- |
- |
- |
- |
- |
- |
101011 |
| 42. |
WTLBR |
Запись TLBP |
<R1>=>TLB |
- |
- |
- |
- |
- |
- |
- |
101100 |
| 43. |
RISR |
Чтение TINT |
R1<=TINT |
- |
- |
- |
- |
- |
- |
- |
101101 |
| 44. |
WISR |
Запись TINT |
<R1>=>TINT |
- |
- |
- |
- |
- |
- |
- |
101110 |
| 45. |
RBVA |
Чтение BVA |
<R0><=BVA |
- |
- |
- |
- |
- |
- |
- |
110011 |
| 46. |
RFE |
Возврат в пользователя |
- |
- |
- |
- |
- |
- |
0 |
101111 |
| 47. |
SCALL |
Переход в супервизора |
- |
- |
- |
- |
- |
- |
1 |
110000 |
| 48. |
HALT |
Ожидание прерывания |
- |
- |
- |
- |
1 |
- |
- |
110001 |
| 49. |
NOP |
Нет операции |
PC<=<PC>+1 |
- |
- |
- |
- |
- |
- |
- |
110010 |
| Арифметические операции с ПТ |
| 50. |
FADD |
Сложение |
<F0><= <F1>+<F2> |
+ |
+ |
+ |
+ |
- |
- |
- |
111000 |
| 51. |
FSUB |
Вычитание |
<F0><= <F1>-<F2> |
+ |
+ |
+ |
+ |
- |
- |
- |
111001 |
| 52. |
FMUL |
Умножение |
<F0><= <F1>*<F2> |
+ |
+ |
+ |
+ |
- |
- |
- |
111010 |
| 53. |
FDIV |
Деление |
<F0><= <F1>/<F2> |
+ |
+ |
+ |
+ |
- |
- |
- |
111011 |
| 54. |
FMOV |
Обмен RG<>RG |
F0<=<F1> |
- |
- |
- |
- |
- |
- |
- |
111100 |
| 55. |
FRDW |
Чтение |
<F0><= <R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
111101 |
| 56. |
FWRW |
Запись |
<F0><= <R1>+R2 |
- |
- |
- |
- |
- |
- |
- |
111110 |
| 57. |
MFC |
Преобр ПТ-ФТ |
<R0><= <F1> |
+ |
+ |
+ |
+ |
- |
- |
- |
111111 |
| 58. |
MCF |
Преобр ФТ-ПТ |
<R0>=> <F1> |
+ |
- |
+ |
+ |
- |
- |
- |
111111 |
1 Обращение к памяти по чтению и записи.
С помощью этих команд можно заносить данные и регистров в память и читать их оттуда.
2 Арифметические и логические операции с ФТ
Позволяют производить известные операции с числами с ФТ, которые хранятся в регистрах или с непосредственными операндами
3 Специальные операции.
Позволяют работать с системными регистрами, заносить туда информацию и считывать ее от туда. Команды с 40 по 46 возможны только в режиме супервизора. В пользовательском режиме они недоступны.
4 Арифметические операции с ПТ
Известные операции аналогичные с ФТ, плюс операции сдвигов влево и вправо.
1
2
.
Структура внешних выводов процессора
Процессор имеет совмещенную шину адреса и данных (AD). Сигнал ALE используется для фиксации адреса на внешнем регистре-защелке. Пара сигналов HLD и HLDA используется для реализации механизма захвата шины. Сигнал INT является сигналом запроса прерывания. Сигнал NMI – запрос немаскируемого прерывания.
Линии RD(чтение), WR(запись), IN(ввод), OUT(вывод), задают выполняемую на шине операцию.
Сигналы CC0, CC1, Wait используются для взаимодействия с сопроцессором. Линии CC0, CC1 служат для синхронизации работы с мат сопроцессором.
| СС0 |
СС1 |
| 0 |
0 |
Нет операции |
| 0 |
1 |
Очистка очереди |
| 1 |
0 |
Запись команды в буфер |
| 1 |
1 |
Выборка команды |
На контакт WAIT поступает сигнал об окончании вычислений
По шине FFLAGS в ЦП передаются флаги от сопроцессора
Контакт READY служит для приема сигналов готовности от медленных внешних устройств
Общее число выводов процессора составляет 65, поэтому процессор размещается в стандартном 68 выводном корпусе. Оставшиеся ножки подаются на «Земля» или «Питание»
13.
Структура внешних выводов сопроцессора
В сопроцессоре на вывод FPBUSY подается единичный сигнал указывающий на то, что сопроцессор занят. По линии FPINT выдается сигнал прирывания в случае ошибки. Назначение остальных выводов такое же как и у ЦП.


  Уст-во
предвыборки команд
|
|
 14. Структурная схема процессора 14. Структурная схема процессора
1 Устройство предвыборки команд осуществляет опережающую выборку. Это позволяет избежать простоя процессора в циклах выборки команд. Устройство считывает из памяти слова начиная с адреса на 1 большего значения записанного в PC. Очередное слово из очереди подается на дешифратор. Освободившаяся позиция в конце очереди заполняется следующей командой.
2 Дешифратор команд получает слово от устройства предвыборки и дешифрует его. Преобразованный код записывается в регистр команд.
3 Регистр команд хранит команду полученную от дешифратора.
4 Счетчик команд содержит адрес выполняемой в данный момент команды.
5 Устройство управления осуществляет координацию работы отдельных блоков процессора и осуществляет его взаимодействие с внешней шиной.
6 Контроллер равноприоритетных прерываний осуществляет выборку приходящих программных прерываний.
7 Буфер A/D служит для взаимодействия процессора с системной шиной и может переводить процессор в Z состояние, отключая его тем самым от шины.
8 АЛУ- выполняет операции над данными изРОНов. Используется для операций над числами с ФТ.
10 Регистр флагов включает в себя 8 флагов 4 из которых соответствуют различным признакам результата.
15. Алгоритм функционирования процессора
      
    
   



  

Уст-во
предвыборки команд
|
|
16. Структурная схема сопроцессора
  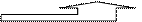 
Структурная схема работы сопроцессора состоит из тех же блоков, что и ЦП. Основное отличие: отсутствует блок запросов прерываний и АЛУ предназначено для операций над числами с ПТ
17. Алгоритм функционирования сопроцессора

                    

 18. Выводы
Был разработан однокристальный RISC процессор общего назначения.
Для него была разработанна
1 Регистровая модель процессора
2 Регистровая модель сопроцессора
3 Система команд
В процессе разработки мы ознакомились с такими понятиямикак :
Виртуальная память
Форматы данных
Форматы команд
Сопроцессор (назначение и организация функционирования)
Так же была разработана программа моделирующая работу процессора и показывающая особенности доступа и обработки данных во обоих возможных режимах (пользователь/ супервизор).
|