Корреляционный анализ
.
1. Сбор и анализ данных.
Будем считать, что данные, кот. нам даны – это случайная выборка.
Анализ данных – проводится с целью принятия гипотезы о виде корр. зависимости. График корр. поля. Если принимается гипотеза о линейной зависимости, то
2. Вычисл. лин. коэфф. корр.
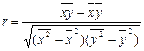
3. Проверка стат. значимости
а) принимается нулевая гипотеза об отсутствии корр. в ген. совок-ти
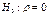
б) альт. гип-за, что корр. есть
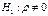
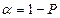 , где Р – дов. интер-ал , где Р – дов. интер-ал
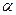 - ур-ень знач. гипотезы. - ур-ень знач. гипотезы.
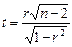
а) 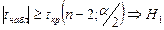 Отличие коэфф. корр. от нуля не случайно, выборочн. коэфф. корр. статистич. значим. С вероятностью Р корр. есть. Отличие коэфф. корр. от нуля не случайно, выборочн. коэфф. корр. статистич. значим. С вероятностью Р корр. есть.
б) 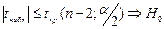 Нет основания отвергнуть Нет основания отвергнуть 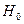 , в выборке корр. есть, а в ген. сов-ти нет. Выборка случайна. Коэфф. корр. стат. незначим. , в выборке корр. есть, а в ген. сов-ти нет. Выборка случайна. Коэфф. корр. стат. незначим.
4. Выводы и рекомендации.
а) Наличие достаточно большого по величине стат. значимого выборочного коэфф. корр. свидет-ет о наличии достат. тесной корр. зав-ти м/у исследуемыми показателями т.е. изменение одного показателя ведет за собой изменение ср. знач-я другого показ-ля и это св-во с опред. вероятностью распространяется на всю ген. совокупность.
Если ЛПР считает политику в прошлом правильной, тоее можно распространить на будущее.
б) Если наоборот, то политика была неэфф., в будущем ее надо менять.
Множеств. корреляция
.
Коэфф. множеств. корр. показывает степень влияния всех остальных факторов на один (два…). Составляется матрица парных коэффициентов корр-ции:
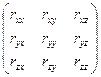 или или 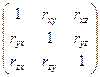 теперь: теперь: 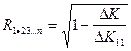 , где , где 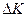 - определитель полной корр. матрицы, а - определитель полной корр. матрицы, а 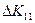 - определитель полной корр. матрицы без k-ого столбца и k-ой строки. - определитель полной корр. матрицы без k-ого столбца и k-ой строки.
Частная корреляция
.
Частный коэфф-ент корр. показывает м/у двумя факторами при исключении третьего (в отличии от парного коэффициента, кот. не исключает влияния остальных факторов).
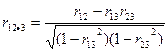 - частная формула - частная формула
(общая имеет вид 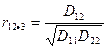 , где , где 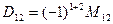 ) )
Чем ближе частный коэфф. корр. к парному, тем меньше влияние третьего фактора на первые 2.
Проверка стат. значимости.
Аналогично выдвигаются две гипотезы.
Гипотезы проверяются с помощью t-статистики Стьюдента
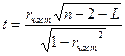 где L – число исключаемых факторов, n– число степеней свободы. где L – число исключаемых факторов, n– число степеней свободы.
а) 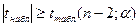 - гипотеза об отсутствии влияния исключаемых факторов на рассматриваемые отклоняется. Исключаемые факторы влияют на взаимосвязь рассматр. факторов с вероятностью. - гипотеза об отсутствии влияния исключаемых факторов на рассматриваемые отклоняется. Исключаемые факторы влияют на взаимосвязь рассматр. факторов с вероятностью.
б)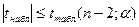 - принимаем гипотезу об отсутствии влияния исключаемых факторов на рассматриваемые. Исключ. факторы не влияют с вероятностью ошибки . - принимаем гипотезу об отсутствии влияния исключаемых факторов на рассматриваемые. Исключ. факторы не влияют с вероятностью ошибки .
Регрессионный анализ.
1 этап. Построение задачи и определение цели регрессии исследования.
2 этап. Сбор и анализ данных.
3 этап. Спецификация.
4 этап. Оценка качества модели.
а) Анализ остатков.
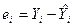
1) Графический способ.
Наблюдение, кот. связано с выбросом, исключается таблицы данных и модель пересчитывается снова для нового объема данных.
2) Критерий серий.
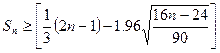 , , 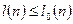 , где , где 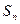 - число серий, - число серий, 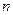 - длина ряда, - длина ряда, 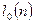 - макс. длина серии. При этом если - макс. длина серии. При этом если 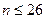 , то , то 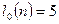 , если , если 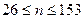 , то , то 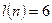 . Если хотя бы одно неравенство нарушено, то гипотезу о случайности отвергают. . Если хотя бы одно неравенство нарушено, то гипотезу о случайности отвергают.
3) Критерий Дарбина-Уотсона.
Принимается гипотеза 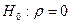 и альтернативная ей и альтернативная ей 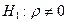 . .
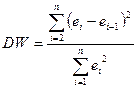
По таблице ( - число наблюдений, 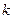 - число факторов в модели) находятся значения - число факторов в модели) находятся значения 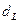 и и 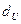 . .
 Положительная Положительная
автокорреляция ? Автокорреляция отсутствует ? Отрицат. автокорреляция
 0 4- 4- 4 0 4- 4- 4
Выводы:
Остатки удовлетворяют основным требованиям регрессионного анализа и можно переходить к следующему этапу;
Остатки не удовлетворяют основным требованиям регрессионного анализа, необходимо вернуться к исследованию спецификации модели на первом и втором этапах.
б) Анализ качества коэфф. регрессии.
Принимается гипотеза о том, что в ген. совок-ти фактор 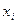 не оказывает воздействия на изменение результативного признака т.е. нет регресс. зависимости м/у не оказывает воздействия на изменение результативного признака т.е. нет регресс. зависимости м/у 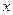 и и 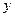 . .
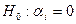
Проверка этой гипотезы осущ. с помощью t-статистики:
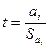 , где , где 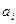 - оценка коэфф. регрессии, - оценка коэфф. регрессии,  - оценка стандартной ошибки коэфф. регрессии - оценка стандартной ошибки коэфф. регрессии 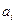 в модели: в модели:
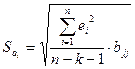 , где , где 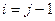 ; ;  - остатки, - число наблюдений, - число факторов в модели, - остатки, - число наблюдений, - число факторов в модели, 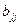 - диагональный элемент обратной матрицы системы нормальных уравнений. - диагональный элемент обратной матрицы системы нормальных уравнений.
Если 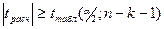 , то данные наблюдений с уровнем значимости дают основания для отклонения гипотезы об отсутствии корр. зав-ти м/у фактором , то данные наблюдений с уровнем значимости дают основания для отклонения гипотезы об отсутствии корр. зав-ти м/у фактором 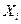 и и 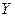 , коэфф. регрессии стат. значим, его отличие от нуля не случайно. , коэфф. регрессии стат. значим, его отличие от нуля не случайно.
Если 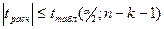 , то данные наблюдений с уровнем значимости дают основания для принятия гипотезы об отсутствии регрессионной зависимости м/у фактором и , выборочный коэфф. регрессии стат. незначим, его отличие от нуля случайно, фактор не оказывает стат. значимого воздействия на изменение результативного признака . Фактор следует исключить из модели. , то данные наблюдений с уровнем значимости дают основания для принятия гипотезы об отсутствии регрессионной зависимости м/у фактором и , выборочный коэфф. регрессии стат. незначим, его отличие от нуля случайно, фактор не оказывает стат. значимого воздействия на изменение результативного признака . Фактор следует исключить из модели.
в) Построение доверительных интервалов для коэфф. теор. ур-я регрессии.
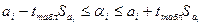
г) Оценка качества модели в целом.
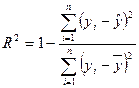 - коэфф. детерминации, - коэфф. детерминации, 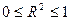 , чем ближе к 1, тем большее влияние оказ. факторы, включ. в модель. , чем ближе к 1, тем большее влияние оказ. факторы, включ. в модель.
Принимается гипотеза об отсутствии совместного влияния всех факторов на изменение т.е. 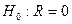 . Проверка осущ. с помощью критерия Фишера: . Проверка осущ. с помощью критерия Фишера:
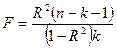 , где - число факторов. , где - число факторов.
Если 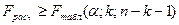 , то гипотеза отклоняется; все факторы оказывают опред. совместное влияние на изменение . , то гипотеза отклоняется; все факторы оказывают опред. совместное влияние на изменение .
Криволинейная корр. зависимость.
Линейный коэфф. корр. применять нельзя. Применяются корр. отношения.
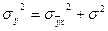 , где , где  - групповая дисперсия, - групповая дисперсия,  - остаточная (межгрупповая) дисперсия, - остаточная (межгрупповая) дисперсия, 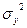 - общая дисперсия. - общая дисперсия.
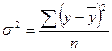 , далее рассчитывается показатель , далее рассчитывается показатель 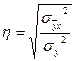 . .
| 1 |
2 |
3 |
4 |
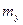 |
| 2 |
1 |
2 |
3 |
| 4 |
2 |
1 |
3 |
| 5 |
1 |
1 |
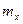 |
2 |
1 |
2 |
2 |
7 |
Пример. Дано:
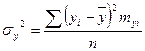 , , 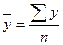 . . 
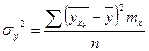 , , 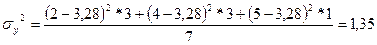
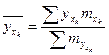
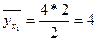 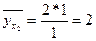 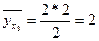 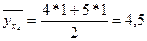
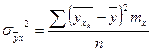 , , 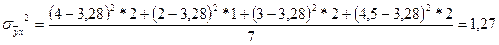
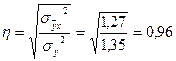 , ,  - корр. отношение. - корр. отношение.
Проверка стат. значимости: критерий Фишера:
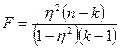 , где - число группировок по , , где - число группировок по , 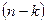 - число степ. свободы. - число степ. свободы.
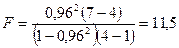 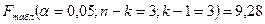 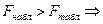 принимаем гипотезу о наличии корр. зависимости. принимаем гипотезу о наличии корр. зависимости.
Способы построения модели регрессии.
Метод последовательного включения.
Все данные должны представлять случайную выборку.
На основе данных определяется корреляционная матрица:
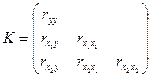 , 1 столбец – показывает взаимосвязь со всеми факторами; 2, 3 – отражает межфакторные взаимодействия. Если межфакторный коэфф. больше 0,8, то это мультиколлинеарность – плохо. , 1 столбец – показывает взаимосвязь со всеми факторами; 2, 3 – отражает межфакторные взаимодействия. Если межфакторный коэфф. больше 0,8, то это мультиколлинеарность – плохо.
По первому столбцу выбирается мах стат. значимый коэфф. регр-ии. Соответствующий фактор первым включается в модель (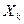 ). ).
Далее определяется 2 фактор. Вычисляется частный коэфф. корр. 1 порядка м/у и всеми оставшимися факторами, за искл. уже включ. в модель.
 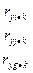 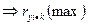 . В модель включ. фактор . . В модель включ. фактор .
Далее вычисл. частный коэф. корр. II порядка при исключ. уже включ. факторов:
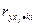 и т.д. и т.д.
Каждый раз строятся модели, вычисл. t-статистики, 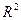 , F. Если добавление фактора в модель увеличивает , то он считается полезным. В противном случае он считается вредным. , F. Если добавление фактора в модель увеличивает , то он считается полезным. В противном случае он считается вредным.
Метод последовательного исключения.
Применяется, если среди факторных переменных есть неслуч. переменные.
Сначала строится регесс. модель, включ. все факторные переменные. производится оценка коэфф. регрессии, для всех коэфф. опред. t-статистика. Если в построенной модели все 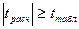 , то модель адекватна и по другим критериям. Построение модели заканчивается. , то модель адекватна и по другим критериям. Построение модели заканчивается.
Если же для нескольких факторов 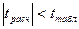 , то из модели исключ. фактор с наименьшим , то из модели исключ. фактор с наименьшим 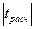 . Перерасчитывается модель регрессии, снова производится оценка коэфф. – так до тех пор, пока не будет построена хорошая по стат. качествам модель. . Перерасчитывается модель регрессии, снова производится оценка коэфф. – так до тех пор, пока не будет построена хорошая по стат. качествам модель.
Метод всех возможных регрессий.
Строятся модели с различным кол-вом факториальных признаков: от 1 до во всех возможных сочетаниях, которые позволяет данный набор факторов. Все модели включ. в таблицу:
| модель |
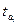 |
|
F |
Выбирается лучшая модель (все коэфф. значимы).
Временные ряды.
Метод среднего абсолютного отклонения.
Предназначен для прогнозирования на один год. Временной ряд 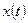 аппроксимируется функцией аппроксимируется функцией 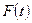 : :
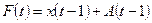 , , 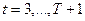 , ,
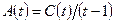 , ,
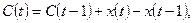 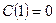 , прогнозное значение показателя Х в году Т+1 есть F(T+1). , прогнозное значение показателя Х в году Т+1 есть F(T+1).
Точность аппроксимации характеризуют: средняя абсолютная погрешность 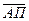 , средняя относительная погрешность , средняя относительная погрешность 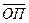 и среднеквадратическое отклонение S: и среднеквадратическое отклонение S:
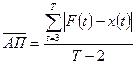 , , 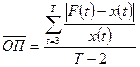 , , 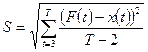 . .
Практически хорошим качеством аппроксимации считается в пределах 3-5%.
Метод экспоненциального сглаживания.
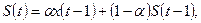 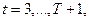 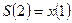 , - параметр, кот. подбирается эмпирически. , - параметр, кот. подбирается эмпирически.
Прогнозное значение показателя Х в году Т+1 есть S(t+1).
Метод скользящих средних.
Сущность метода состоит в укрупнении интервалов и определении средних для каждого укрупненного интервала:
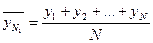 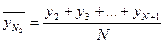 … … 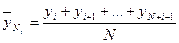 , где N – интервал усреднения, порядок средней скользящей; , где N – интервал усреднения, порядок средней скользящей; 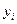 - уровни временного ряда; - уровни временного ряда; 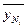 - скользящая средняя N-порядка. - скользящая средняя N-порядка.
Общая формула для средней скользящей:
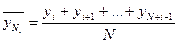 , , 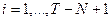 , где Т – общая длина сглаживаемого временного ряда, N– интервал сглаживания. , где Т – общая длина сглаживаемого временного ряда, N– интервал сглаживания.
Построение модели тренда.
1. Сбор и анализ данных.
1.1 На основе графического анализа данных выдвигается гипотеза о наличии понижательной или повышательной тенденции.
1.2 Данная гипотеза проверяется на основе критерия Кендела:
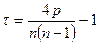 , где – число уровней ряда, , где – число уровней ряда, 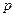 - число случаев, при которых - число случаев, при которых 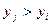 , , 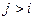 . + означает наличие возрастающего тренда, - падающего. . + означает наличие возрастающего тренда, - падающего.
Проверяется стат. значимость 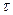 . . 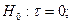 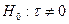 . Для этого находится: . Для этого находится:
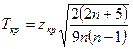 , где , где 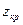 определяется по таблице функции Лапласа, определяется по таблице функции Лапласа, 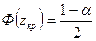 , где - уровень значимости (обычно 0,05). , где - уровень значимости (обычно 0,05).
Если 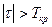 , то нулевую гипотезу отклоняют; , то нулевую гипотезу отклоняют;
Если 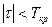 , то нет основания отклонить нулевую гипотезу. , то нет основания отклонить нулевую гипотезу.
Выбор наилучшей кривой осуществляется: а) на основе следующего критерия:
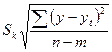 , m – число параметров функции тренда, n– число наблюдений. Та функция, для кот. Sбудет меньше, считается лучшей. , m – число параметров функции тренда, n– число наблюдений. Та функция, для кот. Sбудет меньше, считается лучшей.
б) Используется также коэфф. Тейла:
 . Чем меньше, тем лучше функция. . Чем меньше, тем лучше функция.
Модели временных рядов с периодической компонентой.
В этих моделях временной ряд разлагается на три компоненты:
тренд – Т, сезонную компоненту Sи случайную компоненту или погрешность – Е. В аддитивных моделях уровни временного ряда представлены как сумма этих компонент – 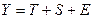 , а в мультипликативных моделях как произведение компонент - , а в мультипликативных моделях как произведение компонент - 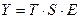 . .
Анализ модели с аддитивной компонентой.
1. Анализ данных.
Построение графика, вывод о возможности использования аддитивной модели.
| Период времени |
Объем экспорта |
Скользящая средняя |
Центрированная скользящая средняя |
Оценка сезонной компоненты |
| I квартал |
139 |
| II квартал |
101 |
| 129,75 |
| III квартал |
82 |
140,4 |
-58,4 |
| 151 |
| IV квартал |
197 |
160,6 |
+36,4 |
| 170,25 |
| I квартал |
224 |
179,6 |
+44,4 |
| 189 |
| II квартал |
178 |
199,9 |
-21,9 |
| 210,75 |
| III квартал |
157 |
| IV квартал |
284 |
2. Расчет сезонной компоненты.
2.1 Расчет скользящей средней с шагом 4.
2.2 Центрирование скользящей средней.
2.3 Определение сезонной компоненты: 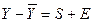 . .
2.4 Расчет средних значений сезонной компоненты по кварталам.
2.5 Корректировка средних значений сезонной компоненты.
3. Определение тренда.
| Период времени |
Год
|
Квартал |
| I |
II |
III |
IV |
| 1 |
- |
- |
-54,8 |
+36,4 |
| 2 |
+44,4 |
-21,9 |
-63,4 |
+43,8 |
| 3 |
+40,8 |
-19,8 |
-64,5 |
- |
| Итого: |
+82,5 |
-41,7 |
-186,3 |
+80,2 |
| Оценка сезонной компоненты |
+42,6 |
-20,8 |
-62,1 |
+40,1 |
| Сумма сезонных компонент |
-0,2 |
| Скорректированная сезонная компонента |
+42,6 |
-20,7 |
-62,0 |
+40,1 |
| Сумма скорректированных сезонных компонент |
0 |
3.1 Десезонализация данных: от всех уровней ряда вычитают соотв. знач-е скорр. сезонной компоненты, получают значения, содержащие тренд и случайную компоненту: 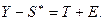
| Период времени |
Объем экспорта |
Скорректированная сезонная компонента |
Десезонализированный объем экспорта |
| I |
139 |
+42.6 |
96.4 |
| II |
101 |
-20.7 |
121.7 |
| III |
82 |
-62.0 |
144.0 |
| IV |
197 |
+40.1 |
156.9 |
| Период времени |
Объем экспорта Y |
Сезонная компонента S |
Трендовое значение T |
Ошибка Y-S-T=E |
| I квартал |
139 |
+42,6 |
100,6 |
-4,2 |
| II квартал |
101 |
-20,7 |
120,5 |
+1,2 |
| III квартал |
82 |
-62,0 |
140,4 |
+4,4 |
| IV квартал |
197 |
+40,1 |
160,3 |
-3,4 |
3.2 Построение модели тренда методом наименьших квадратов на основе десезонализированных данных.
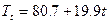
4. Определение качества модели и расчет ошибок.
Ошибки должны составлять небольшую долю.
5. Построение прогноза с учетом сезонных колебаний.
Сначала рассчитывается прогноз по модели тренда, а затем проводится корректировка прогноза на сезонную компоненту.
На IIквартал 4 года: по прогнозу: 8,07+19,9*14=359; скорректированное знач-е: 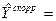 359-20,7=338,3. 359-20,7=338,3.
Анализ модели с мультипликативной компонентой.
1. Анализ данных.
Построение графика и вывод о необходимости использовать модель с мультипликативной компонентой.
2. Расчет сезонной компоненты.
2.1 Расчет сезонной средней с шагом 4.
2.2 Центрирование скользящей средней.
2.3 Определение коэфф. сезонности путем деления уровней ряда на значение центрированной скользящей средней за соответствующий момент времени.
| Период времени |
Объем закупок |
Скользящая средняя за 4 квартала |
Центрированная скользящая средняя |
Коэфф. сезонности |
| I квартал |
140 |
| II квартал |
132 |
| 136 |
| III квартал |
130 |
138,25 |
0,940 |
| 140,5 |
| IV квартал |
142 |
| I квартал |
158 |
2.4 Расчет средних значений коэфф. сезонности по кварталам.
| Период времени |
Год
|
Квартал |
| I |
II |
III |
IV |
| 1 |
- |
- |
0,940 |
1,011 |
| 2 |
1,121 |
0,915 |
0,904 |
1,092 |
| 3 |
1,103 |
0,892 |
0,909 |
- |
| Итого: |
2,224 |
1,807 |
2,753 |
2,103 |
| Оценка сезонной компоненты |
1,112 |
0,903 |
0,918 |
1,051 |
| Сумма сезонных компонент |
3,984 |
| Скорректированная сезонная компонента |
1,116 |
0,907 |
0,922 |
1,055 |
| Сумма скорректированных сезонных компонент |
4 |
2.5 Корректировка средних значений коэфф. сезонности (сумма оценок сезонной компоненты должна равняться 4, в противном случае производится корректировка.)
3. Определение тренда.
3.1 Десезонализация данных путем деления фактич. знач-ий ряда на скор. коэфф. сезонности за соотв. квартал.
| Период времени |
Объем закупок |
Коэфф. сезонности |
Десезонализированный объем  |
| I |
140 |
1,116 |
125,4 |
| II |
132 |
0,907 |
145,6 |
| III |
130 |
0,922 |
141,2 |
| IV |
142 |
1,055 |
134,3 |
3.2 Построение модели тренда на основе десезонализированных данных методом МНК.
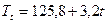
| Квартал |
Объем закупок Y |
Сезонная компонента S |
Трендовое значение Т |
Ошибка |
| T*S |
E |
| I |
140 |
1,116 |
129 |
143,9 |
0,97 |
| II |
132 |
0,907 |
132,2 |
119,9 |
1,1 |
| III |
130 |
0,922 |
135,4 |
124,8 |
1,04 |
| IV |
142 |
1,055 |
138,6 |
146,2 |
0,97 |
4. Определение качества модели и расчет ошибок. Ошибки должны быть невелики.
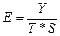 . .
5. Построение прогноза с учетом сезонных колебаний.
5.1 Расчет прогнозных значений на основе тренда. Для II квартала 4 года: Т=128,5+3,2*14
5.2 Корректировка сезонных значений с учетом коэфф. сезонности: (128,5+3,2*14)*0,907=157,6.
|