Основные данные о работе
| Версия шаблона | 1.1 | | Филиал | Новороссийский филиал | | Вид работы | Курсовая работа | | Название дисциплины | Базы данных | | Тема | Транзакции | | Фамилия студента | Кушнир | | Имя студента | Елена | | Отчество студента | Владимировна | | № контракта | 00900080609041 |
Содержание
ВВЕДЕНИЕ 3 1. ТРАНЗАКЦИИ 4 1.1 Свойства транзакций. Способы завершения транзакций 4 1.2 Журнал транзакций. Журнализация и буферизация 8 1.3 Индивидуальный откат транзакции. Восстановление после мягкого сбоя 13 1.4 Физическая согласованность базы данных. Восстановление после жесткого сбоя 15 1.5 Параллельное выполнение транзакций. Уровни изолированности пользователей 19 2. ТРАНЗАКЦИИ В MICROSOFT SQL SERVER 2000 32 2.1 Поведение параллельных транзакций в Microsoft SQL Server 32 2.2 Режимы транзакций в SQL Server 35 2.3 Фиксирование транзакций 37 2.4 Создание вложенных транзакций в SQL Server 38 2.5 Откаты транзакций в SQL Server 40 2.6 Блокировка транзакций в SQL Server 44 Заключение 50 ГЛОССАРИЙ 53 Список использованных источников 54 Приложение А Схема журнала транзакций 55
Введение
Актуальность данного исследование обусловлено необходимостью обработки большого количества баз данных в различных отраслях. Целью данной работы является рассмотрение технологии работы с транзакциями, а так же работу транзакций в Microsoft SQL Server 2000. Объектом исследования являются транзакции. Предметом исследования являются характеристики транзакций, ее основные свойства, режимы, откаты и блокировки. Реализация поставленной цели потребовало решения ряда конкретных задач, а именно: Рассмотреть принцип создания и работы транзакции; Рассмотреть свойства транзакций; Рассмотреть технологию применения транзакций в SQL Server 2000. Транзакцией называется последовательность операций, производимых над базой данных и переводящих базу данных из одного непротиворечивого (согласованного) состояния в другое непротиворечивое (согласованное) состояние. Транзакция рассматривается как некоторое неделимое действие над базой данных, осмысленное с точки зрения пользователя. В то же время это логическая единица работы системы. Что может быть названо транзакцией? Кем определяется, какая последовательность операций над базой данных составляет транзакцию? Конечно, однозначно именно разработчик определяет, какая последовательность операций составляет единое целое, то есть транзакцию. Разработчик приложений или хранимых процедур определяет это исходя из смысла обработки данных, именно семантика совокупности операций над базой данных, которая моделирует с точки зрения разработчика некоторую одну неразрывную работу, и составляет транзакцию. Допустим, выделим работу по вводу данных о поступивших книгах, новых книгах, которых не было раньше в библиотеке. Тогда эту операцию можно разбить на две последовательные: сначала ввод данных о книге — это новая строка в таблице BOOKS, а потом ввод данных обо всех экземплярах новой книги — это ввод набора новых строк в таблицу EXEMPLAR в количестве, равном количеству поступивших экземпляров книги. Если эта последовательность работ будет прервана, то наша база данных не будет соответствовать реальному объекту, поэтому желательно выполнять ее как единую работу над базой данных.[3] Перспективы. Краткосрочные: - Рост числа продуктов, поддерживающих развитые модели транзакций
(вложенных и/или многозвенных). - Формализация спецификаций X/Open DTP и реализация совместимых с ними продуктов. Долгосрочные: - Появление коммерческих версий мониторов TP третьего поколения, интегрированных с дисциплиной потоков работ, с поддержкой долговременных транзакций и других прогрессивных средств.
1. Транзакции 1.1 Свойства транзакций. Способы завершения транзакций
Существуют различные модели транзакций, которые могут быть классифицированы на основании различных свойств, включающих структуру транзакции, параллельность внутри транзакции, продолжительность и т. д. В настоящий момент выделяют следующие типы транзакций: плоские или классические транзакции, цепочечные транзакции и вложенные транзакции. Плоские, или традиционные транзакции, характеризуются четырьмя классическими свойствами: атомарности, согласованности, изолированности, долговечности (прочности) — ACID (Atomicity, Consistency, Isolation, Durability). Иногда традиционные транзакции называют ACID-транзакциями. Упомянутые выше свойства означают следующее: Свойство атомарности (Atomicity) выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе. Свойство согласованности (Consistency) гарантирует, что по мере выполнения транзакций данные переходят из одного согласованного состояния в другое — транзакция не разрушает взаимной согласованности данных. Свойство изолированности (Isolation) означает, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно. Свойство долговечности (Durability) трактуется следующим образом: если транзакция завершена успешно, то те изменения в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок). [1] Возможны два варианта завершения транзакции. Если все операторы выполнены успешно и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, транзакция фиксируется. Фиксация транзакции — это действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. До тех пор пока транзакция не зафиксирована, допустимо аннулирование этих изменений, восстановление базы данных в то состояние, в котором она была на момент начала транзакции. Фиксация транзакции означает, что все результаты выполнения транзакции становятся постоянными. Они станут видимыми другим транзакциям только после того, как текущая транзакция будет зафиксирована. До этого момента все данные, затрагиваемые транзакцией, будут "видны" пользователю в состоянии на начало текущей транзакции. Если в процессе выполнения транзакции случилось нечто такое, что делает невозможным ее нормальное завершение, база данных должна быть возвращена в исходное состояние. Откат транзакции — это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции. В стандарте ANSI/ISO SQL определены модель транзакций и функции операторов COMMIT и ROLLBACK. Стандарт определяет, что транзакция начинается с первого SQL-оператора, инициируемого пользователем или содержащегося в программе, изменяющего текущее состояние базы данных. Все последующие SQL-операторы составляют тело транзакции. [8]Транзакция завершается одним из четырех возможных путей (рисунок 1.1). 
Рисунок 1.1 Модель транзакций ANSI/ISO Оператор COMMIT означает успешное завершение транзакции; его использование делает постоянными изменения, внесенные в базу данных в рамках текущей транзакции; Оператор ROLLBACK прерывает транзакцию, отменяя изменения, сделанные в базе данных в рамках этой транзакции; новая транзакция начинается непосредственно после использования ROLLBACK; Успешное завершение программы, в которой была инициирована текущая транзакция, означает успешное завершение транзакции (как будто был использован оператор COMMIT); Ошибочное завершение программы прерывает транзакцию (как будто был использован оператор ROLLBACK). В этой модели каждый оператор, который изменяет состояние БД, рассматривается как транзакция, поэтому при успешном завершении этого оператора БД переходит в новое устойчивое состояние.[16] В первых версиях коммерческих СУБД была реализована модель транзакций ANSI/ISO. В дальнейшем в СУБД SYBASE была реализована расширенная модель транзакций, которая включает еще ряд дополнительных операций. В модели SYBASE используются следующие четыре оператора: Оператор BEGIN TRANSACTION сообщает о начале транзакции. В отличие от модели в стандарте ANSI/ISO, где начало транзакции неявно задается первым оператором модификации данных, в модели SYBASE начало транзакции задается явно с помощью оператора начала транзакции. Оператор COMMIT TRANSACTION сообщает об успешном завершении транзакции. Он эквивалентен оператору COMMIT в модели стандарта ANSI/ISO. Этот оператор, как и оператор COMMIT, фиксирует все изменения, которые производились в БД в процессе выполнения транзакции. Оператор SAVE TRANSACTION создает внутри транзакции точку сохранения, которая соответствует промежуточному состоянию БД, сохраненному на момент выполнения этого оператора. В операторе SAVE TRANSACTION может стоять имя точки сохранения. Поэтому в ходе выполнения транзакции может быть запомнено несколько точек сохранения, соответствующих нескольким промежуточным состояниям. Оператор ROLLBACK имеет две модификации. Если этот оператор используется без дополнительного параметра, то он интерпретируется как оператор отката всей транзакции, то есть в этом случае он эквивалентен оператору отката ROLLBACK в модели ANSI/ISO. Если же оператор отката имеет параметр и записан в виде ROLLBACK B, то он интерпретируется как оператор частичного отката транзакции в точку сохранения B. Конечно, расширенная модель транзакции, предложенная фирмой SYBASE, поддерживает гораздо более гибкий механизм выполнения транзакций. Точки сохранения позволяют устанавливать маркеры внутри транзакции таким образом, чтобы имелась возможность отмены только части работы, проделанной в транзакции. Целесообразно использовать точки сохранения в длинных и сложных транзакциях, чтобы обеспечить возможность отмены изменения для определенных операторов. Однако это обусловливает дополнительные затраты ресурсов системы — оператор выполняет работу, а изменения затем отменяются; обычно усовершенствования в логике обработки могут оказаться более оптимальным решением.[10] 1.2 Журнал транзакций. Журнализация и буферизация
Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая журналом транзакций. Однако назначение журнала транзакций гораздо шире. Он предназначен для обеспечения надежного хранения данных в БД. А это требование предполагает, в частности, возможность восстановления согласованного состояния базы данных после любого рода аппаратных и программных сбоев. Очевидно, что для выполнения восстановлений необходима некоторая дополнительная информация. В подавляющем большинстве современных реляционных СУБД такая избыточная дополнительная информация поддерживается в виде журнала изменений базы данных, чаще всего называемого журналом транзакций. Общей целью журнализации изменений баз данных является обеспечение возможности восстановления согласованного состояния базы данных после любого сбоя. Поскольку основой поддержания целостного состояния базы данных является механизм транзакций, журнализация и восстановление тесно связаны с понятием транзакции. Общими принципами восстановления являются следующие: результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных; результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных. Это, собственно, и означает, что восстанавливается последнее по времени согласованное состояние базы данных.[2] Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных. Индивидуальный откат транзакции. Этот откат должен быть применен в следующих случаях: стандартной ситуацией отката транзакции является ее явное завершение оператором ROLLBACK; аварийное завершение работы прикладной программы, которое логически эквивалентно выполнению оператора ROLLBACK, но физически имеет иной механизм выполнения; принудительный откат транзакции в случае взаимной блокировки при параллельном выполнении транзакций. В подобном случае для выхода из тупика данная транзакция может быть выбрана в качестве "жертвы" и принудительно прекращено ее выполнение ядром СУБД. Восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой). Такая ситуация может возникнуть в следующих случаях: при аварийном выключении электрического питания; при возникновении неустранимого сбоя процессора (например, срабатывании контроля оперативной памяти) и т. д. Ситуация характеризуется потерей той части базы данных, которая к моменту сбоя содержалась в буферах оперативной памяти. Восстановление после поломки основного внешнего носителя базы данных (жесткий сбой). Эта ситуация при достаточно высокой надежности современных устройств внешней памяти может возникать сравнительно редко, но тем не менее СУБД должна быть в состоянии восстановить базу данных даже и в этом случае. Основой восстановления является архивная копия и журнал изменений базы данных. [15] Для восстановления согласованного состояния базы данных при индивидуальном откате транзакции нужно устранить последствия операторов модификации базы данных, которые выполнялись в этой транзакции. Для восстановления непротиворечивого состояния БД при мягком сбое необходимо восстановить содержимое БД по содержимому журналов транзакций, хранящихся на дисках. Для восстановления согласованного состояния БД при жестком сбое надо восстановить содержимое БД по архивным копиям и журналам транзакций, которые хранятся на неповрежденных внешних носителях.[17] Во всех трех случаях основой восстановления является избыточное хранение данных. Эти избыточные данные хранятся в журнале, содержащем последовательность записей об изменении базы данных. Возможны два основных варианта ведения журнальной информации. В первом варианте для каждой транзакции поддерживается отдельный локальный журнал изменений базы данных этой транзакцией. Такие журналы называются локальными журналами. Они используются для индивидуальных откатов транзакций и могут поддерживаться в виртуальной памяти. Кроме того, поддерживается общий журнал изменений базы данных, используемый для восстановления состояния базы данных после мягких и жестких сбоев. Этот подход позволяет быстро выполнять индивидуальные откаты транзакций, но приводит к дублированию информации в локальных и общем журналах. Поэтому чаще используется второй вариант — поддержание только общего журнала изменений базы данных, который используется и при выполнении индивидуальных откатов. Далее мы рассматриваем именно этот вариант. Общая структура журнала условно может быть представлена в виде некоторого последовательного файла, в котором фиксируется каждое изменение БД, которое происходит в ходе выполнения транзакции. Все транзакции имеют свои внутренние номера, поэтому в едином журнале транзакций фиксируются все изменения, проводимые всеми транзакциями. Каждая запись в журнале транзакций помечается номером транзакции, к которой она относится, и значениями атрибутов, которые она меняет. Кроме того, для каждой транзакции в журнале фиксируется команда начала и завершения транзакции. (Приложение А) Для большей надежности журнал транзакций часто дублируется системными средствами коммерческих СУБД, именно поэтому объем внешней памяти во много раз превышает реальный объем данных, которые хранятся в хранилище. Имеются два альтернативных варианта ведения журнала транзакций: протокол с отложенными обновлениями и протокол с немедленными обновлениями. Ведение журнала по принципу отложенных изменений предполагает следующий механизм выполнения транзакций: Когда транзакция Т1 начинается, в протокол заносится запись <Т1 Begin transaction> На протяжении выполнения транзакции в протоколе для каждой изменяемой записи записывается новое значение: <T1,ID_RECORD, атрибут, новое значение … >. Здесь ID_RECORD — уникальный номер записи. Если все действия, из которых состоит транзакция Т1, успешно выполнены, то транзакция частично фиксируется и в протокол заносится <Т1 COMMIT>. После того как транзакция фиксирована, записи протокола, относящиеся к T1, используются для внесения соответствующих изменений в БД. Если происходит сбой, то СУБД просматривает протокол и выясняет, какие транзакции необходимо переделать. Транзакцию Т1 необходимо переделать, если протокол содержит обе записи <T1 BEGIN TRANSACTION> и <T1 COMMIT>. БД может находиться в несогласованном состоянии, однако все новые значения измененных элементов данных содержатся в протоколе, и это требует повторного выполнения транзакции. Для этого используется некоторая системная процедура REDO(), которая заменяет все значения элементов данных на новые, просматривая протокол в прямом порядке. Если в протоколе не содержится команда фиксации транзакции COMMIT, то никаких действий проводить не требуется, а транзакция запускается заново. [13] Альтернативный механизм с немедленным выполнением предусматривает внесение изменений сразу в БД, а в протокол заносятся не только новые, но и все старые значения изменяемых атрибутов, поэтому каждая запись выглядит <Т1, IDRECORD, атрибут новое значение старое значение …>. При этом запись в журнал предшествует непосредственному выполнению операции над БД. Когда транзакция фиксируется, то есть встречается команда <T1 COMMIT> и она выполняется, то все изменения оказываются уже внесенными в БД и не требуется никаких дальнейших действий по отношению к этой транзакции. При откате транзакции выполняется системная процедура UNDO(), которая возвращает все старые значения в отмененной транзакции, последовательно проходя по протоколу начиная с команды BEGIN TRANSACTION. Для восстановления при сбое используется следующий механизм: Если транзакция содержит команду начала транзакции, но не содержит команды фиксации с подтверждением ее выполнения, то выполняется последовательность действий как при откате транзакции, то есть восстанавливаются старые значения. Если сбой произошел после выполнения последней команды изменения БД, но до выполнения команды фиксации, то команда фиксации выполняется, а с БД никаких изменений не происходит. Работа происходит только на уровне протокола. Если бы запись об изменении базы данных, которая должна поступить в журнал при выполнении любой операции модификации базы данных, реально немедленно записывалась бы во внешнюю память, это привело бы к существенному замедлению работы системы. Поэтому записи в журнале тоже буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном заполнении записями.[9] Проблема не возникает при индивидуальных откатах транзакций, поскольку в этих случаях содержимое оперативной памяти не утрачено и можно пользоваться содержимым как буфера журнала, так и буферов страниц базы данных. Но если произошел мягкий сбой и содержимое буферов утрачено, для проведения восстановления базы данных необходимо иметь некоторое согласованное состояние журнала и базы данных во внешней памяти. Основным принципом согласованной политики выталкивания буфера журнала и буферов страниц базы данных является то, что запись об изменении объекта базы данных должна попадать во внешнюю память журнала раньше, чем измененный объект оказывается во внешней памяти базы данных. Соответствующий протокол журнализации (и управления буферизацией) называется Write Ahead Log (WAL) — "пиши сначала в журнал" и состоит в том, что если требуется записать во внешнюю память измененный объект базы данных, то перед этим нужно гарантировать запись во внешнюю память журнала транзакций записи о его изменении. Дополнительное условие на выталкивание буферов накладывается тем требованием, что каждая успешно завершившаяся транзакция должна быть реально зафиксирована во внешней памяти. Какой бы сбой не произошел, система должна быть в состоянии восстановить состояние базы данных, содержащее результаты всех зафиксированных к моменту сбоя транзакций. Простым решением было бы выталкивание буфера журнала, за которым следует массовое выталкивание буферов страниц базы данных, изменявшихся данной транзакцией. Довольно часто так и делают, но это вызывает существенные накладные расходы при выполнении операции фиксации транзакции. Оказывается, что минимальным требованием, гарантирующим возможность восстановления последнего согласованного состояния базы данных, является выталкивание при фиксации транзакции во внешнюю память журнала всех записей об изменении базы данных этой транзакцией. При этом последней записью в журнал, производимой от имени данной транзакции, является специальная запись о конце транзакции.[2] 1.3 Индивидуальный откат транзакции. Восстановление после мягкого сбоя Для того чтобы можно было выполнить по общему журналу индивидуальный откат транзакции, все записи в журнале по данной транзакции связываются в обратный список. Началом списка для незакончившихся транзакций является запись о последнем изменении базы данных, произведенном данной транзакцией. Для закончившихся транзакций (индивидуальные откаты которых уже невозможны) началом списка является запись о конце транзакции, которая обязательно вытолкнута во внешнюю память журнала. Концом списка всегда служит первая запись об изменении базы данных, произведенном данной транзакцией. Обычно в каждой записи проставляется уникальный идентификатор транзакции, чтобы можно было восстановить прямой список записей об изменениях базы данных данной транзакцией. Индивидуальный откат транзакции выполняется следующим образом: Выбирается очередная запись из списка данной транзакции. Выполняется противоположная по смыслу операция: вместо операции INSERT выполняется соответствующая операция DELETE, вместо операции DELETE выполняется INSERT и вместо прямой операции UPDATE обратная операция UPDATE, восстанавливающая предыдущее состояние объекта базы данных. Любая из этих обратных операций также заносится в журнал. Для индивидуального отката это не нужно, но при выполнении индивидуального отката транзакции может произойти мягкий сбой, при восстановлении после которого потребуется откатить такую транзакцию, для которой не полностью выполнен индивидуальный откат. При успешном завершении отката в журнал заносится запись о конце транзакции. С точки зрения журнала такая транзакция является зафиксированной. К числу основных проблем восстановления после мягкого сбоя относится то, что одна логическая операция изменения базы данных может изменять несколько физических блоков базы данных, например, страницу данных и несколько страниц индексов. Страницы базы данных буферизуются в оперативной памяти и выталкиваются независимо. Несмотря на применение протокола WAL, после мягкого сбоя набор страниц внешней памяти базы данных может оказаться несогласованным, то есть часть страниц внешней памяти соответствует объекту до изменения, часть — после изменения. К такому состоянию объекта неприменимы операции логического уровня. Состояние внешней памяти базы данных называется физически согласованным, если наборы страниц всех объектов согласованы, то есть соответствуют состоянию объекта, либо до его изменения, либо после изменения. В журнале отмечаются точки физической согласованности базы данных — моменты времени, в которые во внешней памяти содержатся согласованные результаты операций, завершившихся до соответствующего момента времени, и отсутствуют результаты операций, которые не завершились, а буфер журнала вытолкнут во внешнюю память. Тогда к моменту мягкого сбоя возможны следующие состояния транзакций: транзакция успешно завершена, то есть, выполнена операция подтверждения транзакции COMMIT и для всех операций транзакции получено подтверждение ее выполнения во внешней памяти; транзакция успешно завершена, но для некоторых операций не получено подтверждение их выполнения во внешней памяти; транзакция получила и выполнила команду отката ROLLBACK; транзакция не завершена.[12]
1.4 Физическая согласованность базы данных. Восстановление после жесткого сбоя
При открытии файла таблица отображения номеров его логических блоков в адреса физических блоков внешней памяти считывается в оперативную память. При модификации любого блока файла во внешней памяти выделяется новый блок. При этом текущая таблица отображения (в оперативной памяти) изменяется, а теневая — сохраняется неизменной. Если во время работы с открытым файлом происходит сбой, во внешней памяти автоматически сохраняется состояние файла до его открытия. Для явного восстановления файла достаточно повторно считать в оперативную память теневую таблицу отображения.  Рисунок 1.2 - Использование теневых таблиц отображения информации В контексте базы данных теневой механизм используется следующим образом. (Рисунок 1.2) Периодически выполняются операции установления точки физической согласованности базы данных (checkpoints). Для этого все логические операции завершаются, все буферы оперативной памяти, содержимое которых не соответствует содержимому соответствующих страниц внешней памяти, выталкиваются. Теневая таблица отображения файлов базы данных заменяется на текущую.[11] Восстановление происходит мгновенно: текущая таблица отображения заменяется на теневую. Все проблемы восстановления решаются, но за счет слишком большого перерасхода внешней памяти. В пределе может потребоваться вдвое больше внешней памяти, чем реально нужно для хранения базы данных. Теневой механизм — это надежное, но слишком грубое средство. Обеспечивается согласованное состояние внешней памяти в один общий для всех объектов момент времени. На самом деле достаточно иметь совокупность согласованных наборов страниц, каждому из которых может соответствовать свои временные отсчеты. Для выполнения такого более слабого требования наряду с логической журнализацией операций изменения базы данных производится журнализация постраничных изменений. Первый этап восстановления после мягкого сбоя состоит в постраничном откате незакончившихся логических операций, как это делается с логическими записями по отношению к транзакциям, последней записью о постраничных изменениях от одной логической операции является запись о конце операции. В этом подходе имеются два метода решения проблемы. При использовании первого метода поддерживается общий журнал логических и страничных операций. Наличие двух видов записей, интерпретируемых абсолютно по-разному, усложняет структуру журнала. Записи о постраничных изменениях, актуальность которых носит локальный характер, существенно увеличивают журнал. Поэтому все более популярным становится поддержание отдельного журнала постраничных изменений. Такая техника применяется, например, в известном продукте Informix Online. Некоторым способом удалось восстановить внешнюю память базы данных к состоянию на момент времени tpc. Тогда: Для транзакции T1 никаких действий производить не требуется. Она закончилась до момента tpc, и все ее результаты отражены во внешней памяти базы данных. Для транзакции T2 нужно повторно выполнить оставшуюся часть операций (redo). Действительно, во внешней памяти полностью отсутствуют следы операций, которые выполнялись в транзакции T2 после момента tpc. Следовательно, повторная прямая интерпретация операций T2 корректна и приведет к логически согласованному состоянию базы данных. Для транзакции T3 нужно выполнить в обратном направлении первую часть операций (undo). Действительно, во внешней памяти базы данных полностью отсутствуют результаты операций T3, которые были выполнены после момента tpc. С другой стороны, во внешней памяти гарантированно присутствуют результаты операций T3, которые были выполнены до момента tpc. Следовательно, обратная интерпретация операций T3 корректна и приведет к согласованному состоянию базы данных (поскольку транзакция T3 не завершилась к моменту мягкого сбоя, при восстановлении необходимо устранить все последствия ее выполнения). Для транзакции T4, которая успела начаться после момента tpc и закончиться до момента мягкого сбоя, нужно выполнить полную повторную прямую интерпретацию операций (redo). Наконец, для начавшейся после момента tpc и не успевшей завершиться к моменту мягкого сбоя транзакции T5 никаких действий предпринимать не требуется. Результаты операций этой транзакции полностью отсутствуют во внешней памяти базы данных.[14] Понятно, что для восстановления последнего согласованного состояния базы данных после жесткого сбоя журнала изменений базы данных явно недостаточно. Основой восстановления в этом случае являются журнал и архивная копия базы данных. Восстановление начинается с обратного копирования базы данных из архивной копии. Затем для всех закончившихся транзакций выполняется redo, то есть операции повторно выполняются в прямом порядке. Более точно, происходит следующее: по журналу в прямом направлении выполняются все операции; для транзакций, которые не закончились к моменту сбоя, выполняется откат. На самом деле, поскольку жесткий сбой не сопровождается утратой буферов оперативной памяти, можно восстановить базу данных до такого уровня, чтобы можно было продолжить даже выполнение незакончившихся транзакций. Но обычно это не делается, потому, что восстановление после жесткого сбоя — это достаточно длительный процесс. Самый простой способ — архивировать базу данных при переполнении журнала. В журнале вводится так называемая "желтая зона", при достижении которой образование новых транзакций временно блокируется. Когда все транзакции закончатся и, следовательно, база данных придет в согласованное состояние, можно производить ее архивацию, после чего начинать заполнять журнал заново. Можно выполнять архивацию базы данных реже, чем переполняется журнал. При переполнении журнала и окончании всех начатых транзакций можно архивировать сам журнал. Поскольку такой архивированный журнал, по сути дела, требуется только для воссоздания архивной копии базы данных, журнальная информация при архивации может быть существенно сжата. [10]
1.5 Параллельное выполнение транзакций. Уровни изолированности пользователей
Если с БД работают одновременно несколько пользователей, то обработка транзакций должна рассматриваться с новой точки зрения. В этом случае СУБД должна не только корректно выполнять индивидуальные транзакции и восстанавливать согласованное состояние БД после сбоев, но она призвана обеспечить корректную параллельную работу всех пользователей над одними и теми же данными. По теории каждый пользователь и каждая транзакция должны обладать свойством изолированности, то есть они должны выполняться так, как если бы только один пользователь работал с БД. И средства современных СУБД позволяют изолировать пользователей друг от друга именно таким образом. Однако в этом случае возникают проблемы замедления работы пользователей. Рассмотрим более подробно проблемы, которые возникают при параллельной обработке транзакций. Основные проблемы, которые возникают при параллельном выполнении транзакций, делятся условно на 4 типа: Пропавшие изменения. Эта ситуация может возникать, если две транзакции одновременно изменяют одну и ту же запись в БД. Например, работают два оператора на приеме заказов, первый оператор принял заказ на 30 мониторов. Когда он запрашивал склад, то там числилось 40 мониторов, и он, получив подтверждение от клиента, выставил счет и оформил продажу 30 мониторов из 40. Параллельно с ним работает второй оператор, который принимает заказ на 20 таких же мониторов (ну уж очень хорошая модель и дешево) и, в свою очередь запросив состояние склада и получив исходно ту же цифру 40, он успешно оформляет заказ для своего клиента. Заканчивая работу с данным заказом, он выполняет команду Обновить(UPDATE), которая заносит 20 как остаток любимых мониторов на складе. Но после этого, наконец, любезно попрощавшись со своим клиентом и заверив его в скорейшей доставке заказанных мониторов, заканчивает работу со своим заказом первый оператор и также выполняет команду Обновитьи заносит 10 как остаток тех же мониторов на складе. Каждый из них доволен своей работой, но мы-то знаем, что произошло. Прежде всего, они продали 50 мониторов из наличествующих 40 штук, и далее на складе еще числится 10 подобных мониторов. БД теперь находится в несогласованном состоянии, а у фирмы возникли серьезные проблемы. Изменения, сделанные вторым оператором, были проигнорированы программой выполнения заказа, с которой работал первый оператор. Подобная ситуация представлена на рисунке 1.3.  Рисунок 1.3 - Проблема пропавших обновлений Проблемы промежуточных данных. Рассмотрим ту же проблему одновременной работы двух операторов. Допустим, первый оператор, ведя переговоры со своим заказчиком, ввел заказанные 30 мониторов, но перед окончательным оформлением заказа клиент захотел выяснить еще некоторые характеристики товара. Приложение, с которым работает первый оператор, уже изменило остаток мониторов на складе, и там сейчас находится информация о 10 оставшихся мониторах. В это время второй оператор пытается принять заказ от своего клиента на 20 мониторов, но его приложение показывает, что на складе осталось всего 10 мониторов, и оператор вынужден отказать выгодному клиенту, который идет в другую фирму, весьма неудовлетворенный работой нашей компании. А в этот момент клиент оператора 1 заканчивает обсуждение дополнительных характеристик наших мониторов и принимает весьма невыгодное решение не покупать у нас мониторы, и приложение оператора 1 выполняет откат транзакции, и на складе снова оказывается 40 мониторов. Мы потеряли выгодного заказчика, но еще хуже было бы, если бы клиент второго оператора согласился на 10 оставшихся мониторов, и приложение, с которым работает оператор два, отработав свой алгоритм, занесло 0 (ноль) оставшихся мониторов на складе, а после этого приложение оператора один снова бы записало исходные 40 мониторов на складе, хотя 10 их них уже проданы. Такая ситуация оказалась возможной потому, что приложение второго оператора имело доступ к промежуточным данным, которые сформировало первое приложение. Проблемы несогласованных данных. Рассмотрю ту же самую ситуацию с заказом мониторов. Предположу, что ситуация несколько изменилась. И оба оператора начинают работать практически одновременно. Они оба получают начальное состояние склада 40 мониторов, а далее первый оператор успешно завершает переговоры со своим клиентом и продает ему 30 мониторов. Он завершает работу своего приложения, и оно выполняет команду фиксации транзакции COMMIT. Состояние базы данных непротиворечивое. В этот момент, выяснив все тонкости и характеристики наших мониторов, клиент второго оператора также решает сделать заказ, и второй оператор, повторно получая состояние склада, видит, что оно изменилось. База данных находится в непротиворечивом состоянии, но второй оператор считает, что нарушена целостность его транзакции, в течение выполнения одной работы он получил два различных состояния склада. Эта ситуация возникла потому, что приложение первого оператора смогло изменить кортеж с данными, который уже прочитало приложение второго оператора. Проблемы строк-призраков (строк-фантомов). Администратор нашей фирмы поручил секретарю напечатать итоговый отчет по результатам работы за текущий месяц. И допустим, что приложение печатает отчет в двух видах: в подробном и в укрупненном. В момент, когда приложение печати начало формировать свой первый вид отчета, один из операторов принимает еще один заказ, поэтому к моменту формирования укрупненного отчета в БД появились новые сведения о продажах, которые и были внесены в укрупненный отчет. Мы получили два отчета в одном приложении, которые содержат разные цифры и не совпадают друг с другом. Такое стало возможно потому, что приложение печати выполнило два одинаковых запроса и получило два разных результата. БД находится в согласованном состоянии, но приложение печати работает некорректно. [6] Для поддержки параллельной работы транзакций строится специальный план. План (способ) выполнения набора транзакций называется сериальным, если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций. Самым простым было бы последовательное выполнение транзакций, но такой план не оптимален по времени, существуют более гибкие методы управления параллельным доступом к БД. Наиболее распространенным механизмом, который используется коммерческими СУБД для реализации на практике сериализации транзакций является механизм блокировок. Самый простой вариант — это блокировка объекта на все время действия транзакции. Здесь две транзакции, названные условно А и В, работают с тремя таблицами: Т1, Т2 и Т3. В момент начала работы с любым объектом этот объект блокируется транзакцией, которая с ним начала работу, и он становится недоступным всем другим транзакциям до окончания транзакции, заблокировавшей ("захватившей") данный объект. После окончания транзакции все заблокированные ею объекты разблокируются и становятся доступными другим транзакциям. Если транзакция обращается к заблокированному объекту, то она остается в состоянии ожидания до момента разблокировки этого объекта, после чего она может продолжать обработку данного объекта. Поэтому транзакция. В ожидает разблокировки таблицы Т2 транзакцией А. Над прямоугольниками стоит условное время выполнения операций. (Рисунок 1.4) 
Рисунок 1.4 Блокировки при одновременном выполнении двух транзакций
В общем случае на момент выполнения транзакция получает как бы монопольный доступ к объектам БД, с которыми она работает. В этом случае другие транзакции не получают доступа к объектам БД до момента окончания транзакции. Такой механизм действительно ликвидирует все перечисленные ранее проблемы: пропавшие изменения, неподтвержденные данные, несогласованные данные, строки-фантомы. Однако такая блокировка создает новые проблемы — задержку выполнения транзакций из-за блокировок.[5] Рассмотрим существующие типы конфликтов между двумя параллельными транзакциями. Можно выделить следующие типы: W-W — транзакция 2 пытается изменять объект, измененный незакончившейся транзакцией 1; R-W — транзакция 2 пытается изменять объект, прочитанный незакончившейся транзакцией 1; W-R — транзакция 2 пытается читать объект, измененный незакончившейся транзакцией 1. Практические методы сериализации транзакций основываются на учете этих конфликтов. Блокировки, называемые также синхронизационными захватами объектов, могут быть применены к разному типу объектов. Наибольшим объектом блокировки может быть вся БД, однако этот вид блокировки сделает БД недоступной для всех приложений, которые работают с данной БД. Следующий тип объекта блокировки — это таблицы. Транзакция, которая работает с таблицей, блокирует ее на все время выполнения транзакции. Именно такой вид блокировки рассмотрен в таблице 1. Этот вид блокировки предпочтительнее предыдущего, потому что позволяет параллельно выполнять транзакции, которые работают с другими таблицами. В ряде СУБД реализована блокировка на уровне страниц. В этом случае СУБД блокирует только отдельные страницы на диске, когда транзакция обращается к ним. Этот вид блокировки еще более мягок и позволяет разным транзакциям работать даже с одной и той же таблицей, если они обращаются к разным страницам данных. Для повышения параллельности выполнения транзакций используется комбинирование разных типов синхронизационных захватов. Рассматривают два типа блокировок (синхронизационных захватов): совместный режим блокировки — нежесткая, или разделяемая, блокировка, обозначаемая как S(Shared). Этот режим обозначает разделяемый захват объекта и требуется для выполнения операции чтения объекта. Объекты, заблокированные таким образом, не изменяются в ходе выполнения транзакции и доступны другим транзакциям также, но только в режиме чтения; монопольный режим блокировки — жесткая, или эксклюзивная, блокировка, обозначаемая как X(eXclusive). Данный режим блокировки предполагает монопольный захват объекта и требуется для выполнения операций занесения, удаления и модификации. Объекты, заблокированные данным типом блокировки, фактически остаются в монопольном режиме обработки и недоступны для других транзакций до момента окончания работы данной транзакции. Захваты объектов несколькими транзакциями по чтению совместимы, то есть нескольким транзакциям допускается читать один и тот же объект, захват объекта одной транзакцией по чтению не совместим с захватом другой транзакцией того же объекта по записи, и захваты одного объекта разными транзакциями по записи не совместимы. Правила совместимости захватов одного объекта разными транзакциями изображены в таблице 1.1. Таблица 1.1 - Правила применения жесткой и нежесткой блокировок транзакций 
Таблица 1.2 Перечень действий множества транзакций | Время | Транзакция | Действие | | 0 | T1 | Select A | | 1 | T2 | Select B | | 2 | T1 | Select C | | 3 | T4 | Select D | | 4 | T5 | Select A | | 5 | T2 | Select E | | 6 | T2 | Update E | | 7 | T3 | Select F | | 8 | T2 | Select F | | 9 | T5 | Update A | | 10 | T1 | Commit | | 11 | T6 | Select A | | 12 | T5 | Commit | | 13 | T6 | Select C | | 14 | T6 | Update C | | 15 | T7 | Select G | | 16 | T8 | Select H | | 17 | T9 | Select G | | 18 | T9 | Update G | | 19 | T8 | Select E | | 20 | T7 | Commit | | 21 | T9 | Select H | | 22 | T3 | Select G | | 23 | T10 | Select A | | 24 | T9 | Update H | | 25 | T6 | Commit | | 26 | T11 | Select C | | 27 | T12 | Select D | | 28 | T12 | Select C | | 29 | T2 | Update F | | 30 | T11 | Update C | | 31 | T12 | Select A | | 32 | T10 | Update A | | 33 | T12 | Update D | | 34 | T2 | Select G | | 35 | - | - |
В примере, представленном в таблице 1 считается, что первой блокирует объект транзакция А, а потом пытается получить к нему доступ транзакция В. На рисунке 1.5 приведен ранее рассмотренный пример с выполнением транзакций 1 и 2, но с учетом разных типов блокировки. На рисунке видно, что, применив нежесткую блокировку к таблице 2 со стороны транзакции 1, мы обеспечили существенное уменьшение времени выполнения транзакции 2. Теперь транзакция 2 не ждет окончания транзакции 1, и поэтому завершает свою работу, намного раньше.  Рисунок 1.5 - Использование жесткой и нежесткой блокировки
К сожалению, применения разных типов блокировок приводит к проблеме тупиков. Проблема тупиков возникла при рассмотрении выполнения параллельных процессов в операционных средах и также была связана с управлением разделяемыми (совместно используемыми) ресурсами. Пример. Пусть транзакция А сначала жестко блокирует таблицу 1, а потом жестко блокирует таблицу 2. Транзакция B, наоборот, сначала жестко блокирует таблицу 2, а потом жестко блокирует таблицу 1. Если обе эти транзакции начали работу одновременно, то после выполнения операций модификации первыми объектами каждой транзакции они обе окажутся в бесконечном ожидании: транзакция А будет ждать завершения работы транзакции B и разблокировки таблицы 2, а транзакция В также безрезультатно будет ждать окончания работы транзакции А и разблокировки таблицы 1. (Рисунок 1.6). [17]  Рисунок 1.6 Взаимная блокировка транзакций Основой обнаружения тупиковых ситуаций является построение (или постоянное поддержание) графа ожидания транзакций. Граф ожидания транзакций может строиться двумя способами. Если транзакция А ждет окончания транзакции В, то из вершины А в вершину В идет стрелка. Дополнительно стрелки могут быть помечены именами заблокированных объектов и типом блокировки. Пример такого графа ожиданий приведен на рисунке 1.7.  Рисунок 1.7 Пример графа ожиданий транзакций Граф ожиданий построен для транзакций Т1, Т2,___,Т12, которые работают с объектами БД A,В,...,Н. Перечень действий, которые совершают транзакции над объектами, приведен в таблице 1.1. На графе объекты блокировки помечены типами блокировок, S — нежесткая (разделяемая) блокировка, X — жесткая (эксклюзивная) блокировка. На диаграмме состояний ожидания видно, что транзакции Т9, Т8, Т2 и Т3 образуют цикл. Именно наличие цикла и является признаком возникновения тупиковой ситуации. Поэтому в момент 3 перечисленные транзакции будут заблокированы. Критерием выбора является стоимость транзакции; жертвой выбирается самая дешевая транзакция. Стоимость транзакции определяется на основе многофакторной оценки, в которую с разными весами входят время выполнения, число накопленных захватов, приоритет. После выбора транзакции-жертвы выполняется откат этой транзакции, который может носить полный или частичный характер. При этом, естественно, освобождаются захваты и может быть продолжено выполнение других транзакций. Для распознавания тупика здесь, так же как и в первом методе, производится построение графа ожидания транзакций и в этом графе ищутся циклы. Традиционной техникой (для которой существует множество разновидностей) нахождения циклов в ориентированном графе является редукция графа. Не вдаваясь в детали, редукция состоит в том, что, прежде всего из графа ожидания удаляются все дуги, исходящие из вершин-транзакций, в которые не входят дуги из вершин-объектов. (Это как бы соответствует той ситуации, что транзакции, не ожидающие удовлетворения захватов, успешно завершились и освободили захваты.) Для тех вершин-объектов, для которых не осталось входящих дуг, но существуют исходящие, ориентация исходящих дуг изменяется на противоположную (это моделирует удовлетворение захватов). После этого снова срабатывает первый шаг, и так до тех пор, пока на первом шаге не прекратится удаление дуг. Если в графе остались дуги, то они обязательно образуют цикл. [2] Естественно, такое насильственное устранение тупиковых ситуаций является нарушением принципа изолированности пользователей. В централизованных системах стоимость построения графа ожидания сравнительно невелика, но она становится слишком большой в по-настоящему распределенных СУБД, в которых транзакции могут выполняться в разных узлах сети. Поэтому в таких системах обычно используются другие методы сериализации транзакций. Для обеспечения сериализации транзакций синхронизационные захваты объектов, произведенные по инициативе транзакции, можно снимать только при ее завершении. Это требование порождает двухфазный протокол синхронизационных захватов — 2PL(two phase lock) или 2PC (two phase commit). В соответствии с этим протоколом выполнение транзакции разбивается на две фазы: первая фаза транзакции — накопление захватов; вторая фаза (фиксация или откат) — освобождение захватов. Достаточно легко убедиться, что при соблюдении двухфазного протокола синхронизационных захватов действительно обеспечивается полная сериализация транзакций. Однако иногда приложению, которое выполняет транзакцию, не столько важны точные данные, сколько скорость выполнения запросов. Например, в системах поддержки принятия решений по электронным торгам важно просто иметь представление об общей картине торгов, на основании которого принимается решение о повышении или снижении ставок и т. д. Для смягчения требований сериализации транзакций вводится понятие уровня изолированности пользователя. Всего введено 4 уровня изолированности пользователей. Самый высокий уровень изолированности соответствует протоколу сериализации транзакций, это уровень SERIALIZABLE. Этот уровень обеспечивает полную изоляцию транзакций и полную корректную обработку параллельных транзакций. [13] Следующий уровень изолированности называется уровнем подтвержденного чтения — REPEATABLE READ. На этом уровне транзакция не имеет доступа к промежуточным или окончательным результатам других транзакций, поэтому такие проблемы, как пропавшие обновления, промежуточные или несогласованные данные, возникнуть не могут. Однако во время выполнения своей транзакции можно увидеть строку, добавленную в БД другой транзакцией. Поэтому один и тот же запрос, выполненный в течение одной транзакции, может дать разные результаты, то есть проблема строк-призраков остается. Однако если такая проблема критична, лучше ее разрешать алгоритмически, изменяя алгоритм обработки, исключая повторное выполнение запроса в одной транзакции. Третий уровень изолированности связан с подтвержденным чтением, он называется READ COMMITED. На этом уровне изолированности транзакция не имеет доступа к промежуточным результатам других транзакций, поэтому проблемы пропавших обновлений и промежуточных данных возникнуть не могут. Однако окончательные данные, полученные в ходе выполнения других транзакций, могут быть доступны нашей транзакции. При этом уровне изолированности транзакция не может обновлять строку, уже обновленную другой транзакцией. При попытке выполнить подобное обновление транзакция будет отменена автоматически, во избежание возникновения проблемы пропавшего обновления. Самый низкий уровень изолированности называется уровнем неподтвержденного, или грязного, чтения. Он обозначается как READ UNCOMMITED. При этом уровне изолированности текущая транзакция видит промежуточные и несогласованные данные, и также ей доступны строки-призраки.
2. Транзакции в Microsoft SQL Server 2000 2.1 Поведение параллельных транзакций в Microsoft SQL Server
Существует три типа поведения параллельно выполняемых транзакций: Чтение нефиксированных данных (Dirty read). Чтение, при котором происходит считывание еще не фиксированных данных. Чтение нефиксированных данных возникает в том случае, когда одна транзакция модифицирует данные, а вторая транзакция читает эти модифицированные данные до того, как зафиксированы изменения, внесенные в первой транзакции. В случае отката первой транзакции вторая транзакция получит данные, которых нет в базе данных. Неповторяемое чтение (Nonrepeatable read). Несогласующиеся результаты, получаемые при повторном чтении. Неповторяемое чтение возникает в случае, когда чтение одной строки данных происходит более одного раза в течение одной транзакции, а между чтениями отдельная транзакция вносит изменения в эту строку. При повторном чтении в первой транзакции будут считываться другие данные, поэтому в пределах одной транзакции получаются неповторяемые результаты. Фантомное чтение (Phantom read). Чтение, возникающее в том случае, когда одна транзакция пытается прочитать строку, которая еще не существует в начале данной транзакции, но вставляется второй транзакцией, прежде чем закончится первая транзакция. Если первая транзакция снова выполнит поиск этой строки, то обнаружит ее неожиданное появление. Эта новая строка называется фантомной строкой.[16] В таблице 2.1 приводится список типов поведения, которые допускаются на каждом уровне изолированности. Как можно видеть из таблицы, уровень read uncommitted является наименее ограничивающим уровнем изолированности, а serializable – наиболее ограничивающим. Как уже отмечалось, read committed является в SQL Server принятым по умолчанию уровнем изолированности. По мере роста уровня изолированности SQL Server налагает все более ограничивающую блокировку на все более длительные периоды времени. И, как отмечалось, уровень изолированности влияет на блокирующее поведение операторов SELECT, а это означает, что изолированность влияет на режим блокировки, применяемый к читаемым данным. Таблица 2.1 - Поведение при различных уровнях изолированности | Допустимое поведение | Чтение нефиксированных данных | Неповторяемое чтение | Фантомное чтение | | Read uncommitted | Да | Да | Да | | Read committed | Нет | Да | Да | | Repeatable read | Нет | Нет | Да | | Serializable | Нет | Нет | Нет |
Можно задать уровень изолированности, который будет использоваться для всего сеанса пользователя SQL Server, с помощью операторов Transact-SQL (T-SQL) или с помощью функций в вашем приложении. Можно также задать в запросе подсказку блокировки, чтобы переопределить уровень изолированности для данной транзакции. Подсказки блокировки приводятся в секции "Подсказки блокировки". Чтобы задать уровень изолированности с помощью T-SQL или в приложении DB-LIB, используя оператор SET TRANSACTION ISOLATION LEVEL и одного из четырех уровней изолированности. Используется следующий синтаксис: SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE GO После того как задали определенный уровень изолированности для сеанса, все последующие транзакции в этом сеансе SQL Server будут осуществлять блокировку, обеспечивающую этот уровень изолированности. Чтобы определить, какой уровень изолированности SQL Server применяется в данный момент по умолчанию, используйте команду DBCC USEROPTIONS. Нужно указать имя данной команды: DBCC USEROPTIONS Эта команда возвращает в результате только те параметры, которые задал пользователь или которые являются активными. Если не задан уровень изолированности (оставив принятый по умолчанию уровень SQL Server), то не увидите этот уровень, запустив оператор DBCC USEROPTIONS. Но если был задан уровень, отличный от принятого по умолчанию, то увидите этот уровень изолированности. Например, если выполнить следующие операторы, то уровень изолированности будет показан в результатах оператора DBCC USEROPTIONS: USE pubs GO SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO DBCC USEROPTIONS GO Результаты оператора DBCC USEROPTIONS будут выведены в следующей форме: Set Option Value --------------------------------------------- textsize 64512 language us_english dateformat mdy datefirst 7 quoted_identifier SET arithabort SET ansi_null_dflt_on SET ansi_defaults SET ansi_warnings SET ansi_padding SET ansi_nulls SET concat_null_yields_null SET isolation level serializable (13 row(s) affected) Для замещения принятого по умолчанию уровня изолированности можно использовать подсказки блокировки на уровне таблиц. [13 - 16] 2.2 Режимы транзакций в SQL Server
Транзакция может начинаться в одном из трех режимов: автофиксация (autocommit), явный режим (explicit) или неявный режим (implicit). По умолчанию для SQL Server принят режим автофиксации. Режим автофиксации. В режиме автофиксации каждый оператор T-SQL фиксируется по его завершении, и в этом режиме не требуется никаких дополнительных операторов для управления транзакциями. Каждая транзакция состоит только из одного оператора T-SQL. Режим автофиксации полезен при выполнении операторов с помощью интерактивной командной строки, утилиты OSQL или анализатора очередей SQL Server Query Аnalyzer, поскольку не нужно задавать в явном виде запуск и окончание каждой транзакции. Каждый оператор будет рассматриваться системой SQL Server как отдельная транзакция и будет фиксироваться сразу после его завершения. Режим автофиксации будет использоваться в каждом соединении с SQL Server, пока не запустить транзакцию в явном режиме с помощью оператора BEGIN TRANSACTION или пока не укажете неявный режим. По окончании явно заданной транзакции или после отключения неявного режима SQL Server возвращается к режиму автофиксации. Явный режим - используется чаще всего для программных приложений, а также для хранимых процедур, триггеров и сценариев. При запуске группы операторов для выполнения какой-либо задачи может потребоваться указание начала и конца данной транзакции, чтобы затем выполнить фиксацию всей группы операторов или отмену (откат) модификаций всей группы. Если явно указывается начало и конец транзакции, и такую транзакцию называют явной транзакцией. Явная транзакция задается с помощью. Использование явной транзакции. Ситуация, в которой потребовалось бы использование явной транзакции для запуска и окончания задачи. Имеется хранимая процедура с именем Place_Order (Поместить_Заказ), которая управляет в базе данных задачей размещения заказа покупателя на какой-либо товар. Эта процедура включает в себя следующие шаги: выбор информации о текущем счете покупателя, ввод идентификационного номера нового заказа и наименования товара, расчет стоимости заказа с учетом налогов, обновление остатка на счете покупателя с учетом общей стоимости и проверка наличия товара на складе. Для согласованности информации в базе данных нужно, чтобы были завершены все эти шаги или не был завершен ни один из этих шагов. Для этой цели сгруппируем все операторы, управляющие данной задачей, в одну явную транзакцию. Если эти операторы не будут объединены в одну группу, это может привести к несогласованному состоянию данных. Использование явных транзакций, когда задача состоит из нескольких шагов, также дает преимущества, поскольку SQL Server (независимо от использования операторов ROLLBACK) автоматически выполнит откат транзакций в случае серьезных ошибок, таких как обрыв связи в сети, аварийный сбой (базы данных или клиентской системы) или взаимоблокировка. Для запуска транзакции используется оператор T-SQL BEGIN TRANSACTION. Чтобы указать конец транзакции, используется COMMIT TRANSACTION или ROLLBACK TRANSACTION. В операторе BEGIN TRANSACTION можно дополнительно указать имя транзакции и затем ссылаться на эту транзакцию по имени в операторе COMMIT TRANSACTION или ROLLBACK TRANSACTION. 3. Неявный режим. В неявном режиме транзакция автоматически начинается при использовании определенных операторов T-SQL и продолжается, пока не появится оператор явного окончания COMMIT или ROLLBACK. Если оператор окончания не указан, то при отсоединении пользователя происходит откат данной транзакции. Следующие операторы T-SQL являются началом новой транзакции в неявном режиме: ALTER TABLE, CREATE, DELETE, DROP, FETCH, GRANT, INSERT, OPEN, REVOKE, SELECT, TRUNCATE TABLE, UPDATE. Если один из этих операторов используется, чтобы начать неявную транзакцию, эта транзакция продолжается, пока не будет явно указано ее окончание, даже если внутри транзакции снова встретятся эти операторы. После явного фиксирования или отката данной транзакции следующее появление этих операторов является началом новой транзакции. Этот процесс продолжает действовать, пока не будет отключен неявный режим.
Фиксирование транзакций
Фиксированной называется транзакция, все модификации которой стали постоянной частью базы данных. До фиксирования транзакции запись о ее модификациях и запись ее фиксирования заносятся в журнал транзакций базы данных. Таким образом, модификации, которые становятся постоянной частью базы данных, могут находиться в одном из двух мест: либо они фактически записываются на диск и, тем самым, оказываются в базе данных, либо они находятся в кэше данных, что позволяет в случае сбоя выполнить повтор транзакции с помощью журнала транзакций, чтобы избежать потери данной транзакции. Все ресурсы, используемые транзакцией, такие как блокировки, освобождаются после фиксирования данной транзакции. Фиксирование транзакции считается успешным в случае успешного завершения каждого из ее операторов. Ниже приводится небольшая транзакция с именем update_state, которая изменяет в таблице publishers (издатели) значение колонки state на XX для всех издателей, у которых в этой колонке содержится значение NULL: USE pubs GO BEGIN TRAN update_state UPDATE publishers SET state = 'XX' WHERE state IS NULL COMMIT TRAN update_state GO Запустив эту транзакцию, можно увидеть, что это повлияло на две строки. Чтобы вернуть таблицу к ее исходному состоянию (как если бы вместо фиксирования произошел откат), необходимо выполнить следующую транзакцию: USE pubs GO BEGIN TRAN undo_update_state UPDATE publishers SET state = NULL WHERE state = 'XX' COMMIT TRAN undo_update_state GO Это повлияло на две строки. Имена транзакций update_state (модифицировать_состояние) и undo_update_state (отменить _ модификацию _ состояния), используемые в операторе COMMIT TRAN, игнорируются в SQL Server: имена транзакций используются просто для удобства программиста, чтобы можно было указать имя фиксируемой транзакции. SQL Server автоматически фиксирует последнюю нефиксированную транзакцию, запущенную перед фиксированием, независимо от указания имени транзакции.[9 - 11]
2.4 Создание вложенных транзакций в SQL Server
В SQL Server разрешаются вложенные транзакции, т.е. транзакции внутри транзакции. В случае вложенных транзакций можно явно фиксировать каждую внутреннюю транзакцию, чтобы SQL Server получал информацию об окончании внутренней транзакции и мог освободить ресурсы, используемые этой транзакцией, когда будет фиксирована внешняя транзакция. Если ресурсы блокированы, другие пользователи не могут получать доступа к этим ресурсам. Хотя необходимо явным образом включать оператор фиксации COMMIT для каждой транзакции, SQL Server не выполняет фактического фиксирования внутренних транзакций, пока не произойдет успешное фиксирование внешней транзакции; одновременно с этим SQL Server освобождает все ресурсы, используемые внутренними и внешней транзакциями. При неуспешном фиксировании внешней транзакции фиксирование внутренних транзакций не выполняется и происходит откат внешней и всех внутренних транзакций. После фиксирования внешней транзакции выполняется фиксирование внутренних транзакций. SQL Server по сути игнорирует операторы COMMIT внутри внутренних вложенных транзакций, внутренние транзакции не фиксируются в ожидании окончательного фиксирования или отката внешней транзакции, чтобы определить статус завершения всех внутренних транзакций. Кроме того, в случае использования оператора отката ROLLBACK во внешней транзакции или в любой из внутренних транзакций происходит откат всех этих транзакций. В оператор ROLLBACK нельзя включать имя внутренней транзакции; в этом случае SQL Server возвратит сообщение об ошибке. Можно включать имя внешней транзакции, имя точки сохранения или не включать никакого имени. [6] Пример вложенной транзакции, включающей в себя хранимую процедуру. Эта хранимая процедура содержит явную транзакцию и вызывается из другой явной транзакции. USE MyDB GO CREATE PROCEDURE Place_Order --Создает хранимую процедуру AS BEGIN TRAN place_order_tran PRINT 'Здесь должны быть SQL-операторы, выполняющие задачи по заказам' COMMIT TRAN place_order_tran GO BEGIN TRAN Order_tran --Начинает внешнюю транзакцию PRINT 'Поместите заказ' EXEC Place_Order --Вызывает хранимую процедуру, которая начинает внутреннюю транзакцию COMMIT TRAN Order_tran --Фиксирует внутреннюю и внешнюю транзакции GO Выполнив эту программу, можно увидеть результаты обоих операторов PRINT. Транзакция place_order_tran должна содержать внутри хранимой процедуры оператор COMMIT, отмечающий конец этой транзакции, но на самом деле это фиксирование не произойдет, пока не будет выполнено фиксирование транзакции Order_tran. Фиксирование или откат place_order_tran будет зависеть только от фиксирования Order_tran. [4, 8-11] Хотя SQL Server не выполняет фактического фиксирования внутренних транзакций по оператору COMMIT, но все же для каждого оператора COMMIT происходит изменение системной переменной @@TRANCOUNT. Эта переменная следит за количеством активных транзакций на одно соединение с пользователем. При отсутствии активных транзакций значение @@TRANCOUNT равно 0. В начале каждой транзакции (с помощью BEGIN TRAN) значение @@TRANCOUNT увеличивается на 1. После фиксирования каждой транзакции значение @@TRANCOUNT уменьшается на 1. Когда значение @@TRANCOUNT становится равным 0, фиксируется внешняя транзакция. Если во внешней транзакции или в любой из внутренних транзакций выполняется оператор ROLLBACK, то значение @@TRANCOUNT устанавливается равным 0. Чтобы увидеть значение @@TRANCOUNT, необходимо использовать оператор SELECT @@TRANCOUNT. 2.5 Откаты транзакций в SQL Server
Откаты могут происходить в двух формах: автоматический откат, выполняемый SQL Server, или программируемый вручную откат. В определенных случаях SQL Server выполнит откат. Но для обеспечения логической согласованности в программах можно при необходимости явным образом обращаться к оператору ROLLBACK. Рассмотрим более подробно эти два метода. Автоматические откаты. При сбое транзакции вследствие серьезной ошибки, такой как потеря сетевого соединения при выполнении данной транзакции или отказ клиентского приложения или компьютера, SQL Server выполняет автоматический откат транзакции. Во время отката происходит отмена всех модификаций, выполненных в данной транзакции, и освобождение всех ресурсов, использовавшихся этой транзакцией. Если при исполнении какого-либо оператора возникает ошибка, такая как нарушение ограничения или правила, то по умолчанию SQL Server автоматически выполняет откат только этого определенного оператора, в котором возникла ошибка. Чтобы изменить это поведение, можно использовать оператор SET XACT_ABORT. Если задать для XACT_ABORT значение ON, то в случае ошибки исполнения SQL Server автоматически выполнит откат транзакции. Этот метод полезно использовать, например, когда один оператор транзакции не выполняется из-за того, что он нарушает ограничение по внешнему ключу. По умолчанию для XACT_ABORT задано значение OFF. SQL Server использует также автоматический откат при восстановлении сервера. Например, если отключился источник питания во время выполнения транзакций и произошла перезагрузка системы, то при перезапуске SQL Server выполнит автоматическое восстановление. При автоматическом восстановлении происходит чтение информации из журнала транзакций для воспроизведения фиксированных транзакций, которые не были записаны на диск, и отката транзакций, которые находились в процессе выполнения (еще не были фиксированы) в момент отказа источника питания. 2) Программируемые откаты. С помощью оператора ROLLBACK можно указать точку в транзакции, где будет выполнен откат. Оператор ROLLBACK прекращает данную транзакцию и выполняет откат (отмену) всех выполненных изменений. Если запускается откат в середине какой-либо транзакции, то остальная часть этой транзакции игнорируется. Если, например, эта транзакция является хранимой процедурой и оператор ROLLBACK выполняется в этой процедуре, то происходит откат всей процедуры и переход к обработке оператора, следующего после вызова хранимой процедуры. [2, 4, 11-15] Если нужно выполнить откат, исходя из количества строк, возвращенных оператором SELECT, используйте системную переменную @@ROWCOUNT. Эта переменная содержит количество строк, которое возвращается в результате запроса или на которое влияет модификация или удаление. Если конкретное количество строк не имеет значения и просто нужно определить наличие строки или строк для определенного условия, то можно использовать совместно с оператором SELECT оператор IF EXISTS. Этот оператор не возвращает количества строк данных, а только значение TRUE или FALSE. Если результат равен TRUE, то выполняется следующий оператор; если результат равен FALSE, то следующий оператор не выполняется. В операторе IF EXISTS может также использоваться предложение ELSE. Рассмотрим пример использования предложения IF EXISTS...ELSE. В следующей транзакции происходит модификация значений ставки арендной платы (royalty) в таблице roysched для двух ставок арендной платы (royalty rates) (16 процентов и 15 процентов), но если ни одна из этих ставок не существует, то ни одна из команд UPDATE выполняться не будет. Для обеспечения такого результата в этой транзакции используется оператор ROLLBACK. BEGIN TRAN update_royalty --Начать транзакцию. USE pubs IF EXISTS (SELECT titles.title, roysched.royalty FROM titles, roysched WHERE titles.title_id = roysched.title_id AND roysched.royalty = 16) UPDATE roysched SET royalty = 17 WHERE royalty = 16 --Имеется 13 строк. ELSE ROLLBACK TRAN update_royalty --ROLLBACK не выполняется. IF EXISTS (SELECT titles.title, roysched.royalty FROM titles, roysched WHERE titles.title_id = roysched.title_id AND roysched.royalty = 15) --Нет ни одной строки. BEGIN UPDATE roysched SET royalty = 20 WHERE royalty = 15 COMMIT TRAN update_royalty END ELSE --Выполняется ROLLBACK. ROLLBACK TRAN update_royalty GO В этой транзакции первый оператор IF EXISTS (SELECT...) определяет, что существует несколько строк, и поэтому оператор UPDATE выполняется (показывая, что модификация касается 13 строк). Второй оператор SELECT возвращает 0 строк, и поэтому второй оператор UPDATE не выполняется, но выполняется оператор ROLLBACK TRAN update_royalty. Поскольку ROLLBACK выполняет откат всех модификаций до самого начала данной транзакции, то происходит откат первой модификации. Если снова выполнить первый оператор SELECT, то по-прежнему будут 13 строк со значением royalty, равным 16, как и было в исходном состоянии базы данных, когда запускали данную транзакцию. И снова изменение royalty на значение 17 будет отменено (будет выполнен откат) из-за оператора ROLLBACK. Откат транзакции нельзя выполнить после ее фиксирования. Чтобы можно было выполнить явный откат отдельной транзакции, оператор ROLLBACK должен предшествовать оператору COMMIT. В случае вложенных транзакций после фиксирования внешней транзакции (и, тем самым, внутренних транзакций) уже нельзя выполнить откат ни одной из транзакций. Нельзя выполнить откат только внутренних транзакций; должен быть выполнен откат всей транзакции (всех внутренних транзакций и внешней транзакции). Поэтому, включив имя транзакции в оператор ROLLBACK, проследите за тем, чтобы было указано имя внешней транзакции (во избежание путаницы и сообщения об ошибке от SQL Server). Однако существует обходной путь, позволяющий избежать отката всей транзакции и сохранить часть модификаций: можно использовать точки сохранения. 3) Точки сохранения. Можно избежать отката всей транзакции, для этого нужно использовать точку сохранения, которая позволяет выполнять откат только до определенной точки в транзакции, а не до самого начала транзакции. Все модификации, выполненные до точки сохранения, остаются в силе и не подвергаются откату; но для всех операторов, выполняемых после точки сохранения (которую вы должны указать в транзакции) вплоть до оператора ROLLBACK, будет выполнен откат. Затем начнут выполняться операторы, следующие за оператором ROLLBACK. Если затем зададить откат транзакции без указания точки сохранения, то, как обычно, будет выполнен откат всех модификаций вплоть до начала данной транзакции, т.е. будет отменена вся транзакция. Отметим, что при откате транзакции до точки сохранения SQL Server не освобождает блокированные ресурсы. Они будут освобождены после фиксирования транзакции или после отката всей транзакции. [1]
2.6 Блокировка транзакций в SQL Server
В SQL Server используется объект, который называется блокировкой (lock); он препятствует тому, чтобы несколько пользователей одновременно вносили изменения в базу данных и чтобы один пользователь считывал данные, которые изменяет в этот момент другой пользователь. Блокировка помогает обеспечивать логическую целостность транзакций и данных. Управление блокировками осуществляется внутренним образом из программного обеспечения SQL Server и захват блокировки осуществляется на уровне пользовательского соединения. К ресурсам, которые может блокировать пользователь, относятся строка данных, страница данных экстент (8 страниц), таблица или вся база данных. [4] Система управления блокировками SQL Server автоматически захватывает и освобождает блокировки в соответствии с действиями пользователей. Для управления блокировками не требуется никаких действий со стороны DBA (администратора базы данных) или программиста. Однако можно использовать программные подсказки (hint), чтобы задать для SQL Server, какой тип блокировки нужно захватывать при выполнении определенного запроса или модификации базы данных. SQL Server поддерживает блокировку на уровне строк, т.е. позволяет захватывать блокировку по строке страницы данных или страницы индекса. Блокировка на уровне строк – самый высокий уровень детализации, который можно получить в SQL Server. Блокировка на уровне строк особенно полезна, когда выполняются вставки, обновления и удаления в таблицах и индексах. В дополнение к возможности блокировки на уровне строк SQL Server обеспечивает простоту администрирования для конфигурации блокировок.. По умолчанию при увеличении необходимого количества блокировок SQL Server динамически выделяет дополнительное количество вплоть до предела, определяемого памятью SQL Server. Если какое-то количество блокировок больше не используется, SQL Server освобождает их. SQL Server также оптимизирован для динамического выбора типа блокировки, который захватывается по какому-либо ресурсу – обычно это блокировка на уровне строк для вставок, обновлений и удалений и блокировка страниц для сканирования таблиц.[5] Блокировки могут захватываться по целому ряду ресурсов; тип ресурса определяет уровень детализации данной блокировки. В таблице 2.2 приводится список ресурсов, которые может блокировать SQL Server, начиная с самого подробного и до самого крупного уровня детализации. Таблица 2.2 Блокируемые ресурсы | Ресурс | Тип блокировки | Описание | | Идентификатор строки | Уровень строки | Блокирует отдельную строку в таблице | | Ключ | Уровень строки | Блокирует отдельную строку в индексе | | Страница | Уровень страницы Блокирует отдельную страницу размером 8 Кб в таблице или индексе |
| | Экстент | Уровень экстента | Блокирует экстент – группу из 8 последовательных страниц данных или страниц индекса | | Таблица | Уровень таблицы | Блокирует всю таблицу | | База данных | Уровень базы данных | Блокирует всю базу данных |
При снижении уровня детализации снижается степень параллельности. Например, блокировка всей таблицы с помощью определенного типа блокировки может заблокировать доступ к этой таблице другим пользователям. Но при этом снижается объем передачи дополнительной служебной информации (непроизводительные затраты), поскольку используется меньшее количество блокировок. SQL Server автоматически выбирает тип блокировки, подходящий для данной задачи, минимизируя при этом непроизводительные затраты на блокировку. SQL Server также автоматически определяет режим блокировки для каждой транзакции, касающейся блокируемого ресурса. Блокирование (blocking) и взаимоблокировки (deadlock) – это две дополнительные проблемы, которые могут возникать при одновременно выполняемых транзакциях. Они могут приводить к серьезным проблемам системы, а также могут замедлять и даже останавливать работу. Эти проблемы могут разрешаться в приложении, или SQL Server постарается сделать все возможное для их разрешения. Блокирование возникает в том случае, когда одна транзакция владеет блокировкой по какому-либо ресурсу, а второй транзакции требуется конфликтный тип блокировки по этому ресурсу. Вторая транзакция должна ждать, пока первая транзакция освободит свою блокировку; иными словами, она блокирована первой транзакцией. Проблема блокирования обычно возникает, когда какая-либо транзакция захватывает блокировку на длительный период времени, что приводит к цепочке блокированных транзакций, ожидающих окончания других транзакций, чтобы получить необходимые им блокировки; это состояние называют цепным блокированием. Взаимоблокировка отличается от блокированной транзакции в том, что взаимоблокировка возникает в случае двух блокированных транзакций, ожидающих друг друга. Например, одна транзакция владеет монопольной блокировкой по Таблице 1, а вторая владеет монопольной блокировкой по Таблице 2. Прежде чем будет освобождена любая монопольная блокировка, первой транзакции требуется блокировка по Таблице 2 и второй транзакции – требуется блокировка по Таблице 1. Теперь каждая транзакция ждет, пока другая транзакция освободит свою монопольную блокировку, но ни одна из транзакций не сделает этого, пока не будет выполнено фиксирование или откат для завершения соответствующей транзакции. Ни одна из транзакций не может завершиться, поскольку для продолжения работы ей требуется блокировка, которой владеет другая транзакция, – ситуация взаимоблокировки. (Рисунок 2.1) При возникновении взаимоблокировки SQL Server прекращает одну из транзакций, и ее требуется запустить заново. 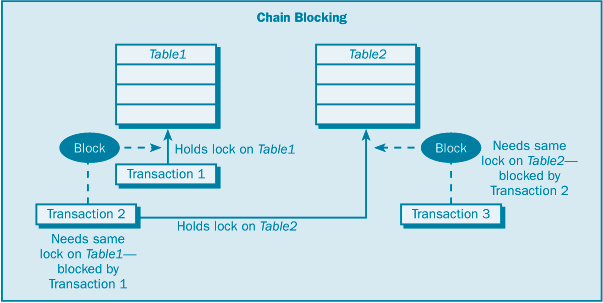 Рисунок 2.1 Цепное блокирование 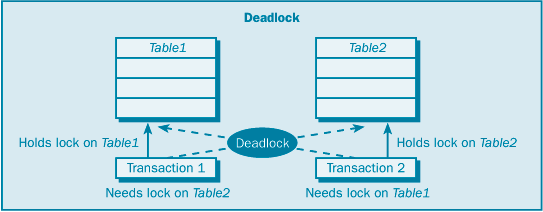 Рисунок 2.2 Взаимоблокировка Подсказки блокировки – это ключевые слова T-SQL, которые можно использовать с операторами SELECT, INSERT, UPDATE и DELETE, чтобы задать для SQL Server использование предпочтительного типа блокировки на уровне таблицы для определенного оператора. Можно использовать подсказки блокировки для переопределения принятого по умолчанию уровня изолированности. [2-6, 11,14] Рассмотрю ситуацию, где может оказаться полезным использование подсказок блокировки. Используется для всех транзакций принятый по умолчанию уровень изолированности read uncommitted (чтение незафиксированных данных). При этом уровне изолированности по данному ресурсу захватывается разделяемая блокировка только до завершения чтения, и затем эта разделяемая блокировка освобождается. И если какая-либо транзакция читает одни и те же данные дважды, то результаты чтения могут не совпасть, поскольку другая транзакция могла захватить блокировку между первым и вторым чтениями и модифицировать эти данные. Чтобы избежать проблемы повторяемости чтения, можно задать уровень изолированности serializable (упорядочиваемость), но это вынудит SQL Server захватить все разделяемые блокировки, необходимые для операторов SELECT во всех транзакциях, пока не будет завершена каждая транзакция. Иными словами, для целостности транзакций разделяемые блокировки будут захвачены по таблице, указанной в операторе SELECT любой транзакции. Если не хотите поддерживать упорядочиваемость для всех ваших транзакций, то можете добавить какую-либо подсказку блокировки для определенного запроса. Подсказка блокировки HOLDLOCK в операторе SELECT указывает SQL Server захват всех разделяемых блокировок по таблице, заданной в операторе транзакции SELECT, вплоть до конца этой транзакции – независимо от уровня изолированности. В следующем списке дается описание существующих подсказок блокировки на уровне таблиц. HOLDLOCK. Захватывает разделяемую блокировку до завершения транзакции, а не освобождает ее сразу после того, как уже не требуется соответствующая таблица, страница или строка данных. Эквивалентно использованию подсказки блокировки SERIALIZABLE. NOLOCK. Применяется только к оператору SELECT. Не получает разделяемых блокировок и не поддерживает монопольных блокировок; читает данные, которые монопольно захвачены другой транзакцией. Эта подсказка позволяет читать нефиксированные данные (dirty read). PAGLOCK. Используется для блокировки на уровне страницы там, где обычно используется блокировка на уровне таблицы. READCOMMITTED. Выполняется сканирование с тем же поведением по блокировкам, как у транзакций, использующих уровень изолированности read committed (принятый по умолчанию уровень изолированности для SQL Server). READPAST. Применяется только к оператору SELECT и только к строкам, блокированным с помощью блокировки на уровне строк. Пропускаются строки, блокированные другими транзакциями, которые обычно включаются в набор результатов; возвращает результаты без этих блокированных строк. Может использоваться только с транзакциями, выполняемыми на уровне изолированности read committed. READUNCOMMITTED. Эквивалентно NOLOCK. REPEATABLEREAD.Выполняется сканирование с тем же поведением по блокировкам, как у транзакций, использующих уровень изолированности repeatable read. ROWLOCK.Используются блокировки на уровне строк вместо блокировки на уровне страниц или на уровне таблиц. SERIALIZABLE.Выполняется сканирование с тем же поведением по блокировкам, как у транзакций, использующих уровень изолированности serializable. Эквивалентно HOLDLOCK. TABLOCK.Используется блокировка на уровне таблиц вместо блокировки на уровне страниц или на уровне строк. SQL Server захватывает эту блокировку до завершения оператора. TABLOCKX. Используется монопольная блокировка по таблице. Внимание! Эта подсказка препятствует доступу других транзакций к этой таблице. UPDLOCK. Используются блокировки изменения вместо монопольных блокировок при чтении таблицы. Можно объединять совместимые подсказки блокировки, такие как TABLOCK и REPEATABLEREAD, но не льзя объединять конфликтующие подсказки, такие как REPEATABLEREAD и SERIALIZABLE. Чтобы задать подсказку блокировки на уровне таблиц, необходимо заключить эту подсказку в круглые скобки после имени таблицы в операторе T-SQL. Следующая последовательность является примером использования подсказок TABLOCKX в операторе SELECT: USE pubs SELECT COUNT(ord_num) FROM sales (TABLOCKX) WHERE ord_date > "Sep 13 1994" GO Подсказка TABLOCK сообщает SQL Server, что нужно захватить монопольную блокировку на уровне таблиц по таблице продаж (sales), пока не будет выполнен данный оператор. Эта подсказка обеспечивает, что никакая другая транзакция не сможет модифицировать данные в таблице sales, пока данный запрос подсчитывает заказы из этой таблицы. [5]
Заключение
В ходе выполнения работы было рассмотрено 3 вопроса: принцип создания и работы транзакции, свойства транзакций, технология применения транзакций в SQL Server 2000. Из проведенной работы можно сделать вывод, что во многих случаях, необходимо проведение группы операций по изменению данных таким образом, чтобы эта группа обладала свойством атомарности (либо вся целиком выполняется, либо вся целиком не выполняется). SQL Server предлагает множество средств управления поведением транзакций. Пользователи в основном должны указывать только начало и конец транзакции, используя команды SQL или API (прикладного интерфейса программирования). Таким образом, для реализации транзакций SQL Server является наиболее оптимальной программой. Сервер баз данных Microsoft SQL Server в качестве языка запросов использует версию языка SQL, получившую название Transact-SQL (сокращённо T-SQL). Язык T-SQL является реализацией SQL-92 (стандарт ISO для языка SQL) с множественными расширениями. T-SQL позволяет использовать дополнительный синтаксис для хранимых процедур и обеспечивает поддержку транзакций (взаимодействие базы данных с управляющим приложением). При взаимодействии с сетью Microsoft SQL Server и Sybase ASE используют протокол уровня приложения под названием Tabular Data Stream (TDS, протокол передачи табличных данных). Протокол TDS также был реализован в проекте FreeTDS с целью обеспечить различным приложениям возможность взаимодействия с базами данных Microsoft SQL Server и Sybase. Для обеспечения доступа к данным Microsoft SQL Server поддерживает Open Database Connectivity (ODBC) — интерфейс взаимодействия приложений с СУБД. Версия SQL Server 2005 обеспечивает возможность подключения пользователей через веб-сервисы, использующие протокол SOAP. Это позволяет клиентским программам, не предназначенным для Windows, кроссплатформенно соединяться с SQL Server. Компания Microsoft также выпустила сертифицированный драйвер JDBC, позволяющий приложениям под управлением Java (таким как BEA и IBM WebSphere) соединяться с Microsoft SQL Server 2000 и 2005. Также SQL Server поддерживает зеркалирование и кластеризацию баз данных. Кластер сервера SQL — это совокупность одинаково конфигурированных серверов; такая схема помогает распределить рабочую нагрузку между несколькими серверами. Все сервера имеют одно виртуальное имя, и данные распределяются по IP-адресам машин кластера в течение рабочего цикла. Также в случае отказа или сбоя на одном из серверов кластера доступен автоматический перенос нагрузки на другой сервер. SQL Server поддерживает избыточное дублирование данных по трем сценариям: Снимок: Производится «снимок» базы данных, который сервер отправляет получателям. История изменений: Все изменения базы данных непрерывно передаются пользователям. Синхронизация с другими серверами: Базы данных нескольких серверов синхронизируются между собой. Изменения всех баз данных происходят независимо друг от друга на каждом сервере, а при синхронизации происходит сверка данных. Данный тип дублирования предусматривает возможность разрешения противоречий между БД. Microsoft и другие компании производят большое число программных средств разработки, позволяющих разрабатывать бизнес-приложения с использованием баз данных Microsoft SQL Server. SQL Server 2008 Последняя версия SQL Server — SQL Server 2008 R2. Была выпущена 21 апреля 2010 года. SQL Server 2008 направлен на то, чтобы сделать управление данными самонастраивающимся, самоорганизующимся и самообслуживающимся механизмом — для реализации этих возможностей были созданы технологии SQL Server Always On. Это позволит уменьшить до нуля время нахождения сервера в нерабочем состоянии. В SQL Server 2008 была добавлена поддержка структурированных и частично структурированных данных, включая цифровые форматы для изображений, звуков, видео и других типов мультимедиа. Поддержка мультимедиа форматов внутри СУБД позволила специализированным функциям взаимодействовать с этими типами данных. Кроме этого, были включены специализированные форматы даты и времени и пространственный (англ. Spatial) тип для пространственно зависимых данных. Для неструктурированных данных были добавлены специализированные типы, например, тип File. Для повышения эффективности администрирования в SQL Server были включены библиотеки Declarative Management Framework, позволяющие распределять полномочия для баз данных или отдельных таблиц. Были улучшены методы компрессии данных. SQL Server Katmai поддерживает набор библиотек ADO.NET Entity Framework и средства оповещения, репликации и определения данных.
Глоссарий
| № п/п | Понятие | Определение | | 1. | База данных (БД) | поименованная, целостная, единая система данных, организованная по определенным правилам, которые предусматривают общие принципы описания, хранения и обработки данных | | 2. | Блокировка | временное ограничение, накладываемое системой на использование тех или иных ресурсов | | 3. | Данные | последовательность элементарных символов, цифр или букв, являющихся значением некоторого атрибута | | 4. | Журнал транзакций | системная структура, которая создается для сохранения промежуточных состояний, подтверждения или отката транзакции | | 5. | Логическая структура базы данных | системные и пользовательские таблицы, представления, хранимые процедуры, пользователи и роли, умолчания, ограничения целостности и другие объекты | | 6. | Откат транзакции | действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции.
| | 7. | Система управления базами данных (СУБД) | специальный комплекс программ, осуществляющий централизованное управление базой данных | | 8. | Транзакция | набор из одной и более команд, обрабатываемых как единое целое | | 9. | Фиксация транзакций | действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. | | 10. | Хранилище данных | предметно-ориентированный, интегрированный, привязанный ко времени и неизменяемый набор данных, предназначенный для поддержки принятия решений. |
Список использованных источников
Бройдо, Ильина О. Вычислительные системы, сети и телекоммуникации. – Питер, 2006 Горев А., Ахаян Р., Макашарипов С. Эффективная работа с СУБД. - СПб: Питер, 2006 Грей Дж. и Реутер A. Транзакции. - Сан Франциско: Морган Кауфман, 2006 Дайер У. Мониторы транзакций третьего поколения, 2006 Дейт К. Дж. Введение в системы баз данных – 6-е изд. – Вильямс, 2008 Кагаловский М.Р. Энциклопедия технологий баз данных. – М.: Финансы и статистика, 2007 Кайт Том. Oracle для профессионалов – Питер, 2006 Клигман Т.И. Реляционная модель данных: учебное пособие. - ПРИПИТ, ПГПУ, 2009 Кодд Дж., «Базы данных», Москва. Мир. 2006 Крёнке Д. Теория и практика построения баз данных 9-е изд. - СПб: Питер, 2007 Кузнецов С. SQL: язык реляционных баз данных. – М. Майор, 2006 Мамаев Е. Microsoft SQL Server 2000 – СПб.: БХВ-Петербург, 2006 Стасышин В.М. Распределенные СУБД. Informix. Ч.1. Основы работы с базами данных. - Методические указания для выполнения лабораторных работ / - Новосибирск: НГТУ, 2009 Фаронов В.В. Основы программирования в SQL. - М.: Издатель Молгачева С.В., 2007 Федоров А., Елманова Н. Введение в базы данных. - Компьютер Пресс, №3-12 2008 г., №1-2 2009 Хомоненко А.Д., Цыганков В.М., Мальцев М.Г. Базы данных. – СПб.: Корона принт, 2008
Приложения
| А
|  |
СОДЕРЖАНИЕ
ВВЕДЕНИЕ 4 ГЛАВА 1. ТРАНЗАКЦИИ 5 1.1 Свойства транзакций. Способы завершения транзакций 5 1.2 Журнал транзакций. Журнализация и буферизация 12 1.3 Индивидуальный откат транзакции. Восстановление после мягкого сбоя 18 1.4 Физическая согласованность базы данных. Восстановление после жесткого сбоя 20 1.5 Параллельное выполнение транзакций. Уровни изолированности пользователей 24 1.6 Гранулированные синхронизационные захваты. Предикатные синхронизационные захваты 40 1.7 Метод временных меток 45 ГЛАВА 2. ТРАНЗАКЦИИ В MICROSOFT SQL SERVER 2000 47 2.1 Поведение параллельных транзакций в Microsoft SQL Server 47 2.2 Режимы транзакций в SQL Server 50 2.2.1 Режим автофиксации 50 2.2.2. Явный режим 51 2.2.3 Использование явной транзакции 51 2.2.4 Фиксирование транзакций 52 2.3 Создание вложенных транзакций в SQL Server 54 2.3.1 Использование @@TRANCOUNT 56 2.3.2 Неявный режим 58 2.4 Откаты транзакций в SQL Server 59 2.4.1 Автоматические откаты 59 2.4.2 Программируемые откаты 60 2.4.3 Точки сохранения 62 2.5 Блокировка транзакций в SQL Server 63 2.5.1 Возможности управления блокировками 64 2.5.2 Уровни блокировок 65 2.6 Блокирование и взаимоблокировки 66 2.6.1 Подсказки блокировки 68 Заключение 72 Список используемых источников 73 Приложение 1 74 Введение Актуальность данного исследование обусловлено необходимостью обработки большого количества баз данных в различных отраслях. Целью данной работы является рассмотрение технологии работы с транзакциями, а так же работу транзакций в Microsoft SQL Server 2000. Реализация поставленной цели потребовало решения ряда конкретных задач, а именно: Рассмотреть принцип создания и работы транзакции; Рассмотреть свойства транзакций; Рассмотреть технологию применения транзакций в SQL Server 2000. Исследование состоит из введения, двух глав, заключения и списка литературы. В ведении обоснована актуальность исследования и даны его основные характеристики. Первая глава посвящена основным сведениям по транзакциям. В ней рассматривается сущность транзакций, основные ее характеристики, свойства транзакций, способы завершения транзакций, журнал транзакций, журнализация и буферизация, индивидуальный откат транзакции, восстановление после мягкого сбоя, физическая согласованность базы данных, восстановление после жесткого сбоя, параллельное выполнение транзакций, уровни изолированности пользователей, гранулированные синхронизационные захваты, предикатные синхронизационные захваты , метод временных меток. Во второй главе представлены транзакции в Microsoft SQL server 2000. В ней рассматривается: поведение параллельных транзакций в Microsoft SQL Server, режимы транзакций в SQL Server, создание вложенных транзакций в SQL Server, откаты транзакций в SQL Server, блокировка транзакций в SQL Server, блокирование и взаимоблокировки. В заключении приведены основные выводы проведенного исследования. Библиография насчитывает 17 наименований. ГЛАВА 1. Транзакции 1.1 Свойства транзакций. Способы завершения транзакций
Транзакцией называется последовательность операций, производимых над базой данных и переводящих базу данных из одного непротиворечивого (согласованного) состояния в другое непротиворечивое (согласованное) состояние. Транзакция рассматривается как некоторое неделимое действие над базой данных, осмысленное с точки зрения пользователя. В то же время это логическая единица работы системы. Рассмотрим несколько примеров. Что может быть названо транзакцией? Кем определяется, какая последовательность операций над базой данных составляет транзакцию? Конечно, однозначно именно разработчик определяет, какая последовательность операций составляет единое целое, то есть транзакцию. Разработчик приложений или хранимых процедур определяет это исходя из смысла обработки данных, именно семантика совокупности операций над базой данных, которая моделирует с точки зрения разработчика некоторую одну неразрывную работу, и составляет транзакцию. Допустим, выделим работу по вводу данных о поступивших книгах, новых книгах, которых не было раньше в библиотеке. Тогда эту операцию можно разбить на две последовательные: сначала ввод данных о книге — это новая строка в таблице BOOKS, а потом ввод данных обо всех экземплярах новой книги — это ввод набора новых строк в таблицу EXEMPLAR в количестве, равном количеству поступивших экземпляров книги. Если эта последовательность работ будет прервана, то наша база данных не будет соответствовать реальному объекту, поэтому желательно выполнять ее как единую работу над базой данных. Следующий пример, который связан с принятием заказа в фирме на изготовление компьютера. Компьютер состоит из комплектующих, которые сразу резервируются за данным заказом в момент его формирования. Тогда транзакцией будет вся последовательность операций, включающая следующие операции: ввод нового заказа со всеми реквизитами заказчика; изменения состояния для всех выбранных комплектующих на складе на "занято" с привязкой их к определенному заказу; подсчет стоимости заказа с формированием платежного документа типа выставляемого счета к оплате; включение нового заказа в производство. С точки зрения работника, это единая последовательность операций; если она будет прервана, то база данных потеряет свое целостное состояние. Еще один пример, который весьма характерен для учебных заведений. При длительной болезни преподавателя или при его увольнении перед администрацией кафедры встает задача перераспределения всей нагрузки, которую ведет преподаватель, по другим преподавателям кафедры. Видов нагрузки может быть несколько: чтение лекций и проведение занятий по текущему расписанию, руководство квалификационными работами бакалавров, руководство дипломными проектами специалистов, руководство магистерскими диссертациями, индивидуальная научно-исследовательская работа со студентами. И для каждого вида нагрузки необходимо найти исполнителей и назначить им дополнительную нагрузку. Существуют различные модели транзакций, которые могут быть классифицированы на основании различных свойств, включающих структуру транзакции, параллельность внутри транзакции, продолжительность и т. д. В настоящий момент выделяют следующие типы транзакций: плоские или классические транзакции, цепочечные транзакции и вложенные транзакции. Плоские, или традиционные, транзакции, характеризуются четырьмя классическими свойствами: атомарности, согласованности, изолированности, долговечности (прочности) — ACID (Atomicity, Consistency, Isolation, Durability). Иногда традиционные транзакции называют ACID-транзакциями. Упомянутые выше свойства означают следующее: Свойство атомарности (Atomicity) выражается в том, что транзакция должна быть выполнена в целом или не выполнена вовсе. Свойство согласованности (Consistency) гарантирует, что по мере выполнения транзакций данные переходят из одного согласованного состояния в другое — транзакция не разрушает взаимной согласованности данных. Свойство изолированности (Isolation) означает, что конкурирующие за доступ к базе данных транзакции физически обрабатываются последовательно, изолированно друг от друга, но для пользователей это выглядит так, как будто они выполняются параллельно. Свойство долговечности (Durability) трактуется следующим образом: если транзакция завершена успешно, то те изменения в данных, которые были ею произведены, не могут быть потеряны ни при каких обстоятельствах (даже в случае последующих ошибок). Возможны два варианта завершения транзакции. Если все операторы выполнены успешно и в процессе выполнения транзакции не произошло никаких сбоев программного или аппаратного обеспечения, транзакция фиксируется. Фиксация транзакции — это действие, обеспечивающее запись на диск изменений в базе данных, которые были сделаны в процессе выполнения транзакции. До тех пор пока транзакция не зафиксирована, допустимо аннулирование этих изменений, восстановление базы данных в то состояние, в котором она была на момент начала транзакции. Фиксация транзакции означает, что все результаты выполнения транзакции становятся постоянными. Они станут видимыми другим транзакциям только после того, как текущая транзакция будет зафиксирована. До этого момента все данные, затрагиваемые транзакцией, будут "видны" пользователю в состоянии на начало текущей транзакции. Если в процессе выполнения транзакции случилось нечто такое, что делает невозможным ее нормальное завершение, база данных должна быть возвращена в исходное состояние. Откат транзакции — это действие, обеспечивающее аннулирование всех изменений данных, которые были сделаны операторами SQL в теле текущей незавершенной транзакции. Каждый оператор в транзакции выполняет свою часть работы, но для успешного завершения всей работы в целом требуется безусловное завершение всех их операторов. Группирование операторов в транзакции сообщает СУБД, что вся эта группа должна быть выполнена как единое целое, причем такое выполнение должно поддерживаться автоматически. В стандарте ANSI/ISO SQL определены модель транзакций и функции операторов COMMIT и ROLLBACK. Стандарт определяет, что транзакция начинается с первого SQL-оператора, инициируемого пользователем или содержащегося в программе, изменяющего текущее состояние базы данных. Все последующие SQL-операторы составляют тело транзакции. Транзакция завершается одним из четырех возможных путей (рис. 1): 
Рисунок 1 - Модель транзакций ANSI/ISO оператор COMMIT означает успешное завершение транзакции; его использование делает постоянными изменения, внесенные в базу данных в рамках текущей транзакции; оператор ROLLBACK прерывает транзакцию, отменяя изменения, сделанные в базе данных в рамках этой транзакции; новая транзакция начинается непосредственно после использования ROLLBACK; успешное завершение программы, в которой была инициирована текущая транзакция, означает успешное завершение транзакции (как будто был использован оператор COMMIT); ошибочное завершение программы прерывает транзакцию (как будто был использован оператор ROLLBACK). В этой модели каждый оператор, который изменяет состояние БД, рассматривается как транзакция, поэтому при успешном завершении этого оператора БД переходит в новое устойчивое состояние. В первых версиях коммерческих СУБД была реализована модель транзакций ANSI/ISO. В дальнейшем в СУБД SYBASE была реализована расширенная модель транзакций, которая включает еще ряд дополнительных операций. В модели SYBASE используются следующие четыре оператора: Оператор BEGIN TRANSACTION сообщает о начале транзакции. В отличие от модели в стандарте ANSI/ISO, где начало транзакции неявно задается первым оператором модификации данных, в модели SYBASE начало транзакции задается явно с помощью оператора начала транзакции. Оператор COMMIT TRANSACTION сообщает об успешном завершении транзакции. Он эквивалентен оператору COMMIT в модели стандарта ANSI/ISO. Этот оператор, как и оператор COMMIT, фиксирует все изменения, которые производились в БД в процессе выполнения транзакции. Оператор SAVE TRANSACTION создает внутри транзакции точку сохранения, которая соответствует промежуточному состоянию БД, сохраненному на момент выполнения этого оператора. В операторе SAVE TRANSACTION может стоять имя точки сохранения. Поэтому в ходе выполнения транзакции может быть запомнено несколько точек сохранения, соответствующих нескольким промежуточным состояниям. Оператор ROLLBACK имеет две модификации. Если этот оператор используется без дополнительного параметра, то он интерпретируется как оператор отката всей транзакции, то есть в этом случае он эквивалентен оператору отката ROLLBACK в модели ANSI/ISO. Если же оператор отката имеет параметр и записан в виде ROLLBACK B, то он интерпретируется как оператор частичного отката транзакции в точку сохранения B. Принципы выполнения транзакций в расширенной модели транзакций представлены на рис.2. На рисунке операторы помечены номерами, чтобы нам удобнее было проследить ход выполнения транзакции во всех допустимых случаях. 
Рисунок 2 - Примеры выполнения транзакций в расширенной модели Транзакция начинается явным оператором начала транзакции, который имеет в нашей схеме номер 1. Далее идет оператор 2, который является оператором поиска и не меняет текущее состояние БД, а следующие за ним операторы 3 и 4 переводят базу данных уже в новое состояние. Оператор 5 сохраняет это новое промежуточное состояние БД и помечает его как промежуточное состояние в точке А. Далее следуют операторы 6 и 7, которые переводят базу данных в новое состояние. А оператор 8 сохраняет это состояние как промежуточное состояние в точке В. Оператор 9 выполняет ввод новых данных, а оператор 10 проводит некоторую проверку условия 1; если условие 1 выполнено, то выполняется оператор 11, который проводит откат транзакции в промежуточное состояние В. Это означает, что последствия действий оператора 9 как бы стираются и база данных снова возвращается в промежуточное состояние В, хотя после выполнения оператора 9 она уже находилась в новом состоянии. И после отката транзакции вместо оператора 9, который выполнялся раньше из состояния В БД, выполняется оператор 13 ввода новых данных, и далее управление передается оператору 14. Оператор 14 снова проверяет условие, но уже некоторое новое условие 2; если условие выполнено, то управление передается оператору 15, который выполняет откат транзакции в промежуточное состояние А, то есть все операторы, которые изменяли БД, начиная с 6 и заканчивая 13, считаются невыполненными, то есть результаты их выполнения исчезли и мы снова находимся в состоянии А, как после выполнения оператора 4. Далее управление передается оператору 17, который обновляет содержимое БД, после этого управление передается оператору 18, который связан с проверкой условия 3. Проверка заканчивается либо передачей управления оператору 20, который фиксирует транзакцию, и БД переходит в новое устойчивое состояние, и изменить его в рамках текущей транзакции невозможно. Либо, если управление передано оператору 19, то транзакция откатывается к началу и БД возвращается в свое начальное состояние, а все промежуточные состояния здесь уже проверены, и выполнить операцию отката в эти промежуточные состояния после выполнения оператора 19 невозможно. Конечно, расширенная модель транзакции, предложенная фирмой SYBASE, поддерживает гораздо более гибкий механизм выполнения транзакций. Точки сохранения позволяют устанавливать маркеры внутри транзакции таким образом, чтобы имелась возможность отмены только части работы, проделанной в транзакции. Целесообразно использовать точки сохранения в длинных и сложных транзакциях, чтобы обеспечить возможность отмены изменения для определенных операторов. Однако это обусловливает дополнительные затраты ресурсов системы — оператор выполняет работу, а изменения затем отменяются; обычно усовершенствования в логике обработки могут оказаться более оптимальным решением.
1.2 Журнал транзакций. Журнализация и буферизация
Реализация в СУБД принципа сохранения промежуточных состояний, подтверждения или отката транзакции обеспечивается специальным механизмом, для поддержки которого создается некоторая системная структура, называемая Журналом транзакций. Однако назначение журнала транзакций гораздо шире. Он предназначен для обеспечения надежного хранения данных в БД. А это требование предполагает, в частности, возможность восстановления согласованного состояния базы данных после любого рода аппаратных и программных сбоев. Очевидно, что для выполнения восстановлений необходима некоторая дополнительная информация. В подавляющем большинстве современных реляционных СУБД такая избыточная дополнительная информация поддерживается в виде журнала изменений базы данных, чаще всего называемого Журналом транзакций. Общей целью журнализации изменений баз данных является обеспечение возможности восстановления согласованного состояния базы данных после любого сбоя. Поскольку основой поддержания целостного состояния базы данных является механизм транзакций, журнализация и восстановление тесно связаны с понятием транзакции. Общими принципами восстановления являются следующие: результаты зафиксированных транзакций должны быть сохранены в восстановленном состоянии базы данных; результаты незафиксированных транзакций должны отсутствовать в восстановленном состоянии базы данных. Это, собственно, и означает, что восстанавливается последнее по времени согласованное состояние базы данных. Возможны следующие ситуации, при которых требуется производить восстановление состояния базы данных. Индивидуальный откат транзакции. Этот откат должен быть применен в следующих случаях: стандартной ситуацией отката транзакции является ее явное завершение оператором ROLLBACK; аварийное завершение работы прикладной программы, которое логически эквивалентно выполнению оператора ROLLBACK, но физически имеет иной механизм выполнения; принудительный откат транзакции в случае взаимной блокировки при параллельном выполнении транзакций. В подобном случае для выхода из тупика данная транзакция может быть выбрана в качестве "жертвы" и принудительно прекращено ее выполнение ядром СУБД. Восстановление после внезапной потери содержимого оперативной памяти (мягкий сбой). Такая ситуация может возникнуть в следующих случаях: при аварийном выключении электрического питания; при возникновении неустранимого сбоя процессора (например, срабатывании контроля оперативной памяти) и т. д. Ситуация характеризуется потерей той части базы данных, которая к моменту сбоя содержалась в буферах оперативной памяти. Восстановление после поломки основного внешнего носителя базы данных (жесткий сбой). Эта ситуация при достаточно высокой надежности современных устройств внешней памяти может возникать сравнительно редко, но тем не менее СУБД должна быть в состоянии восстановить базу данных даже и в этом случае. Основой восстановления является архивная копия и журнал изменений базы данных. Для восстановления согласованного состояния базы данных при индивидуальном откате транзакции нужно устранить последствия операторов модификации базы данных, которые выполнялись в этой транзакции. Для восстановления непротиворечивого состояния БД при мягком сбое необходимо восстановить содержимое БД по содержимому журналов транзакций, хранящихся на дисках. Для восстановления согласованного состояния БД при жестком сбое надо восстановить содержимое БД по архивным копиям и журналам транзакций, которые хранятся на неповрежденных внешних носителях. Во всех трех случаях основой восстановления является избыточное хранение данных. Эти избыточные данные хранятся в журнале, содержащем последовательность записей об изменении базы данных. Возможны два основных варианта ведения журнальной информации. В первом варианте для каждой транзакции поддерживается отдельный локальный журнал изменений базы данных этой транзакцией. Такие журналы называются локальными журналами. Они используются для индивидуальных откатов транзакций и могут поддерживаться в оперативной (правильнее сказать, в виртуальной) памяти. Кроме того, поддерживается общий журнал изменений базы данных, используемый для восстановления состояния базы данных после мягких и жестких сбоев. Этот подход позволяет быстро выполнять индивидуальные откаты транзакций, но приводит к дублированию информации в локальных и общем журналах. Поэтому чаще используется второй вариант — поддержание только общего журнала изменений базы данных, который используется и при выполнении индивидуальных откатов. Далее мы рассматриваем именно этот вариант. Общая структура журнала условно может быть представлена в виде некоторого последовательного файла, в котором фиксируется каждое изменение БД, которое происходит в ходе выполнения транзакции. Все транзакции имеют свои внутренние номера, поэтому в едином журнале транзакций фиксируются все изменения, проводимые всеми транзакциями. Каждая запись в журнале транзакций помечается номером транзакции, к которой она относится, и значениями атрибутов, которые она меняет. Кроме того, для каждой транзакции в журнале фиксируется команда начала и завершения транзакции (приложение 1). Для большей надежности журнал транзакций часто дублируется системными средствами коммерческих СУБД, именно поэтому объем внешней памяти во много раз превышает реальный объем данных, которые хранятся в хранилище. Имеются два альтернативных варианта ведения журнала транзакций: протокол с отложенными обновлениями и протокол с немедленными обновлениями. Ведение журнала по принципу отложенных изменений предполагает следующий механизм выполнения транзакций: Когда транзакция Т1 начинается, в протокол заносится запись <Т1 Begin transaction> На протяжении выполнения транзакции в протоколе для каждой изменяемой записи записывается новое значение: <T1,ID_RECORD, атрибут, новое значение … >. Здесь ID_RECORD — уникальный номер записи. Если все действия, из которых состоит транзакция Т1, успешно выполнены, то транзакция частично фиксируется и в протокол заносится <Т1 COMMIT>. После того как транзакция фиксирована, записи протокола, относящиеся к T1, используются для внесения соответствующих изменений в БД. Если происходит сбой, то СУБД просматривает протокол и выясняет, какие транзакции необходимо переделать. Транзакцию Т1 необходимо переделать, если протокол содержит обе записи <T1 BEGIN TRANSACTION> и <T1 COMMIT>. БД может находиться в несогласованном состоянии, однако все новые значения измененных элементов данных содержатся в протоколе, и это требует повторного выполнения транзакции. Для этого используется некоторая системная процедура REDO(), которая заменяет все значения элементов данных на новые, просматривая протокол в прямом порядке. Если в протоколе не содержится команда фиксации транзакции COMMIT, то никаких действий проводить не требуется, а транзакция запускается заново. Альтернативный механизм с немедленным выполнением предусматривает внесение изменений сразу в БД, а в протокол заносятся не только новые, но и все старые значения изменяемых атрибутов, поэтому каждая запись выглядит <Т1, IDRECORD, атрибут новое значение старое значение …>. При этом запись в журнал предшествует непосредственному выполнению операции над БД. Когда транзакция фиксируется, то есть встречается команда <T1 COMMIT> и она выполняется, то все изменения оказываются уже внесенными в БД и не требуется никаких дальнейших действий по отношению к этой транзакции. При откате транзакции выполняется системная процедура UNDO(), которая возвращает все старые значения в отмененной транзакции, последовательно проходя по протоколу начиная с команды BEGIN TRANSACTION. Для восстановления при сбое используется следующий механизм: Если транзакция содержит команду начала транзакции, но не содержит команды фиксации с подтверждением ее выполнения, то выполняется последовательность действий как при откате транзакции, то есть восстанавливаются старые значения. Если сбой произошел после выполнения последней команды изменения БД, но до выполнения команды фиксации, то команда фиксации выполняется, а с БД никаких изменений не происходит. Работа происходит только на уровне протокола. Однако следует отметить, что проблемы восстановления выглядят гораздо сложнее приведенных ранее алгоритмов, с учетом того, что изменения как в журнал, так и в БД заносятся не сразу, а буферируются. Журнализация изменений тесно связана не только с управлением транзакциями, но и с буферизацией страниц базы данных в оперативной памяти. Если бы запись об изменении базы данных, которая должна поступить в журнал при выполнении любой операции модификации базы данных, реально немедленно записывалась бы во внешнюю память, это привело бы к существенному замедлению работы системы. Поэтому записи в журнале тоже буферизуются: при нормальной работе очередная страница выталкивается во внешнюю память журнала только при полном заполнении записями. Проблема состоит в выработке некоторой общей политики выталкивания, которая обеспечивала бы возможность восстановления состояния базы данных после сбоев. Проблема не возникает при индивидуальных откатах транзакций, поскольку в этих случаях содержимое оперативной памяти не утрачено и можно пользоваться содержимым как буфера журнала, так и буферов страниц базы данных. Но если произошел мягкий сбой и содержимое буферов утрачено, для проведения восстановления базы данных необходимо иметь некоторое согласованное состояние журнала и базы данных во внешней памяти. Основным принципом согласованной политики выталкивания буфера журнала и буферов страниц базы данных является то, что запись об изменении объекта базы данных должна попадать во внешнюю память журнала раньше, чем измененный объект оказывается во внешней памяти базы данных. Соответствующий протокол журнализации (и управления буферизацией) называется Write Ahead Log (WAL) — "пиши сначала в журнал" и состоит в том, что если требуется записать во внешнюю память измененный объект базы данных, то перед этим нужно гарантировать запись во внешнюю память журнала транзакций записи о его изменении. Другими словами, если во внешней памяти базы данных находится некоторый объект базы данных, по отношению к которому выполнена операция модификации, то во внешней памяти журнала обязательно находится запись, соответствующая этой операции. Обратное неверно, то есть если во внешней памяти журнале содержится запись о некоторой операции изменения объекта базы данных, то сам измененный объект может отсутствовать во внешней памяти базы данных. Дополнительное условие на выталкивание буферов накладывается тем требованием, что каждая успешно завершившаяся транзакция должна быть реально зафиксирована во внешней памяти. Какой бы сбой не произошел, система должна быть в состоянии восстановить состояние базы данных, содержащее результаты всех зафиксированных к моменту сбоя транзакций. Простым решением было бы выталкивание буфера журнала, за которым следует массовое выталкивание буферов страниц базы данных, изменявшихся данной транзакцией. Довольно часто так и делают, но это вызывает существенные накладные расходы при выполнении операции фиксации транзакции. Оказывается, что минимальным требованием, гарантирующим возможность восстановления последнего согласованного состояния базы данных, является выталкивание при фиксации транзакции во внешнюю память журнала всех записей об изменении базы данных этой транзакцией. При этом последней записью в журнал, производимой от имени данной транзакции, является специальная запись о конце транзакции.
1.3 Индивидуальный откат транзакции. Восстановление после мягкого сбоя
Для того чтобы можно было выполнить по общему журналу индивидуальный откат транзакции, все записи в журнале по данной транзакции связываются в обратный список. Началом списка для незакончившихся транзакций является запись о последнем изменении базы данных, произведенном данной транзакцией. Для закончившихся транзакций (индивидуальные откаты которых уже невозможны) началом списка является запись о конце транзакции, которая обязательно вытолкнута во внешнюю память журнала. Концом списка всегда служит первая запись об изменении базы данных, произведенном данной транзакцией. Обычно в каждой записи проставляется уникальный идентификатор транзакции, чтобы можно было восстановить прямой список записей об изменениях базы данных данной транзакцией. Индивидуальный откат транзакции выполняется следующим образом: Выбирается очередная запись из списка данной транзакции. Выполняется противоположная по смыслу операция: вместо операции INSERT выполняется соответствующая операция DELETE, вместо операции DELETE выполняется INSERT и вместо прямой операции UPDATE обратная операция UPDATE, восстанавливающая предыдущее состояние объекта базы данных. Любая из этих обратных операций также заносится в журнал. Собственно, для индивидуального отката это не нужно, но при выполнении индивидуального отката транзакции может произойти мягкий сбой, при восстановлении после которого потребуется откатить такую транзакцию, для которой не полностью выполнен индивидуальный откат. При успешном завершении отката в журнал заносится запись о конце транзакции. С точки зрения журнала такая транзакция является зафиксированной. К числу основных проблем восстановления после мягкого сбоя относится то, что одна логическая операция изменения базы данных может изменять несколько физических блоков базы данных, например, страницу данных и несколько страниц индексов. Страницы базы данных буферизуются в оперативной памяти и выталкиваются независимо. Несмотря на применение протокола WAL, после мягкого сбоя набор страниц внешней памяти базы данных может оказаться несогласованным, то есть часть страниц внешней памяти соответствует объекту до изменения, часть — после изменения. К такому состоянию объекта неприменимы операции логического уровня. Состояние внешней памяти базы данных называется физически согласованным, если наборы страниц всех объектов согласованы, то есть соответствуют состоянию объекта, либо до его изменения, либо после изменения. В журнале отмечаются точки физической согласованности базы данных — моменты времени, в которые во внешней памяти содержатся согласованные результаты операций, завершившихся до соответствующего момента времени, и отсутствуют результаты операций, которые не завершились, а буфер журнала вытолкнут во внешнюю память. Немного позже мы рассмотрим, как можно достичь физической согласованности. Назовем такие точки tpc (time of physical consistency) — точками физического согласования. Тогда к моменту мягкого сбоя возможны следующие состояния транзакций: транзакция успешно завершена, то есть, выполнена операция подтверждения транзакции COMMIT и для всех операций транзакции получено подтверждение ее выполнения во внешней памяти; транзакция успешно завершена, но для некоторых операций не получено подтверждение их выполнения во внешней памяти; транзакция получила и выполнила команду отката ROLLBACK; транзакция не завершена.
1.4 Физическая согласованность базы данных. Восстановление после жесткого сбоя
При открытии файла таблица отображения номеров его логических блоков в адреса физических блоков внешней памяти считывается в оперативную память. При модификации любого блока файла во внешней памяти выделяется новый блок. При этом текущая таблица отображения (в оперативной памяти) изменяется, а теневая — сохраняется неизменной. Если во время работы с открытым файлом происходит сбой, во внешней памяти автоматически сохраняется состояние файла до его открытия. Для явного восстановления файла достаточно повторно считать в оперативную память теневую таблицу отображения. Общая идея теневого механизма показана на рис. 3. 
Рисунок 3 - Использование теневых таблиц отображения информации
В контексте базы данных теневой механизм используется следующим образом. Периодически выполняются операции установления точки физической согласованности базы данных (checkpoints). Для этого все логические операции завершаются, все буферы оперативной памяти, содержимое которых не соответствует содержимому соответствующих страниц внешней памяти, выталкиваются. Теневая таблица отображения файлов базы данных заменяется на текущую. Восстановление происходит мгновенно: текущая таблица отображения заменяется на теневую (при восстановлении просто считывается теневая таблица отображения). Все проблемы восстановления решаются, но за счет слишком большого перерасхода внешней памяти. В пределе может потребоваться вдвое больше внешней памяти, чем реально нужно для хранения базы данных. Теневой механизм — это надежное, но слишком грубое средство. Обеспечивается согласованное состояние внешней памяти в один общий для всех объектов момент времени. На самом деле достаточно иметь совокупность согласованных наборов страниц, каждому из которых может соответствовать свои временные отсчеты. Для выполнения такого более слабого требования наряду с логической журнализацией операций изменения базы данных производится журнализация постраничных изменений. Первый этап восстановления после мягкого сбоя состоит в постраничном откате незакончившихся логических операций. Подобно тому, как это делается с логическими записями по отношению к транзакциям, последней записью о постраничных изменениях от одной логической операции является запись о конце операции. В этом подходе имеются два метода решения проблемы. При использовании первого метода поддерживается общий журнал логических и страничных операций. Естественно, наличие двух видов записей, интерпретируемых абсолютно по-разному, усложняет структуру журнала. Кроме того, записи о постраничных изменениях, актуальность которых носит локальный характер, существенно (и не очень осмысленно) увеличивают журнал. Поэтому все более популярным становится поддержание отдельного (короткого) журнала постраничных изменений. Такая техника применяется, например, в известном продукте Informix Online. Предположим, что некоторым способом удалось восстановить внешнюю память базы данных к состоянию на момент времени tpc (как это можно сделать — немного позже). Тогда: Для транзакции T1 никаких действий производить не требуется. Она закончилась до момента tpc, и все ее результаты отражены во внешней памяти базы данных. Для транзакции T2 нужно повторно выполнить оставшуюся часть операций (redo). Действительно, во внешней памяти полностью отсутствуют следы операций, которые выполнялись в транзакции T2 после момента tpc. Следовательно, повторная прямая интерпретация операций T2 корректна и приведет к логически согласованному состоянию базы данных (поскольку транзакция T2 успешно завершилась до момента мягкого сбоя, в журнале содержатся записи обо всех изменениях, произведенных этой транзакцией). Для транзакции T3 нужно выполнить в обратном направлении первую часть операций (undo). Действительно, во внешней памяти базы данных полностью отсутствуют результаты операций T3, которые были выполнены после момента tpc. С другой стороны, во внешней памяти гарантированно присутствуют результаты операций T3, которые были выполнены до момента tpc. Следовательно, обратная интерпретация операций T3 корректна и приведет к согласованному состоянию базы данных (поскольку транзакция T3 не завершилась к моменту мягкого сбоя, при восстановлении необходимо устранить все последствия ее выполнения). Для транзакции T4, которая успела начаться после момента tpc и закончиться до момента мягкого сбоя, нужно выполнить полную повторную прямую интерпретацию операций (redo). Наконец, для начавшейся после момента tpc и не успевшей завершиться к моменту мягкого сбоя транзакции T5 никаких действий предпринимать не требуется. Результаты операций этой транзакции полностью отсутствуют во внешней памяти базы данных. Понятно, что для восстановления последнего согласованного состояния базы данных после жесткого сбоя журнала изменений базы данных явно недостаточно. Основой восстановления в этом случае являются журнал и архивная копия базы данных. Восстановление начинается с обратного копирования базы данных из архивной копии. Затем для всех закончившихся транзакций выполняется redo, то есть операции повторно выполняются в прямом порядке. Более точно, происходит следующее: по журналу в прямом направлении выполняются все операции; для транзакций, которые не закончились к моменту сбоя, выполняется откат. На самом деле, поскольку жесткий сбой не сопровождается утратой буферов оперативной памяти, можно восстановить базу данных до такого уровня, чтобы можно было продолжить даже выполнение незакончившихся транзакций. Но обычно это не делается, потому, что восстановление после жесткого сбоя — это достаточно длительный процесс. Хотя к ведению журнала предъявляются особые требования по части надежности, в принципе возможна и его утрата. Тогда единственным способом восстановления базы данных является возврат к архивной копии. Конечно, в этом случае не удастся получить последнее согласованное состояние базы данных, но это лучше, чем ничего. Самый простой способ — архивировать базу данных при переполнении журнала. В журнале вводится так называемая "желтая зона", при достижении которой образование новых транзакций временно блокируется. Когда все транзакции закончатся и, следовательно, база данных придет в согласованное состояние, можно производить ее архивацию, после чего начинать заполнять журнал заново. Можно выполнять архивацию базы данных реже, чем переполняется журнал. При переполнении журнала и окончании всех начатых транзакций можно архивировать сам журнал. Поскольку такой архивированный журнал, по сути дела, требуется только для воссоздания архивной копии базы данных, журнальная информация при архивации может быть существенно сжата.
1.5 Параллельное выполнение транзакций. Уровни изолированности пользователей
Если с БД работают одновременно несколько пользователей, то обработка транзакций должна рассматриваться с новой точки зрения. В этом случае СУБД должна не только корректно выполнять индивидуальные транзакции и восстанавливать согласованное состояние БД после сбоев, но она призвана обеспечить корректную параллельную работу всех пользователей над одними и теми же данными. По теории каждый пользователь и каждая транзакция должны обладать свойством изолированности, то есть они должны выполняться так, как если бы только один пользователь работал с БД. И средства современных СУБД позволяют изолировать пользователей друг от друга именно таким образом. Однако в этом случае возникают проблемы замедления работы пользователей. Рассмотрим более подробно проблемы, которые возникают при параллельной обработке транзакций. Основные проблемы, которые возникают при параллельном выполнении транзакций, делятся условно на 4 типа: Пропавшие изменения. Эта ситуация может возникать, если две транзакции одновременно изменяют одну и ту же запись в БД. Например, работают два оператора на приеме заказов, первый оператор принял заказ на 30 мониторов. Когда он запрашивал склад, то там числилось 40 мониторов, и он, получив подтверждение от клиента, выставил счет и оформил продажу 30 мониторов из 40. Параллельно с ним работает второй оператор, который принимает заказ на 20 таких же мониторов (ну уж очень хорошая модель и дешево) и, в свою очередь запросив состояние склада и получив исходно ту же цифру 40, он успешно оформляет заказ для своего клиента. Заканчивая работу с данным заказом, он выполняет команду Обновить(UPDATE), которая заносит 20 как остаток любимых мониторов на складе. Но после этого, наконец, любезно попрощавшись со своим клиентом и заверив его в скорейшей доставке заказанных мониторов, заканчивает работу со своим заказом первый оператор и также выполняет команду Обновитьи заносит 10 как остаток тех же мониторов на складе. Каждый из них доволен своей работой, но мы-то знаем, что произошло. Прежде всего, они продали 50 мониторов из наличествующих 40 штук, и далее на складе еще числится 10 подобных мониторов. БД теперь находится в несогласованном состоянии, а у фирмы возникли серьезные проблемы. Изменения, сделанные вторым оператором, были проигнорированы программой выполнения заказа, с которой работал первый оператор. Подобная ситуация представлена на рис.4 Проблемы промежуточных данных. Рассмотрим ту же проблему одновременной работы двух операторов. Допустим, первый оператор, ведя переговоры со своим заказчиком, ввел заказанные 30 мониторов, но перед окончательным оформлением заказа клиент захотел выяснить еще некоторые характеристики товара. Приложение, с которым работает первый оператор, уже изменило остаток мониторов на складе, и там сейчас находится информация о 10 оставшихся мониторах. В это время второй оператор пытается принять заказ от своего клиента на 20 мониторов, но его приложение показывает, что на складе осталось всего 10 мониторов, и оператор вынужден отказать выгодному клиенту, который идет в другую фирму, весьма неудовлетворенный работой нашей компании. А в этот момент клиент оператора 1 заканчивает обсуждение дополнительных характеристик наших мониторов и принимает весьма невыгодное решение не покупать у нас мониторы, и приложение оператора 1 выполняет откат транзакции, и на складе снова оказывается 40 мониторов. Мы потеряли выгодного заказчика, но еще хуже было бы, если бы клиент второго оператора согласился на 10 оставшихся мониторов, и приложение, с которым работает оператор два, отработав свой алгоритм, занесло 0 (ноль) оставшихся мониторов на складе, а после этого приложение оператора один снова бы записало исходные 40 мониторов на складе, хотя 10 их них уже проданы. Такая ситуация оказалась возможной потому, что приложение второго оператора имело доступ к промежуточным данным, которые сформировало первое приложение. 
Рисунок 4 - Проблема пропавших обновлений
Проблемы несогласованных данных. Рассмотрим ту же самую ситуацию с заказом мониторов. Предположим, что ситуация несколько изменилась. И оба оператора начинают работать практически одновременно. Они оба получают начальное состояние склада 40 мониторов, а далее первый оператор успешно завершает переговоры со своим клиентом и продает ему 30 мониторов. Он завершает работу своего приложения, и оно выполняет команду фиксации транзакции COMMIT. Состояние базы данных непротиворечивое. В этот момент, выяснив все тонкости и характеристики наших мониторов, клиент второго оператора также решает сделать заказ, и второй оператор, повторно получая состояние склада, видит, что оно изменилось. База данных находится в непротиворечивом состоянии, но второй оператор считает, что нарушена целостность его транзакции, в течение выполнения одной работы он получил два различных состояния склада. Эта ситуация возникла потому, что приложение первого оператора смогло изменить кортеж с данными, который уже прочитало приложение второго оператора. Проблемы строк-призраков (строк-фантомов). Предположим, что администратор нашей фирмы поручил секретарю напечатать итоговый отчет по результатам работы за текущий месяц. И допустим, что приложение печатает отчет в двух видах: в подробном и в укрупненном. В момент, когда приложение печати начало формировать свой первый вид отчета, один из операторов принимает еще один заказ, поэтому к моменту формирования укрупненного отчета в БД появились новые сведения о продажах, которые и были внесены в укрупненный отчет. Мы получили два отчета в одном приложении, которые содержат разные цифры и не совпадают друг с другом. Такое стало возможно потому, что приложение печати выполнило два одинаковых запроса и получило два разных результата. БД находится в согласованном состоянии, но приложение печати работает некорректно. Для того чтобы избежать подобных проблем, требуется выработать некоторую процедуру согласованного выполнения параллельных транзакций. Эта процедура должна удовлетворять следующим правилам: В ходе выполнения транзакции пользователь видит только согласованные данные. Пользователь не должен видеть несогласованных промежуточных данных. Когда в БД две транзакции выполняются параллельно, то СУБД гарантированно поддерживает принцип независимого выполнения транзакций, который гласит, что результаты выполнения транзакций будут такими же, как если бы вначале выполнялась транзакция 1, а потом транзакция 2, или наоборот, сначала транзакция 2, а потом транзакция 1. Такая процедура называется сериализацией транзакций. Фактически она гарантирует, что каждый пользователь (программа), обращающаяся к базе данных, работает с ней так, как будто не существует других пользователей (программ), одновременно с ним обращающихся к тем же данным. Для поддержки параллельной работы транзакций строится специальный план. План (способ) выполнения набора транзакций называется сериальным, если результат совместного выполнения транзакций эквивалентен результату некоторого последовательного выполнения этих же транзакций. Самым простым было бы последовательное выполнение транзакций, но такой план не оптимален по времени, существуют более гибкие методы управления параллельным доступом к БД. Наиболее распространенным механизмом, который используется коммерческими СУБД для реализации на практике сериализации транзакций является механизм блокировок. Самый простой вариант — это блокировка объекта на все время действия транзакции. Подобный пример рассмотрен на рис.5. Здесь две транзакции, названные условно А и В, работают с тремя таблицами: Т1, Т2 и Т3. В момент начала работы с любым объектом этот объект блокируется транзакцией, которая с ним начала работу, и он становится недоступным всем другим транзакциям до окончания транзакции, заблокировавшей ("захватившей") данный объект. После окончания транзакции все заблокированные ею объекты разблокируются и становятся доступными другим транзакциям. Если транзакция обращается к заблокированному объекту, то она остается в состоянии ожидания до момента разблокировки этого объекта, после чего она может продолжать обработку данного объекта. Поэтому транзакция. В ожидает разблокировки таблицы Т2 транзакцией А. Над прямоугольниками стоит условное время выполнения операций. 
Рисунок 5 - Блокировки при одновременном выполнении двух транзакций
В общем случае на момент выполнения транзакция получает как бы монопольный доступ к объектам БД, с которыми она работает. В этом случае другие транзакции не получают доступа к объектам БД до момента окончания транзакции. Такой механизм действительно ликвидирует все перечисленные ранее проблемы: пропавшие изменения, неподтвержденные данные, несогласованные данные, строки-фантомы. Однако такая блокировка создает новые проблемы — задержку выполнения транзакций из-за блокировок. Рассмотрим существующие типы конфликтов между двумя параллельными транзакциями. Можно выделить следующие типы: W-W — транзакция 2 пытается изменять объект, измененный незакончившейся транзакцией 1; R-W — транзакция 2 пытается изменять объект, прочитанный незакончившейся транзакцией 1; W-R — транзакция 2 пытается читать объект, измененный незакончившейся транзакцией 1. Практические методы сериализации транзакций основываются на учете этих конфликтов. Блокировки, называемые также синхронизационными захватами объектов, могут быть применены к разному типу объектов. Наибольшим объектом блокировки может быть вся БД, однако этот вид блокировки сделает БД недоступной для всех приложений, которые работают с данной БД. Следующий тип объекта блокировки — это таблицы. Транзакция, которая работает с таблицей, блокирует ее на все время выполнения транзакции. Именно такой вид блокировки рассмотрен в таблице 1. Этот вид блокировки предпочтительнее предыдущего, потому что позволяет параллельно выполнять транзакции, которые работают с другими таблицами. В ряде СУБД реализована блокировка на уровне страниц. В этом случае СУБД блокирует только отдельные страницы на диске, когда транзакция обращается к ним. Этот вид блокировки еще более мягок и позволяет разным транзакциям работать даже с одной и той же таблицей, если они обращаются к разным страницам данных. В некоторых СУБД возможна блокировка на уровне строк, однако такой механизм блокировки требует дополнительных затрат на поддержку этого вида блокировки. В настоящее время проблема блокировок является предметом большого числа исследований. Для повышения параллельности выполнения транзакций используется комбинирование разных типов синхронизационных захватов. Рассматривают два типа блокировок (синхронизационных захватов): совместный режим блокировки — нежесткая, или разделяемая, блокировка, обозначаемая как S (Shared). Этот режим обозначает разделяемый захват объекта и требуется для выполнения операции чтения объекта. Объекты, заблокированные таким образом, не изменяются в ходе выполнения транзакции и доступны другим транзакциям также, но только в режиме чтения; монопольный режим блокировки — жесткая, или эксклюзивная, блокировка, обозначаемая как X (eXclusive). Данный режим блокировки предполагает монопольный захват объекта и требуется для выполнения операций занесения, удаления и модификации. Объекты, заблокированные данным типом блокировки, фактически остаются в монопольном режиме обработки и недоступны для других транзакций до момента окончания работы данной транзакции. Захваты объектов несколькими транзакциями по чтению совместимы, то есть нескольким транзакциям допускается читать один и тот же объект, захват объекта одной транзакцией по чтению не совместим с захватом другой транзакцией того же объекта по записи, и захваты одного объекта разными транзакциями по записи не совместимы. Правила совместимости захватов одного объекта разными транзакциями изображены на Таблице 1:  Таблица 1 - Правила применения жесткой и нежесткой блокировок транзакций
В примере, представленном на таблице 1 считается, что первой блокирует объект транзакция А, а потом пытается получить к нему доступ транзакция В. На рис. 6 приведен ранее рассмотренный пример с выполнением транзакций 1 и 2, но с учетом разных типов блокировки. На рисунке видно, что, применив нежесткую блокировку к таблице 2 со стороны транзакции 1, мы обеспечили существенное уменьшение времени выполнения транзакции 2. Теперь транзакция 2 не ждет окончания транзакции 1, и поэтому завершает свою работу, намного раньше.  Рисунок 6 - Использование жесткой и нежесткой блокировки
К сожалению, применения разных типов блокировок приводит к проблеме тупиков. Эта проблема не нова. Проблема тупиков возникла при рассмотрении выполнения параллельных процессов в операционных средах и также была связана с управлением разделяемыми (совместно используемыми) ресурсами. Действительно, рассмотрим пример. Пусть транзакция А сначала жестко блокирует таблицу 1, а потом жестко блокирует таблицу 2. Транзакция B, наоборот, сначала жестко блокирует таблицу 2, а потом жестко блокирует таблицу 1. Если обе эти транзакции начали работу одновременно, то после выполнения операций модификации первыми объектами каждой транзакции они обе окажутся в бесконечном ожидании: транзакция А будет ждать завершения работы транзакции B и разблокировки таблицы 2, а транзакция В также безрезультатно будет ждать окончания работы транзакции А и разблокировки таблицы 1 (Рисунок 7).  Рисунок 7 - Взаимная блокировка транзакций
Ситуации могут быть гораздо более сложными. Количество взаимно заблокированных транзакций может оказаться гораздо больше. Эту ситуацию каждая из транзакций обнаружить самостоятельно не может. Ее должна разрешить СУБД. И действительно, в большинстве коммерческих СУБД существует механизм обнаружения таких тупиковых ситуаций. Основой обнаружения тупиковых ситуаций является построение (или постоянное поддержание) графа ожидания транзакций. Граф ожидания транзакций может строиться двумя способами. Если транзакция А ждет окончания транзакции В, то из вершины А в вершину В идет стрелка. Дополнительно стрелки могут быть помечены именами заблокированных объектов и типом блокировки. Пример такого графа ожиданий приведен на рисунке 8. Граф ожиданий построен для транзакций Т1, Т2,___,Т12, которые работают с объектами БД A,В,...,Н. Перечень действий, которые совершают транзакции над объектами, приведен в таблице 1.  Рисунок 8 - Пример графа ожиданий транзакций | Время | Транзакция | Действие | | 0 | T1 | Select A | | 1 | T2 | Select B | | 2 | T1 | Select C | | 3 | T4 | Select D | | 4 | T5 | Select A | | 5 | T2 | Select E | | 6 | T2 | Update E | | 7 | T3 | Select F | | 8 | T2 | Select F | | 9 | T5 | Update A | | 10 | T1 | Commit | | 11 | T6 | Select A | | 12 | T5 | Commit | | 13 | T6 | Select C | | 14 | T6 | Update C | | 15 | T7 | Select G | | 16 | T8 | Select H | | 17 | T9 | Select G | | 18 | T9 | Update G | | 19 | T8 | Select E | | 20 | T7 | Commit | | 21 | T9 | Select H | | 22 | T3 | Select G | | 23 | T10 | Select A | | 24 | T9 | Update H | | 25 | T6 | Commit | | 26 | T11 | Select C | | 27 | T12 | Select D | | 28 | T12 | Select C | | 29 | T2 | Update F | | 30 | T11 | Update C | | 31 | T12 | Select A | | 32 | T10 | Update A | | 33 | T12 | Update D | | 34 | T2 | Select G | | 35 | - | - |
Таблица 2 - Перечень действий множества транзакций
На графе объекты блокировки помечены типами блокировок, S — нежесткая (разделяемая) блокировка, X — жесткая (эксклюзивная) блокировка. На диаграмме состояний ожидания видно, что транзакции Т9, Т8, Т2 и Т3 образуют цикл. Именно наличие цикла и является признаком возникновения тупиковой ситуации. Поэтому в момент 3 перечисленные транзакции будут заблокированы. Разрушение тупика начинается с выбора в цикле транзакций так называемой транзакции-жертвы, то есть транзакции, которой решено пожертвовать, чтобы обеспечить возможность продолжения работы других транзакций. Критерием выбора является стоимость транзакции; жертвой выбирается самая дешевая транзакция. Стоимость транзакции определяется на основе многофакторной оценки, в которую с разными весами входят время выполнения, число накопленных захватов, приоритет. После выбора транзакции-жертвы выполняется откат этой транзакции, который может носить полный или частичный характер. При этом, естественно, освобождаются захваты и может быть продолжено выполнение других транзакций. Для распознавания тупика здесь, так же как и в первом методе, производится построение графа ожидания транзакций и в этом графе ищутся циклы. Традиционной техникой (для которой существует множество разновидностей) нахождения циклов в ориентированном графе является редукция графа. Не вдаваясь в детали, редукция состоит в том, что, прежде всего из графа ожидания удаляются все дуги, исходящие из вершин-транзакций, в которые не входят дуги из вершин-объектов. (Это как бы соответствует той ситуации, что транзакции, не ожидающие удовлетворения захватов, успешно завершились и освободили захваты.) Для тех вершин-объектов, для которых не осталось входящих дуг, но существуют исходящие, ориентация исходящих дуг изменяется на противоположную (это моделирует удовлетворение захватов). После этого снова срабатывает первый шаг, и так до тех пор, пока на первом шаге не прекратится удаление дуг. Если в графе остались дуги, то они обязательно образуют цикл. Естественно, такое насильственное устранение тупиковых ситуаций является нарушением принципа изолированности пользователей. Заметим, что в централизованных системах стоимость построения графа ожидания сравнительно невелика, но она становится слишком большой в по-настоящему распределенных СУБД, в которых транзакции могут выполняться в разных узлах сети. Поэтому в таких системах обычно используются другие методы сериализации транзакций. Для обеспечения сериализации транзакций синхронизационные захваты объектов, произведенные по инициативе транзакции, можно снимать только при ее завершении. Это требование порождает двухфазный протокол синхронизационных захватов — 2PL(two phase lock) или 2PC (two phase commit). В соответствии с этим протоколом выполнение транзакции разбивается на две фазы: первая фаза транзакции — накопление захватов; вторая фаза (фиксация или откат) — освобождение захватов. Достаточно легко убедиться, что при соблюдении двухфазного протокола синхронизационных захватов действительно обеспечивается полная сериализация транзакций. Однако иногда приложению, которое выполняет транзакцию, не столько важны точные данные, сколько скорость выполнения запросов. Например, в системах поддержки принятия решений по электронным торгам важно просто иметь представление об общей картине торгов, на основании которого принимается решение о повышении или снижении ставок и т. д. Для смягчения требований сериализации транзакций вводится понятие уровня изолированности пользователя. Уровни изолированности пользователей связаны с проблемами, которые возникают при параллельном выполнении транзакций и которые были рассмотрены нами ранее. Всего введено 4 уровня изолированности пользователей. Самый высокий уровень изолированности соответствует протоколу сериализации транзакций, это уровень SERIALIZABLE. Этот уровень обеспечивает полную изоляцию транзакций и полную корректную обработку параллельных транзакций. Следующий уровень изолированности называется уровнем подтвержденного чтения — REPEATABLE READ. На этом уровне транзакция не имеет доступа к промежуточным или окончательным результатам других транзакций, поэтому такие проблемы, как пропавшие обновления, промежуточные или несогласованные данные, возникнуть не могут. Однако во время выполнения своей транзакции можно увидеть строку, добавленную в БД другой транзакцией. Поэтому один и тот же запрос, выполненный в течение одной транзакции, может дать разные результаты, то есть проблема строк-призраков остается. Однако если такая проблема критична, лучше ее разрешать алгоритмически, изменяя алгоритм обработки, исключая повторное выполнение запроса в одной транзакции. Второй уровень изолированности связан с подтвержденным чтением, он называется READ COMMITED. На этом уровне изолированности транзакция не имеет доступа к промежуточным результатам других транзакций, поэтому проблемы пропавших обновлений и промежуточных данных возникнуть не могут. Однако окончательные данные, полученные в ходе выполнения других транзакций, могут быть доступны нашей транзакции. При этом уровне изолированности транзакция не может обновлять строку, уже обновленную другой транзакцией. При попытке выполнить подобное обновление транзакция будет отменена автоматически, во избежание возникновения проблемы пропавшего обновления. Самый низкий уровень изолированности называется уровнем неподтвержденного, или грязного, чтения. Он обозначается как READ UNCOMMITED. При этом уровне изолированности текущая транзакция видит промежуточные и несогласованные данные, и также ей доступны строки-призраки. Однако даже при этом уровне изолированности СУБД предотвращает пропавшие обновления. 1.6 Гранулированные синхронизационные захваты. Предикатные синхронизационные захваты
Мы уже говорили, что объектами блокирования могут быть объекты разного уровня, начиная с целой БД и заканчивая кортежем. Понятно, что чем крупнее объект синхронизационного захвата (неважно, какой природы этот объект — логический или физический), тем меньше синхронизационных захватов будет поддерживаться в системе, и при этом, соответственно, будут меньшие накладные расходы. Более того, если выбрать в качестве уровня объектов для захватов файл или отношение, то будет решена даже проблема фантомов. Но вся беда в том, что при использовании для захватов крупных объектов возрастает вероятность конфликтов транзакций и тем самым уменьшается допускаемая степень их параллельного выполнения. Фактически при укрупнении объекта синхронизационного захвата мы умышленно огрубляем ситуацию и видим конфликты в тех ситуациях, когда на самом деле конфликтов нет. Действительно, если транзакция Т1 обрабатывает первую, пятую и двадцатую строку в таблице R1, но блокирует всю таблицу, то транзакция T2, которая обрабатывает шестую и восьмую строки той же таблицы не сможет получить к ним доступ, хотя на уровне строк никаких конфликтов нет. В большинстве современных систем используются покортежные, то есть построковые синхронизационные захваты. Однако нелепо было бы применять покортежную блокировку в случае выполнения, например, операции удаления всего отношения или удаления всех строк в отношении. Подобные рассуждения привели к понятию гранулированных синхронизационных захватов и разработке соответствующего механизма. При применении этого подхода синхронизационные захваты могут запрашиваться по отношению к объектам разного уровня: файлам, отношениям и кортежам. Требуемый уровень объекта определяется тем, какая операция выполняется (например, для выполнения операции уничтожения отношения объектом синхронизационного захвата должно быть все отношение, а для выполнения операции удаления кортежа — этот кортеж). Объект любого уровня может быть захвачен в режиме S(разделяемом) или X(монопольном). Вводится специальный протокол гранулированных захватов и определены новые типы захватов: перед захватом объекта в режиме Sили Xсоответствующий объект более высокого уровня должен быть захвачен в режиме IS, IX или SIX. IS(Intented for Shared lock, предваряющий разделяемую блокировку) по отношению к некоторому составному объекту Oозначает намерение захватить некоторый входящий в Oобъект в совместном режиме. Например, при намерении читать кортежи из отношения Rэто отношение должно быть захвачено в режиме IS(а до этого в таком же режиме должен быть захвачен файл). IX(Intented for eXclusive lock, предваряющий жесткую блокировку) по отношению к некоторому составному объекту Oозначает намерение захватить некоторый входящий в Oобъект в монопольном режиме. Например, при намерении удалять кортежи из отношения Rэто отношение должно быть захвачено в режиме IX(а до этого в таком же режиме должен быть захвачен файл). SIX(Shared, Intented for eXclusive lock, разделяемая блокировка объекта, предваряющая дальнейшие жесткие блокировки его составляющих) по отношению к некоторому составному объекту O означает совместный захват всего этого объекта с намерением впоследствии захватывать какие-либо входящие в него объекты в монопольном режиме. Например, если выполняется длинная операция просмотра отношения с возможностью удаления некоторых просматриваемых кортежей, то экономичнее всего захватить это отношение в режиме SIX(а до этого захватить файл в режиме IS). Приведем полную таблицу совместимости захватов, анализируя которую можно выявить все случаи (таблица 3). | L1\L2 | X | S | IX | IS | SIX | | Нет блокировки | Да | Да | Да | Да | Да | | X | Нет | Нет | Нет | Нет | Нет | | S | Нет | Да | Нет | Да | Нет | | IX | Нет | Нет | Да | Да | Нет | | IS | Нет | Да | Да | Да | Да | | SIX | Нет | Нет | Нет | Да | Нет |
Таблица 3 - Матрица совместимости блокировок.
Протокол гранулированных захватов требует соблюдения следующих правил: Прежде чем транзакция установит S-блокировку на данный кортеж, она должна установить блокировку IS или другую, более сильную блокировку на отношение, в котором содержится данный кортеж. Прежде чем транзакция установит Х-блокировку на данный кортеж, она должна установить IX-блокировку или другую более сильную блокировку на отношение, в которое входит кортеж. Блокировка L1 называется более сильной по отношению к блокировке L2 тогда и только тогда, когда для любой конфликтной ситуации (Нет — недопустимо) в столбце блокировки L2 в некоторой строке матрицы совместимости блокировок (таблица 3) существует также конфликт в столбце блокировки L1 в той же строке. Диаграмма приоритетов блокировок приведена на рисунке 9.  Рисунок 9 - Диаграмма приоритета блокировок различных типов Несмотря на привлекательность метода гранулированных синхронизационных захватов, следует отметить, что он не решает проблему фантомов (если, конечно, не ограничиться использованием захватов отношений в режимах Sи X). Известно, что проблема фантомов не возникает, если объектом блокировки является целое отношение. Именно это свойство и послужило основой разработки метода предикатных синхронизационных захватов. В этом случае мы рассматриваем захват отношения — простой и частный случай предикатного захвата. Суть этого метода — оценить множество кортежей, которое связано с той или иной транзакций, и если эти два множества, относящиеся к одному отношению, не пересекаются, то две транзакции могут оперировать ими параллельно без взаимной блокировки, а результаты выполнения обеих транзакций будут корректными. Поскольку любая операция над реляционной базой данных задается некоторым условием (то есть в ней указывается не конкретный набор объектов базы данных, над которыми нужно выполнить операцию, а условие, которому должны удовлетворять объекты этого набора), идеальным выбором было бы требовать синхронизационный захват в режиме S или X именно этого условия. Но если посмотреть на общий вид условий, допускаемых, например, в языке SQL, то становится абсолютно непонятно, как определить совместимость двух предикатных захватов. Ясно, что без этого использовать предикатные захваты для синхронизации транзакций невозможно, а в общей форме проблема неразрешима. Эта проблема сравнительно легко решается для случая простых условий. Будем называть простым условием конъюнкцию простых предикатов, имеющих вид: Имя атрибута { операция сравнения } значение Здесь операция сравнения: =, >, < В типичных СУБД, поддерживающих двухуровневую организацию (языковой уровень и уровень управления внешней памяти), в интерфейсе подсистем управления памятью (которая обычно заведует и сериализацией транзакций) допускаются только простые условия. Подсистема языкового уровня производит компиляцию исходного оператора со сложным условием в последовательность обращений к ядру СУБД, в каждом из которых содержатся только простые условия. Следовательно, в случае типовой организации реляционной СУБД простые условия можно использовать как основу предикатных захватов. Для простых условий совместимость предикатных захватов легко определяется на основе следующей геометрической интерпретации. Пусть R — отношение с атрибутами a1, a2, ..., an, а m1, m2, ..., mn — множества допустимых значений a1, a2, ..., an соответственно (все эти множества — конечные). Тогда можно сопоставить R конечное n-мерное пространство возможных значений кортежей R. Любое простое условие "вырезает" m-мерный прямоугольник в этом пространстве (m <= n). Тогда S-X, X-S, X-Xпредикатные захваты от разных транзакций совместимы, если соответствующие прямоугольники не пересекаются. Это иллюстрируется следующим примером, показывающим, что в каких бы режимах не требовала транзакция 1 захвата условия (1<=a<=4) & (b=5), а транзакция 2 — условия (1<=a<=5) & (1<=b<=3), эти захваты всегда совместимы. Пример: (n = 2) Заметим, что предикатные захваты простых условий описываются таблицами, немногим отличающимися от таблиц традиционных синхронизаторов.  Рисунок 10 - Области действия предикатных захватов
1.7 Метод временных меток
Альтернативный метод сериализации транзакций, хорошо работающий в условиях редких конфликтов транзакций и не требующий построения графа ожидания транзакций, основан на использовании временных меток. Основная идея метода (у которого существует множество разновидностей) состоит в следующем: если транзакция T1 началась раньше транзакции T2, то система обеспечивает такой режим выполнения, как если бы T1 была целиком выполнена до начала T2. Для этого каждой транзакции T предписывается временная метка t, соответствующая времени начала T. При выполнении операции над объектом r транзакция T помечает его своей временной меткой и типом операции (чтение или изменение). Перед выполнением операции над объектом r транзакция T1 выполняет следующие действия: Проверяет, не закончилась ли транзакция T, пометившая этот объект. Если T закончилась, T1 помечает объект r и выполняет свою операцию. Если транзакция T не завершилась, то T1 проверяет конфликтность операций. Если операции неконфликтны, при объекте r остается или проставляется временная метка с меньшим значением, и транзакция T1 выполняет свою операцию. Если операции T1 и T конфликтуют, то если t(T) > t(T1) (то есть транзакция T является более "молодой", чем T1), производится откат T и T1 продолжает работу. Если же t(T) < t(T1) (T "старше" T1), то T1 получает новую временную метку и начинается заново. К недостаткам метода временных меток относятся потенциально более частые откаты транзакций, чем в случае использования синхронизационных захватов. Это связано с тем, что конфликтность транзакций определяется более грубо. Кроме того, в распределенных системах не очень просто вырабатывать глобальные временные метки с отношением полного порядка.
ГЛАВА 2.Транзакции в Microsoft SQL Server 2000
2.1 Поведение параллельных транзакций в Microsoft SQL Server
Существует три типа поведения параллельно выполняемых транзакций: Чтение нефиксированных данных (Dirty read). Чтение, при котором происходит считывание еще не фиксированных данных. Чтение нефиксированных данных возникает в том случае, когда одна транзакция модифицирует данные, а вторая транзакция читает эти модифицированные данные до того, как зафиксированы изменения, внесенные в первой транзакции. В случае отката первой транзакции вторая транзакция получит данные, которых нет в базе данных. Неповторяемое чтение (Nonrepeatable read). Несогласующиеся результаты, получаемые при повторном чтении. Неповторяемое чтение возникает в случае, когда чтение одной строки данных происходит более одного раза в течение одной транзакции, а между чтениями отдельная транзакция вносит изменения в эту строку. При повторном чтении в первой транзакции будут считываться другие данные, поэтому в пределах одной транзакции получаются неповторяемые результаты. Фантомное чтение (Phantom read). Чтение, возникающее в том случае, когда одна транзакция пытается прочитать строку, которая еще не существует в начале данной транзакции, но вставляется второй транзакцией, прежде чем закончится первая транзакция. Если первая транзакция снова выполнит поиск этой строки, то обнаружит ее неожиданное появление. Эта новая строка называется фантомной строкой. В таблице 4 приводится список типов поведения, которые допускаются на каждом уровне изолированности. Как можно видеть из таблицы, уровень read uncommitted является наименее ограничивающим уровнем изолированности, а serializable – наиболее ограничивающим. Как уже отмечалось, read committed является в SQL Server принятым по умолчанию уровнем изолированности. По мере роста уровня изолированности SQL Server налагает все более ограничивающую блокировку на все более длительные периоды времени. И, как отмечалось, уровень изолированности влияет на блокирующее поведение операторов SELECT, а это означает, что изолированность влияет на режим блокировки, применяемый к читаемым данным. Режимы блокировки описаны в разделе "Блокировка транзакций" далее. |
| | Допустимое поведение | Чтение нефиксированных данных | Неповторяемое чтение | Фантомное чтение | | Read uncommitted | Да | Да | Да | | Read committed | Нет | Да | Да | | Repeatable read | Нет | Нет | Да | | Serializable | Нет | Нет | Нет |
Таблица 4. Поведение при различных уровнях изолированности
Можно задать уровень изолированности, который будет использоваться для всего сеанса пользователя SQL Server, с помощью операторов Transact-SQL (T-SQL) или с помощью функций в вашем приложении. Можно также задать в запросе подсказку блокировки, чтобы переопределить уровень изолированности для данной транзакции. Подсказки блокировки приводятся в секции "Подсказки блокировки". Чтобы задать уровень изолированности с помощью T-SQL или в приложении DB-LIB, используя оператор SET TRANSACTION ISOLATION LEVEL и одного из четырех уровней изолированности. Используется следующий синтаксис: SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE GO После того как задали определенный уровень изолированности для сеанса, все последующие транзакции в этом сеансе SQL Server будут осуществлять блокировку, обеспечивающую этот уровень изолированности. Чтобы определить, какой уровень изолированности SQL Server применяется в данный момент по умолчанию, используйте команду DBCC USEROPTIONS. Нужно указать имя данной команды: DBCC USEROPTIONS Эта команда возвращает в результате только те параметры, которые задал пользователь или которые являются активными. Если не задан уровень изолированности (оставив принятый по умолчанию уровень SQL Server), то не увидите этот уровень, запустив оператор DBCC USEROPTIONS. Но если был задан уровень, отличный от принятого по умолчанию, то увидите этот уровень изолированности. Например, если выполнить следующие операторы, то уровень изолированности будет показан в результатах оператора DBCC USEROPTIONS: USE pubs GO SET TRANSACTION ISOLATION LEVEL SERIALIZABLE GO DBCC USEROPTIONS GO Результаты оператора DBCC USEROPTIONS будут выведены в следующей форме: Set Option Value --------------------------------------------- textsize 64512 language us_english dateformat mdy datefirst 7 quoted_identifier SET arithabort SET ansi_null_dflt_on SET ansi_defaults SET ansi_warnings SET ansi_padding SET ansi_nulls SET concat_null_yields_null SET isolation level serializable (13 row(s) affected) Для замещения принятого по умолчанию уровня изолированности можно использовать подсказки блокировки на уровне таблиц.
2.2 Режимы транзакций в SQL Server
Транзакция может начинаться в одном из трех режимов: автофиксация (autocommit), явный режим (explicit) или неявный режим (implicit). По умолчанию для SQL Server принят режим автофиксации. Рассмотрим, что означает каждый из этих режимов.
2.2.1 Режим автофиксации
В режиме автофиксации каждый оператор T-SQL фиксируется по его завершении, и в этом режиме не требуется никаких дополнительных операторов для управления транзакциями. Каждая транзакция состоит только из одного оператора T-SQL. Режим автофиксации полезен при выполнении операторов с помощью интерактивной командной строки, утилиты OSQL или анализатора очередей SQL Server Query Аnalyzer, поскольку не нужно задавать в явном виде запуск и окончание каждой транзакции. Каждый оператор будет рассматриваться системой SQL Server как отдельная транзакция и будет фиксироваться сразу после его завершения. Режим автофиксации будет использоваться в каждом соединении с SQL Server, пока не запустить транзакцию в явном режиме с помощью оператора BEGIN TRANSACTION или пока не укажете неявный режим. По окончании явно заданной транзакции или после отключения неявного режима SQL Server возвращается к режиму автофиксации.
2.2.2 Явный режим
Явный режим используется чаще всего для программных приложений, а также для хранимых процедур, триггеров и сценариев. При запуске группы операторов для выполнения какой-либо задачиможет потребоваться указание начала и конца данной транзакции, чтобы затем выполнить фиксацию всей группы операторов или отмену (откат) модификаций всей группы. Если явно указывается начало и конец транзакции, и такую транзакцию называют явной транзакцией. Явная транзакция задается с помощью 2.2.3 Использование явной транзакции
Рассмотрим ситуацию, в которой потребовалось бы использование явной транзакции для запуска и окончания задачи. Предположим, что имеется хранимая процедура с именем Place_Order (Поместить_Заказ), которая управляет в базе данных задачей размещения заказа покупателя на какой-либо товар. Эта процедура включает в себя следующие шаги: выбор информации о текущем счете покупателя, ввод идентификационного номера нового заказа и наименования товара, расчет стоимости заказа с учетом налогов, обновление остатка на счете покупателя с учетом общей стоимости и проверка наличия товара на складе. Для согласованности информации в базе данных нужно, чтобы были завершены все эти шаги или не был завершен ни один из этих шагов. Для этой цели сгруппируем все операторы, управляющие данной задачей, в одну явную транзакцию. Если эти операторы не будут объединены в одну группу, это может привести к несогласованному состоянию данных. Например, при обрыве соединения клиента с сервером после завершения шага, где вводится номер нового заказа, но до обновления остатка на счете покупателя, в базе данных появится новый заказ для данного покупателя, но без снятия денег со счета покупателя. В этом случае SQL Server фиксирует каждый оператор сразу после его окончания, что оставляет хранимую процедуру незаконченной на момент разъединения сети. Но если все указанные шаги определены в рамках одной явной транзакции, то в случае разъединения SQL Server автоматически выполнит откат всей транзакции, а клиент может затем снова подсоединиться к серверу и повторно выполнить данную процедуру. Использование явных транзакций, когда задача состоит из нескольких шагов, также дает преимущества, поскольку SQL Server (независимо от использования операторов ROLLBACK) автоматически выполнит откат транзакций в случае серьезных ошибок, таких как обрыв связи в сети, аварийный сбой (базы данных или клиентской системы) или взаимоблокировка. Для запуска транзакции используется оператор T-SQL BEGIN TRANSACTION. Чтобы указать конец транзакции, используется COMMIT TRANSACTION или ROLLBACK TRANSACTION. В операторе BEGIN TRANSACTION можно дополнительно указать имя транзакции и затем ссылаться на эту транзакцию по имени в операторе COMMIT TRANSACTION или ROLLBACK TRANSACTION. Ниже показан синтаксис этих трех операторов: BEGIN TRAN[SACTION] [имя_транзакции | @переменная_с_именем_транзакции] COMMIT [TRAN[SACTION] [имя_транзакции | @переменная_с_именем_транзакции]] ROLLBACK [TRAN[SACTION] [имя_транзакции | @переменная_с_именем_транзакции | имя_точки_сохранения | @переменная_с_именем_точки_сохранения]]
2.2.4 Фиксирование транзакций
Фиксированной называется транзакция, все модификации которой стали постоянной частью базы данных. До фиксирования транзакции запись о ее модификациях и запись ее фиксирования заносятся в журнал транзакций базы данных. Таким образом, модификации, которые становятся постоянной частью базы данных, могут находиться в одном из двух мест: либо они фактически записываются на диск и, тем самым, оказываются в базе данных, либо они находятся в кэше данных, что позволяет в случае сбоя выполнить повтор транзакции с помощью журнала транзакций, чтобы избежать потери данной транзакции. Все ресурсы, используемые транзакцией, такие как блокировки, освобождаются после фиксирования данной транзакции. Фиксирование транзакции считается успешным в случае успешного завершения каждого из ее операторов. Ниже приводится небольшая транзакция с именем update_state, которая изменяет в таблице publishers (издатели) значение колонки state на XX для всех издателей, у которых в этой колонке содержится значение NULL: USE pubs GO BEGIN TRAN update_state
UPDATE publishers SET state = 'XX' WHERE state IS NULL COMMIT TRAN update_state GO Запустив эту транзакцию, можно увидеть, что это повлияло на две строки. Чтобы вернуть таблицу к ее исходному состоянию (как если бы вместо фиксирования произошел откат), необходимо выполнить следующую транзакцию: USE pubs GO BEGIN TRAN undo_update_state
UPDATE publishers SET state = NULL WHERE state = 'XX' COMMIT TRAN undo_update_state GO Это повлияло на две строки. Имена транзакций update_state (модифицировать_состояние) и undo_update_state (отменить_модификацию_состояния), используемые в операторе COMMIT TRAN, игнорируются в SQL Server: имена транзакций используются просто для удобства программиста, чтобы можно было указать имя фиксируемой транзакции. SQL Server автоматически фиксирует последнюю нефиксированную транзакцию, запущенную перед фиксированием, независимо от указания имени транзакции.
2.3 Создание вложенных транзакций в SQL Server
В SQL Server разрешаются вложенные транзакции, т.е. транзакции внутри транзакции. В случае вложенных транзакций можно явно фиксировать каждую внутреннюю транзакцию, чтобы SQL Server получал информацию об окончании внутренней транзакции и мог освободить ресурсы, используемые этой транзакцией, когда будет фиксирована внешняя транзакция. Если ресурсы блокированы, другие пользователи не могут получать доступа к этим ресурсам. Хотя необходимо явным образом включать оператор фиксации COMMIT для каждой транзакции, SQL Server не выполняет фактического фиксирования внутренних транзакций, пока не произойдет успешное фиксирование внешней транзакции; одновременно с этим SQL Server освобождает все ресурсы, используемые внутренними и внешней транзакциями. При неуспешном фиксировании внешней транзакции фиксирование внутренних транзакций не выполняется и происходит откат внешней и всех внутренних транзакций. После фиксирования внешней транзакции выполняется фиксирование внутренних транзакций. SQL Server по сути игнорирует операторы COMMIT внутри внутренних вложенных транзакций, внутренние транзакции не фиксируются в ожидании окончательного фиксирования или отката внешней транзакции, чтобы определить статус завершения всех внутренних транзакций. Кроме того, в случае использования оператора отката ROLLBACK во внешней транзакции или в любой из внутренних транзакций происходит откат всех этих транзакций. В оператор ROLLBACK нельзя включать имя внутренней транзакции; в этом случае SQL Server возвратит сообщение об ошибке. Можно включать имя внешней транзакции, имя точки сохранения или не включать никакого имени. Рассмотрим пример вложенной транзакции, включающей в себя хранимую процедуру. Эта хранимая процедура содержит явную транзакцию и вызывается из другой явной транзакции. Поэтому транзакция в хранимой процедуре становится внутренней вложенной транзакцией. В следующей последовательности SQL показаны операторы, используемые для создания хранимой процедуры, и транзакция, которая вызывает эту хранимую процедуру. (Для упрощения в этом примере используется оператор PRINT, а не реальные операторы модифицирования данных.) USE MyDB GO CREATE PROCEDURE Place_Order --Создает хранимую процедуру AS BEGIN TRAN place_order_tran PRINT 'Здесь должны быть SQL-операторы, выполняющие задачи по заказам' COMMIT TRAN place_order_tran GO
BEGIN TRAN Order_tran --Начинает внешнюю транзакцию PRINT 'Поместите заказ' EXEC Place_Order --Вызывает хранимую процедуру, которая --начинает внутреннюю транзакцию COMMIT TRAN Order_tran --Фиксирует внутреннюю и внешнюю --транзакции GO
Выполнив эту программу, можно увидеть результаты обоих операторов PRINT. Транзакция place_order_tran должна содержать внутри хранимой процедуры оператор COMMIT, отмечающий конец этой транзакции, но на самом деле это фиксирование не произойдет, пока не будет выполнено фиксирование транзакции Order_tran. Фиксирование или откат place_order_tran будет зависеть только от фиксирования Order_tran. Хотя SQL Server не выполняет фактического фиксирования внутренних транзакций по оператору COMMIT, но все же для каждого оператора COMMIT происходит изменение системной переменной @@TRANCOUNT. Эта переменная следит за количеством активных транзакций на одно соединение с пользователем. При отсутствии активных транзакций значение @@TRANCOUNT равно 0. В начале каждой транзакции (с помощью BEGIN TRAN) значение @@TRANCOUNT увеличивается на 1. После фиксирования каждой транзакции значение @@TRANCOUNT уменьшается на 1. Когда значение @@TRANCOUNT становится равным 0, фиксируется внешняя транзакция. Если во внешней транзакции или в любой из внутренних транзакций выполняется оператор ROLLBACK, то значение @@TRANCOUNT устанавливается равным 0. Чтобы увидеть значение @@TRANCOUNT, необходимо использовать оператор SELECT @@TRANCOUNT.
2.3.1 Использование @@TRANCOUNT
Рассмотрим пример того, как SQL Server использует переменную @@TRANCOUNT. Предположим, что имеется вложенная транзакция, состоящая из двух транзакций: одной внутренней и одной внешней, как в предыдущем примере. После запуска обеих транзакций, но до того, как они фиксированы, значение @@TRANCOUNT равно 2. Внешняя транзакция не может быть фиксирована, поскольку @@TRANCOUNT имеет ненулевое значение. После оператора COMMIT внутренней транзакции SQL Server уменьшает @@TRANCOUNT до 1. После оператора COMMIT внешней транзакции значение @@TRANCOUNT уменьшится до 0, и будет выполнено фактическое фиксирование внешней и внутренней транзакций. Следующая программа основана на предыдущем примере, но включает в себя считывание значений @@TRANCOUNT: USE MyDB GO DROP PROCEDURE Place_Order GO CREATE PROCEDURE Place_Order --Создает хранимую процедуру. AS BEGIN TRAN place_order_tran --Приращение TRANCOUNT PRINT 'Здесь должны быть SQL-операторы, выполняющие задачи по заказам' SELECT @@TRANCOUNT as TRANCOUNT_2 COMMIT TRAN place_order_tran --Уменьшение TRANCOUNT. GO
SELECT @@TRANCOUNT as TRANCOUNT_initial BEGIN TRAN Order_tran --Приращение TRANCOUNT. PRINT 'Place an order' SELECT @@TRANCOUNT as TRANCOUNT_1 EXEC Place_Order --Вызывает хранимую процедуру, которая --начинает внутреннюю транзакцию. SELECT @@TRANCOUNT as TRANCOUNT_3 COMMIT TRAN Order_tran --Уменьшение TRANCOUNT. SELECT @@TRANCOUNT as TRANCOUNT_4 GO При выполнении этой программы можно увидить на экране значения @@TRANCOUNT, которые выводятся в следующем порядке: 0, 1, 2, 1, 0.
2.3.2 Неявный режим
В неявном режиме транзакция автоматически начинается при использовании определенных операторов T-SQL и продолжается, пока не появится оператор явного окончания COMMIT или ROLLBACK. Если оператор окончания не указан, то при отсоединении пользователя происходит откат данной транзакции. Следующие операторы T-SQL являются началом новой транзакции в неявном режиме: ALTER TABLE CREATE DELETE DROP FETCH GRANT INSERT OPEN REVOKE SELECT TRUNCATE TABLE UPDATE Если один из этих операторов используется, чтобы начать неявную транзакцию, эта транзакция продолжается, пока не будет явно указано ее окончание, даже если внутри транзакции снова встретятся эти операторы. После явного фиксирования или отката данной транзакции следующее появление этих операторов является началом новой транзакции. Этот процесс продолжает действовать, пока не будет отключен неявный режим. Чтобы задать неявный режим транзакций, необходимо использовать следующий оператор T-SQL: SET IMPLICIT_TRANSACTIONS {ON | OFF} Значение ON активизирует неявный режим, и OFF отключает его. После отключения неявного режима используется режим автофиксации. Неявные транзакции полезно использовать, когда запускаются сценарии с модификациями данных, которые требуется защитить внутри транзакции. Можно включить неявный режим в начале сценария, выполнить необходимые модификации и отключить этот режим в конце сценария. Во избежание конфликтов параллельных операций отключайте неявный режим после модификации данных и перед просмотром данных. Если вслед за операцией фиксирования следует оператор SELECT, то с него начинается новая транзакция в неявном режиме, и соответствующие ресурсы не будут освобождены, пока не будет фиксирована эта транзакция.
2.4 Откаты транзакций в SQL Server Откаты могут происходить в двух формах: автоматический откат, выполняемый SQL Server, или программируемый вручную откат. В определенных случаях SQL Server выполнит откат. Но для обеспечения логической согласованности в программах можно при необходимости явным образом обращаться к оператору ROLLBACK. Рассмотрим более подробно эти два метода. 2.4.1 Автоматические откаты
При сбое транзакции вследствие серьезной ошибки, такой как потеря сетевого соединения при выполнении данной транзакции или отказ клиентского приложения или компьютера, SQL Server выполняет автоматический откат транзакции. Во время отката происходит отмена всех модификаций, выполненных в данной транзакции, и освобождение всех ресурсов, использовавшихся этой транзакцией. Если при исполнении какого-либо оператора возникает ошибка, такая как нарушение ограничения или правила, то по умолчанию SQL Server автоматически выполняет откат только этого определенного оператора, в котором возникла ошибка. Чтобы изменить это поведение, можно использовать оператор SET XACT_ABORT. Если задать для XACT_ABORT значение ON, то в случае ошибки исполнения SQL Server автоматически выполнит откат транзакции. Этот метод полезно использовать, например, когда один оператор транзакции не выполняется из-за того, что он нарушает ограничение по внешнему ключу. По умолчанию для XACT_ABORT задано значение OFF. SQL Server использует также автоматический откат при восстановлении сервера. Например, если отключился источник питания во время выполнения транзакций и произошла перезагрузка системы, то при перезапуске SQL Server выполнит автоматическое восстановление. При автоматическом восстановлении происходит чтение информации из журнала транзакций для воспроизведения фиксированных транзакций, которые не были записаны на диск, и отката транзакций, которые находились в процессе выполнения (еще не были фиксированы) в момент отказа источника питания.
2.4.2 Программируемые откаты
С помощью оператора ROLLBACK можно указать точку в транзакции, где будет выполнен откат. Оператор ROLLBACK прекращает данную транзакцию и выполняет откат (отмену) всех выполненных изменений. Если запускается откат в середине какой-либо транзакции, то остальная часть этой транзакции игнорируется. Если, например, эта транзакция является хранимой процедурой и оператор ROLLBACK выполняется в этой процедуре, то происходит откат всей процедуры и переход к обработке оператора, следующего после вызова хранимой процедуры. Еслинужно выполнить откат, исходя из количества строк, возвращенных оператором SELECT, используйте системную переменную @@ROWCOUNT. Эта переменная содержит количество строк, которое возвращается в результате запроса или на которое влияет модификация или удаление. Если конкретное количество строк не имеет значения и просто нужно определить наличие строки или строк для определенного условия, то можно использовать совместно с оператором SELECT оператор IF EXISTS. Этот оператор не возвращает количества строк данных, а только значение TRUE или FALSE. Если результат равен TRUE, то выполняется следующий оператор; если результат равен FALSE, то следующий оператор не выполняется. В операторе IF EXISTS может также использоваться предложение ELSE. Рассмотрим пример использования предложения IF EXISTS...ELSE. В следующей транзакции происходит модификация значений ставки арендной платы (royalty) в таблице roysched для двух ставок арендной платы (royalty rates) (16 процентов и 15 процентов), но если ни одна из этих ставок не существует, то ни одна из команд UPDATE выполняться не будет. Для обеспечения такого результата в этой транзакции используется оператор ROLLBACK. BEGIN TRAN update_royalty --Начать транзакцию. USE pubs IF EXISTS (SELECT titles.title, roysched.royalty FROM titles, roysched WHERE titles.title_id = roysched.title_id AND roysched.royalty = 16) UPDATE roysched SET royalty = 17 WHERE royalty = 16 --Имеется 13 строк. ELSE ROLLBACK TRAN update_royalty --ROLLBACK не выполняется.
IF EXISTS (SELECT titles.title, roysched.royalty FROM titles, roysched WHERE titles.title_id = roysched.title_id AND roysched.royalty = 15) --Нет ни одной строки. BEGIN UPDATE roysched SET royalty = 20 WHERE royalty = 15 COMMIT TRAN update_royalty END ELSE --Выполняется ROLLBACK. ROLLBACK TRAN update_royalty GO В этой транзакции первый оператор IF EXISTS (SELECT...) определяет, что существует несколько строк, и поэтому оператор UPDATE выполняется (показывая, что модификация касается 13 строк). Второй оператор SELECT возвращает 0 строк, и поэтому второй оператор UPDATE не выполняется, но выполняется оператор ROLLBACK TRAN update_royalty. Поскольку ROLLBACK выполняет откат всех модификаций до самого начала данной транзакции, то происходит откат первой модификации. Если снова выполнить первый оператор SELECT, то по-прежнему будут 13 строк со значением royalty, равным 16, как и было в исходном состоянии базы данных, когда запускали данную транзакцию. И снова изменение royalty на значение 17 будет отменено (будет выполнен откат) из-за оператора ROLLBACK. Откат транзакции нельзя выполнить после ее фиксирования. Чтобы можно было выполнить явный откат отдельной транзакции, оператор ROLLBACK должен предшествовать оператору COMMIT. В случае вложенных транзакций после фиксирования внешней транзакции (и, тем самым, внутренних транзакций) уже нельзя выполнить откат ни одной из транзакций. Нельзя выполнить откат только внутренних транзакций; должен быть выполнен откат всей транзакции (всех внутренних транзакций и внешней транзакции). Поэтому, включив имя транзакции в оператор ROLLBACK, проследите за тем, чтобы было указано имя внешней транзакции (во избежание путаницы и сообщения об ошибке от SQL Server). Однако существует обходной путь, позволяющий избежать отката всей транзакции и сохранить часть модификаций: можно использовать точки сохранения.
2.4.3 Точки сохранения
Можно избежать отката всей транзакции; для этого нужно использовать точку сохранения, которая позволяет выполнять откат только до определенной точки в транзакции, а не до самого начала транзакции. Все модификации, выполненные до точки сохранения, остаются в силе и не подвергаются откату; но для всех операторов, выполняемых после точки сохранения (которую вы должны указать в транзакции) вплоть до оператора ROLLBACK, будет выполнен откат. Затем начнут выполняться операторы, следующие за оператором ROLLBACK. Если затем зададить откат транзакции без указания точки сохранения, то, как обычно, будет выполнен откат всех модификаций вплоть до начала данной транзакции, т.е. будет отменена вся транзакция. Отметим, что при откате транзакции до точки сохранения SQL Server не освобождает блокированные ресурсы. Они будут освобождены после фиксирования транзакции или после отката всей транзакции. Чтобы указать точку сохранения в транзакции, используйте следующий оператор: SAVE TRAN[SACTION] {имя_точки_сохранения | @переменная_с_именем_точки_сохранения} Необходимо поместить точку сохранения в том месте транзакции, до которого необходимо выполнять откат. Чтобы выполнить откат до точки сохранения, используйте ROLLBACK TRAN вместе с именем точки сохранения, как это показано ниже: ROLLBACK TRAN имя_точки_сохранения Можно использовать другие операторы T-SQL, чтобы продолжить транзакцию. Необходимо включить оператор COMMIT или другой оператор ROLLBACK после первого оператора ROLLBACK, чтобы завершить всю транзакцию.
2.5 Блокировка транзакций в SQL Server
В SQL Server используется объект, который называется блокировкой (lock); он препятствует тому, чтобы несколько пользователей одновременно вносили изменения в базу данных и чтобы один пользователь считывал данные, которые изменяет в этот момент другой пользователь. Блокировка помогает обеспечивать логическую целостность транзакций и данных. Управление блокировками осуществляется внутренним образом из программного обеспечения SQL Server и захват блокировки осуществляется на уровне пользовательского соединения. Если пользователь захватывает блокировку (становится ее владельцем) по какому-либо ресурсу, то эта блокировка указывает, что данный пользователь имеет право на использование данного ресурса. К ресурсам, которые может блокировать пользователь, относятся строка данных, страница данных экстент (8 страниц), таблица или вся база данных. Например, если пользователь владеет блокировкой по странице данных, то другой пользователь не может выполнять операции на этой странице, которые повлияют на операции пользователя, владеющего данной блокировкой. Поэтому любой пользователь не может модифицировать страницу данных, которая блокирована и считывается в данный момент другим пользователем. Кроме того, ни один пользователь не может владеть блокировкой, конфликтующей с блокировкой, которой уже владеет другой пользователь. Например, два пользователя не могут одновременно владеть блокировками на одновременную модификацию одной и той же страницы. Одна блокировка не может одновременно использоваться более чем одним пользователем. Система управления блокировками SQL Server автоматически захватывает и освобождает блокировки в соответствии с действиями пользователей. Для управления блокировками не требуется никаких действий со стороны DBA (администратора базы данных) или программиста. Однако можно использовать программные подсказки (hint), чтобы задать для SQL Server, какой тип блокировки нужно захватывать при выполнении определенного запроса или модификации базы данных.
2.5.1 Возможности управления блокировками
SQL Server поддерживает блокировку на уровне строк, т.е. позволяет захватывать блокировку по строке страницы данных или страницы индекса. Блокировка на уровне строк – самый высокий уровень детализации, который можно получить в SQL Server. Этот нижний уровень блокировки дает больше возможностей параллельной работы многим приложениям оперативной обработки транзакций (OLTP). Блокировка на уровне строк особенно полезна, когда выполняются вставки, обновления и удаления в таблицах и индексах. В дополнение к возможности блокировки на уровне строк SQL Server обеспечивает простоту администрирования для конфигурации блокировок.. По умолчанию при увеличении необходимого количества блокировок SQL Server динамически выделяет дополнительное количество вплоть до предела, определяемого памятью SQL Server. Если какое-то количество блокировок больше не используется, SQL Server освобождает их. SQL Server также оптимизирован для динамического выбора типа блокировки, который захватывается по какому-либо ресурсу – обычно это блокировка на уровне строк для вставок, обновлений и удалений и блокировка страниц для сканирования таблиц
2.5.2 Уровни блокировок
Блокировки могут захватываться по целому ряду ресурсов; тип ресурса определяет уровень детализации данной блокировки. В таблице 5 приводится список ресурсов, которые может блокировать SQL Server, начиная с самого подробного и до самого крупного уровня детализации.
| Ресурс | Тип блокировки | Описание | | Идентификатор строки | Уровень строки | Блокирует отдельную строку в таблице | | Ключ | Уровень строки | Блокирует отдельную строку в индексе | | Страница | Уровень страницы Блокирует отдельную страницу размером 8 Кб в таблице или индексе |
| | Экстент | Уровень экстента | Блокирует экстент – группу из 8 последовательных страниц данных или страниц индекса | | Таблица | Уровень таблицы | Блокирует всю таблицу | | База данных | Уровень базы данных | Блокирует всю базу данных |
Таблица 5. Блокируемые ресурсы
При снижении уровня детализации снижается степень параллельности. Например, блокировка всей таблицы с помощью определенного типа блокировки может заблокировать доступ к этой таблице другим пользователям. Но при этом снижается объем передачи дополнительной служебной информации (непроизводительные затраты), поскольку используется меньшее количество блокировок. По мере повышения уровня детализации, например, до уровня блокировки страниц и строк, уровень параллельности возрастает, поскольку увеличивается количество пользователей, одновременно получающих доступ к различным страницам и строкам в таблице. В этом случае увеличиваются также непроизводительные затраты, поскольку при отдельном доступе к большому числу строк или страниц требуется больше блокировок. SQL Server автоматически выбирает тип блокировки, подходящий для данной задачи, минимизируя при этом непроизводительные затраты на блокировку. SQL Server также автоматически определяет режим блокировки для каждой транзакции, касающейся блокируемого ресурса.
2.6 Блокирование и взаимоблокировки
Блокирование (blocking) и взаимоблокировки (deadlock) – это две дополнительные проблемы, которые могут возникать при одновременно выполняемых транзакциях. Они могут приводить к серьезным проблемам системы, а также могут замедлять и даже останавливать работу. Эти проблемы могут разрешаться в приложении, или SQL Server постарается сделать все возможное для их разрешения. Блокирование возникает в том случае, когда одна транзакция владеет блокировкой по какому-либо ресурсу, а второй транзакции требуется конфликтный тип блокировки по этому ресурсу. Вторая транзакция должна ждать, пока первая транзакция освободит свою блокировку; иными словами, она блокирована первой транзакцией. Проблема блокирования обычно возникает, когда какая-либо транзакция захватывает блокировку на длительный период времени, что приводит к цепочке блокированных транзакций, ожидающих окончания других транзакций, чтобы получить необходимые им блокировки; это состояние называют цепным блокированием. На рисунке 11 показан пример цепного блокирования. Взаимоблокировка отличается от блокированной транзакции в том, что взаимоблокировка возникает в случае двух блокированных транзакций, ожидающих друг друга. Например, предположим, что одна транзакция владеет монопольной блокировкой по Таблице 1, а вторая владеет монопольной блокировкой по Таблице 2. Прежде чем будет освобождена любая монопольная блокировка, первой транзакции требуется блокировка по Таблице 2 и второй транзакции – требуется блокировка по Таблице 1. Теперь каждая транзакция ждет, пока другая транзакция освободит свою монопольную блокировку, но ни одна из транзакций не сделает этого, пока не будет выполнено фиксирование или откат для завершения соответствующей транзакции. Ни одна из транзакций не может завершиться, поскольку для продолжения работы ей требуется блокировка, которой владеет другая транзакция, – ситуация взаимоблокировки!(Рисунок 12) При возникновении взаимоблокировки SQL Server прекращает одну из транзакций, и ее требуется запустить заново. 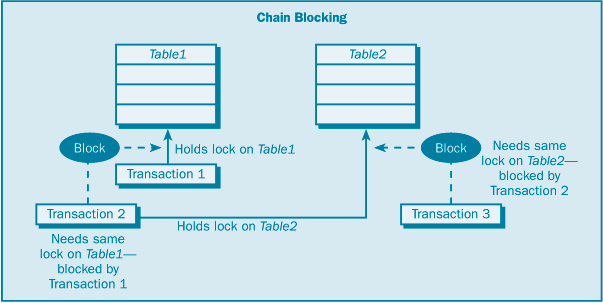 Рисунок 11 - Цепное блокирование
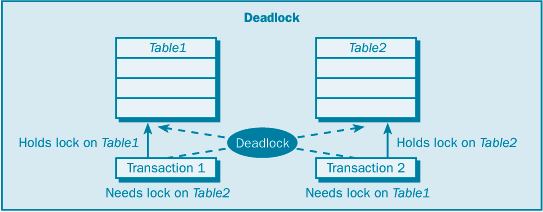 Рисунок 12 - Взаимоблокировка
2.6.1 Подсказки блокировки
Подсказки блокировки – это ключевые слова T-SQL, которые можно использовать с операторами SELECT, INSERT, UPDATE и DELETE, чтобы задать для SQL Server использование предпочтительного типа блокировки на уровне таблицы для определенного оператора. Можно использовать подсказки блокировки для переопределения принятого по умолчанию уровня изолированности. Рассмотрим ситуацию, где может оказаться полезным использование подсказок блокировки. Предположим, что используется для всех транзакций принятый по умолчанию уровень изолированности read uncommitted (чтение незафиксированных данных). При этом уровне изолированности по данному ресурсу захватывается разделяемая блокировка только до завершения чтения, и затем эта разделяемая блокировка освобождается. И если какая-либо транзакция читает одни и те же данные дважды, то результаты чтения могут не совпасть, поскольку другая транзакция могла захватить блокировку между первым и вторым чтениями и модифицировать эти данные. Чтобы избежать проблемы повторяемости чтения, можно задать уровень изолированности serializable (упорядочиваемость), но это вынудит SQL Server захватить все разделяемые блокировки, необходимые для операторов SELECT во всех транзакциях, пока не будет завершена каждая транзакция. Иными словами, для целостности транзакций разделяемые блокировки будут захвачены по таблице, указанной в операторе SELECT любой транзакции. Если не хотите поддерживать упорядочиваемость для всех ваших транзакций, то можете добавить какую-либо подсказку блокировки для определенного запроса. Подсказка блокировки HOLDLOCK в операторе SELECT указывает SQL Server захват всех разделяемых блокировок по таблице, заданной в операторе транзакции SELECT, вплоть до конца этой транзакции – независимо от уровня изолированности. Тем самым при повторном чтении будет наблюдаться согласованность данных (они не будут изменены другой транзакцией). Использование подсказок блокировки не влияет на уровень изолированности для других транзакций. В следующем списке дается описание существующих подсказок блокировки на уровне таблиц. HOLDLOCK. Захватывает разделяемую блокировку до завершения транзакции, а не освобождает ее сразу после того, как уже не требуется соответствующая таблица, страница или строка данных. Эквивалентно использованию подсказки блокировки SERIALIZABLE. NOLOCK. Применяется только к оператору SELECT. Не получает разделяемых блокировок и не поддерживает монопольных блокировок; читает данные, которые монопольно захвачены другой транзакцией. Эта подсказка позволяет читать нефиксированные данные (dirty read). PAGLOCK. Используется для блокировки на уровне страницы там, где обычно используется блокировка на уровне таблицы. READCOMMITTED. Выполняется сканирование с тем же поведением по блокировкам, как у транзакций, использующих уровень изолированности read committed (принятый по умолчанию уровень изолированности для SQL Server). READPAST. Применяется только к оператору SELECT и только к строкам, блокированным с помощью блокировки на уровне строк. Пропускаются строки, блокированные другими транзакциями, которые обычно включаются в набор результатов; возвращает результаты без этих блокированных строк. Может использоваться только с транзакциями, выполняемыми на уровне изолированности read committed. READUNCOMMITTED. Эквивалентно NOLOCK. REPEATABLEREAD.Выполняется сканирование с тем же поведением по блокировкам, как у транзакций, использующих уровень изолированности repeatable read. ROWLOCK.Используются блокировки на уровне строк вместо блокировки на уровне страниц или на уровне таблиц. SERIALIZABLE.Выполняется сканирование с тем же поведением по блокировкам, как у транзакций, использующих уровень изолированности serializable. Эквивалентно HOLDLOCK. TABLOCK.Используется блокировка на уровне таблиц вместо блокировки на уровне страниц или на уровне строк. SQL Server захватывает эту блокировку до завершения оператора. TABLOCKX. Используется монопольная блокировка по таблице. Внимание! Эта подсказка препятствует доступу других транзакций к этой таблице. UPDLOCK. Используются блокировки изменения вместо монопольных блокировок при чтении таблицы. Можно объединять совместимые подсказки блокировки, такие как TABLOCK и REPEATABLEREAD, но не льзя объединять конфликтующие подсказки, такие как REPEATABLEREAD и SERIALIZABLE. Чтобы задать подсказку блокировки на уровне таблиц, необходимо заключить эту подсказку в круглые скобки после имени таблицы в операторе T-SQL. Следующая последовательность является примером использования подсказок TABLOCKX в операторе SELECT: USE pubs SELECT COUNT(ord_num) FROM sales (TABLOCKX) WHERE ord_date > "Sep 13 1994" GO Подсказка TABLOCK сообщает SQL Server, что нужно захватить монопольную блокировку на уровне таблиц по таблице продаж (sales), пока не будет выполнен данный оператор. Эта подсказка обеспечивает, что никакая другая транзакция не сможет модифицировать данные в таблице sales, пока данный запрос подсчитывает заказы из этой таблицы.
Заключение В ходе выполнения работы было рассмотрено 3 вопроса: принцип создания и работы транзакции, свойства транзакций, технология применения транзакций в SQL Server 2000. Из проведенной работы можно сделать вывод, что во многих случаях, необходимо проведение группы операций по изменению данных таким образом, чтобы эта группа обладала свойством атомарности (либо вся целиком выполняется, либо вся целиком не выполняется). SQL Server предлагает множество средств управления поведением транзакций. Пользователи в основном должны указывать только начало и конец транзакции, используя команды SQL или API (прикладного интерфейса программирования). Таким образом, для реализации транзакций SQL Server является наиболее оптимальной программой.
Список используемых источников У. Дайер. Мониторы транзакций третьего поколения, 2006 Дж. Грей и A. Реутер. Транзакции: Лекции и практика. - Сан Франциско: Морган Кауфман, 2006 г. Хомоненко А.Д., Цыганков В.М., Мальцев М.Г. Базы данных. – СПб.: Корона принт, 2008 г. Д. Крёнке Теория и практика построения баз данных 9-е изд. - СПб: Питер, 2007 г. Бройдо, О. Ильина. Вычислительные системы, сети и телекоммуникации. – Питер, 2006 г. Кайт Том. Oracle для профессионалов – Питер, 2006 г. Т.И. Клигман. Реляционная модель данных: учебное пособие. - ПРИПИТ, ПГПУ, 2009 г. Федоров А., Елманова Н. Введение в базы данных. - Компьютер Пресс, №3-12 2008 г., №1-2 2009 г. Горев А., Ахаян Р., Макашарипов С. Эффективная работа с СУБД. - СПб.: Питер, 2006г. Кагаловский М.Р. Энциклопедия технологий баз данных. – М.: Финансы и статистика, 2007 г. С.Кузнецов SQL: язык реляционных баз данных. – М. Майор, 2006 г. Дейт К. Дж. Введение в системы баз данных – 6-е изд. – Вильямс, 2008 г. Кодд Дж., «Базы данных», Москва. Мир. 2006 г. В.В. Фаронов Основы программирования в SQL. - М.: Издатель Молгачева С.В., 2007 г. Распределенные СУБД. Informix. Ч.1. Основы работы с базами данных. - Методические указания для выполнения лабораторных работ / В.М. Стасышин - Новосибирск: НГТУ, 2009. Ролланд Ф. Основные концепции баз данных. – Вильямс, 2008 Мамаев Е. Microsoft SQL Server 2000 – СПб.: БХВ-Петербург, 2006 Приложение 1 С хема журнала транзакций хема журнала транзакций |