Государственный комитет Российской Федерации по высшему образованию
Казанский Государственный Технический Университет им. А.Н. Туполева
Аксанов Нияз Мансурович
ТЕХНОЛОГИЯ ХРАНИЛИЩ ДАННЫХ
552811 МАГИСТР ПО НАПРАВЛЕНИЮ БАЗЫ ДАННЫХ
Ризаев И.С. доцент, к.т.н.
КАЗАНЬ 2000
О Г Л А В Л Е Н И Е.
Оглавление 2
Введение 4
1. глава Обзор технологии Хранилищ Данных,
подходов и имеющихся решений. 10
1.1 Информационные системы. 10
1.2 Концепция Хранилищ Данных. 13
1.2.1 Основные идеи концепции Хранилищ Данных 13
1.2.2 Свойства Хранилищ Данных.16
1.2.3 Взаимное соотношение концепции ХД и
концепций анализа данных 19
1.3 Технологии и средства реализации23
1.3.1 Вопросы реализации Хранилищ Данных23
1.3.2 Основные компоненты Хранилищ Данных.31
1.4 Подходы и имеющиеся решения 33
1.4.1 Data Warehouse Framework33
1.4.2 A Data Warehouse Plus.35
1.4.3 Warehouse Technology Initiative36
1.4.4 WarehouseWORKS. 39
2. глава Исследование методов организации
структуры Хранилищ Данных. 41
2.1 СУБД для аналитических систем41
2.1.1 РСУБД 41
2.1.2 МСУБД 48
2.2 Витрина Данных.51
2.3. Выбор структуры Хранилища Данных 53
3. глава Проектирование Хранилищ Данных. 59
3.1 Технология проектирования Хранилищ Данных 59
3.1.1 Планирование и проектирование 59
3.1.2 Разработка 60
3.1.3 Установка системы и эксплуатация 60
3.1.4 Анализ протекающих процессов в системе 60
3.2 Тестовый проект по созданию витрины данных. 61
Заключение. 70
Библиографический список. 71
Приложения. 74
ВВЕДЕНИЕ
Актуальность темы.
Сегодня, практически в любой организации сложилась хорошо всем знакомая ситуация - информация вроде бы где-то и есть, её даже слишком много, но она неструктурированна, несогласованна, разрознена, не всегда достоверна, её практически невозможно найти и получить. Почему она возникла? Дело в том, что, во-первых, основное назначение таких систем - оперативная обработка данных и отражение только текущего состояния и построить аналитические системы на их основе чрезвычайно сложно. Во- вторых обычно в любой организации функционирует несколько различных, несвязанных или слабо связанных систем, а выгруженные из них данные, как правило, имеют различную структуру, формат, стандарты представления.
Поэтому является весьма актуальным рассмотрение проблем интеграции, согласованности и достоверности информации. Именно на решение этих задача и на преодоление ситуации «отсутствия информации при ее наличии и даже избытке» и нацелена концепция Хранилищ Данных (Data Warehouse).
Цель работы.
Повышение эффективности методов хранения информации предназначенной для аналитической обработки.
Объект исследования.
Технология Хранилищ Данных.
История развития.
Автором концепция Хранилищ Данных является W.H. Inmon, который изложил в 1992 году предложения по организации данных, которые затем постепенно переросли в технологию Хранилищ Данных (Data Warehouse). Эта идея была дополнена в 1993 году концепцией оперативной аналитической обработки данных (OLAP) Э.Кодда, и в результате их развития за прошедшее десятилетие было разработано около десятка различных архитектур корпоративных информационных систем на основе хранилищ данных, предназначенных для поддержки принятия решений и аналитических исследований.
Недостатки объекта исследования
Нет общих подходов к организации ХД. Высокая стоимость внедрения технология. Высокая сложность внедрения технологии. Все это препятствует широкому распространению этой технологии.
Практическая ценность.
Результаты работы позволили:
- получить возможность проводить нерегламентированный динамический анализ
- сократить время получения и обработки статистической отчетности
Реализация результатов работы.
Результаты данной работы использованы при разработке проекта комплекса сетевого программного обеспечения подготовки экономической и аналитической информации в САО «Росгосстрах-Татарстан» .
Публикации.
По теме диссертации опубликованы тезисы докладов на студенческих конференциях.
1. Проблемы организации распределенных систем.// Королевские чтения.
2. Некоторые проблемы распределенных систем.
// VIII Всероссийские Туполевские чтения студентов. 1998.
Объем работы.
Работа состоит из введения, трех глав и заключения, изложенных на 85 страницах, содержит 6 рисунков, 13 таблиц, включает 37 наименований отечественной и зарубежной литературы, 1 приложение.
Аннотация диссертационной работы по главам.
В первой главе
дается обзор технологии Хранилищ Данных, подходов и имеющихся решений.
Рассматриваются и сравниваются два направления развития информационных систем:
- системы, ориентированные на операционную обработку данных - системы обработки данных (СОД);
- системы, ориентированные на анализ данных - системы поддержки принятия решений (СППР)
Указывается на текущее состояние СОД – накоплены огромные массивы информации, преимущественно в архивном виде, но на их основе очень затруднено или невозможно выполнение задач динамического анализа развития, прогнозирования и др.
Как решение данной проблемы предлагается рассмотреть концепцию Хранилищ Данных, как предпредметно-ориентированного, интегрированного, неизменчивого, поддерживающего хронологию набора данных, организованного для целей поддержки управления. В основе этой концепции лежат: 1) интеграция разъединенных детализированных данных, 2) разделение наборов данных и приложений, используемых для оперативной обработки и применяемых для решения задач анализа.
Цель концепции ХД – прояснить отличия в характеристиках данных в операционных и аналитических системах, определить требования к данным, помещаемым в целевую БД Хранилища Данных, определить общие принципы и этапы ее построения.
Предметом концепции ХД служат сами данные. Данные рассматриваются как самостоятельный объект предметной области, порожденные в результате функционирования ранее созданных информационных систем.
Рассматриваются следующие свойства Хранилищ Данных: предметная ориентация, интегрированность данных, инвариантность во времени, неразрушаемость - cтабильность информации, минимизация избыточности информации.
Для четкости понимания концепции Хранилищ Данных, анализируется ее взаимосвязь с концепций анализа данных.
Далее рассматриваются вопросы технологии и средств реализации ХД. Указывается на необходимость разрешения таких вопросов, как: неоднородность программной среды; распределенность; защита данных от несанкционированного доступа; построение и ведение многоуровневых справочников метаданных; эффективное хранение и обработка очень больших объемов данных. Рассматриваются также основные компоненты ХД: ПО промежуточного слоя, транзакционные БД и внешние источники информации, ПО уровня доступа к данным, ПО загрузки и предварительной обработки, информационное хранилище, метаданные, ПО уровня информационного доступа, ПО уровня управления (администрирования).
Вконцеприводятсяподходыиимеющиесярешения: Data Warehouse Framework (Microsoft), A Data Warehouse Plus (IBM), Warehouse Technology Initiative (Oracle), Warehouse WORKS (Sybase).
Во второй главе описывается исследование методов организации структуры данных для аналитических систем.
Сравниваются три варианта реализации центральной БД в Хранилище данных. На основе РСУБД, МСУБД и многоуровневый смешанный вариант.
Подчеркивается, что исходно ориентированные на реализацию систем операционной обработки данных, РСУБД оказались менее эффективными в задачах аналитической обработки. Среди причин указываются: жесткие ограничения накладываемые существующей реализацией языка SQL, регламентированность запросов и отчетов,
высокая степень нормализации. Указывается, что со временем появляются новации, которые смягчают эти ограничения. Например, схема организации данных звезда. Далее рассматриваются плюсы и минусы вертикальной и горизонтальной фрагментации БД в целях оптимизации.
Более просто и эффективно аналитические системы реализуются средствами специализированных баз данных, основанных на многомерном представлении данных. В этих системах данные организованы не в виде плоских таблиц (как в реляционных системах), а в виде упорядоченных многомерных массивов - гиперкубов (или поликубов).
Очевидно, что такое решение требует большей суммарной памяти для хранения данных, больших затрат времени при их загрузке и является менее гибким при необходимости модификации структур данных. Но, как уже было сказано выше, в аналитических задачах все это окупается за счет более быстрого поиска и выборки данных, отсутствия необходимости в многократном соединении различных таблиц и многократного вычисления агрегированных значений. И, как правило, среднее время ответа на нерегламентированный аналитический запрос при использовании многомерной СУБД обычно на один-два порядка меньше, чем в случае реляционной СУБД с нормализованной схемой данных. Но МСУБД не приспособлены работать с очень большим объемом данных.
Показывается, что МСУБД однозначно хороши только при выполнении двух требований:
Уровень агрегации данных в БД достаточно высок, и, соответственно, объем БД не очень велик (не более нескольких гигабайт).
В качестве граней многомерного куба выбраны достаточно стабильные во времени реквизиты (с точки зрения неизменности их взаимосвязей), и, соответственно, число несуществующих значений относительно невелико.
Далее рассматривается многоуровневое решение:
первый уровень - общекорпоративная БД на основе РСУБД с нормализованной или слабо денормализованной схемой (детализированные данные);
второй уровень - БД уровня подразделения (или конечного пользователя), реализуемые на основе МСУБД (агрегированные данные);
третий уровень - рабочие места конечных пользователей, на которых непосредственно установлен аналитический инструментарий;
Именно оно постепенно становится стандартом де-факто, позволяя наиболее полно реализовать и использовать достоинства каждого из подходов:
- компактного хранения детализированных данных и поддержки очень больших БД, обеспечиваемых РСУБД;
- простота настройки и хорошие времена отклика при работе с агрегированными данными, обеспечиваемыми МСУБД.
Далее рассматривается выбор модели и структуры Хранилища Данных. Дается понятие подхода к поиску и выборке данных, называемого Оперативной Аналитической Обработкой (On-line Analytical Processing, OLAP). В зависимости от того в каком виде данные хранятся на физическом уровне описываются системы ROLAP, HOLAP, MOLAP.
В третьей главе рассматриваются вопросы проектирования ХД. Здесь предложена технология проектирования Хранилищ Данных. Описана технологическая цепочка создания ХД. Разработана модель ХД для страховой компании с распределенной внутренней структурой. На основе данных
САО «Росгосстрах-Татарстан» построена витрина данных для получения информации о поступлении взносов. С помощью клиентского приложения продемонстрированы возможности использования данных при такой их организации. Результаты тестов приведены в приложении.
1 глава. Обзор технологии Хранилищ Данных, подходов и имеющихся решений.
1.1
Информационные системы.
В области информационных технологий всегда существовали два взаимодополняющих друг друга направления развития (рис.1):
- системы, ориентированные на операционную обработку данных - системы обработки данных (СОД);
- 
системы, ориентированные на анализ данных - системы поддержки принятия решений (СППР).
Рисунок 1.
Направления развития информационных систем
Еще до недавнего прошлого, когда говорилось о стремительном вхождении в нашу жизнь информационных технологий и росте числа реализаций информационных систем, прежде всего имелись в виду системы, ориентированные исключительно на операционную обработку данных. И такое опережающее развитие одного из направлений вполне объяснимо.
На первых этапах автоматизации требовалось и требуется навести порядок именно в процессах повседневной рутинной обработки (переработки) данных, на что и ориентированы традиционные СОД. Однако за последние два-три года ситуация существенно изменилась. И это непосредственно связано с тем, что практически в любой организации сложилась хорошо всем знакомая парадоксальная ситуация: информация вроде бы где-то и есть, ее даже слишком много, но она не структурирована, не согласована, разрознена, не всегда достоверна, ее практически невозможно найти и получить. На первых порах аналитические системы строились непосредственно на OLTP системах, но на сегодняшний день такое построение уже не удовлетворяет требованиям аналитиков.
Рассмотрим причины кризиса оперативного анализа. Ниже представлены лишь основные из них.
Высокая степень детализации данных в OLTP системах.
Информация рассредоточена между несколькими системами. Указанный факт имеет несколько аспектов:
- Разные источники данных
- Разные форматы данных
- Разные механизмы доступа к данным
- Потенциальная нецелостность группы систем. Данные в различные системы могут поступать с разной степенью регулярности. При такой ситуации, хотя каждая из систем поддерживается в целостном состоянии, целостность группы систем может быть нарушена, что может исказить общую картину.
- Несколько независимых средств генерации отчетов.
Низкая скорость генерации отчетов. Поскольку OLTP системы ориентированы в первую очередь на эффективную обработку транзакций, генерирование больших и сложных отчетов обычно занимает значительное время.
Существует несколько путей преодоления кризиса. Один из них –создание шлюзов между отдельными системами. Это, однако, приводит лишь к объединению нескольких OLTP систем в одну и никак не решает проблему высокой детализации данных.
Данные, порожденные в результате функционирования корпоративных СОД, служат основой для построения СППР, но как уже указано выше строить такую систему непосредственно поверх СОД не эффективно, а при большом количестве малосвязанных СОД – это становится практически невозможно.
Поскольку СППР предъявляют особые требования к организации данных предназначенных для аналитической обработки: интеграция, непротиворечивость, достоверность, охват продолжительного периода времени.
Для удовлетворения этим требованиям в начале 90-х годов и возникла концепция Хранилищ Данных.
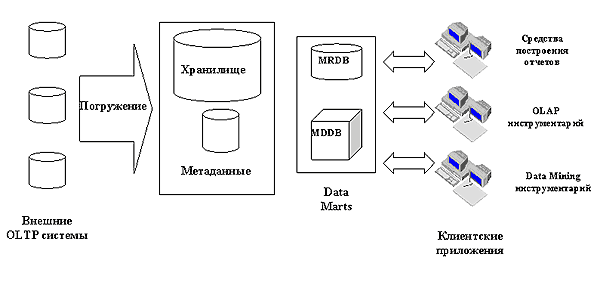
Рисунок 2
. Архитектура СППР на основе Хранилища Данных.
1.2 Концепция Хранилищ Данных.
Хранилище Данных (Data Warehouse) – предпредметно-ориентированный, интегрированный, неизменчивый, поддерживающий хронологию набор данных, организованный для целей поддержки управления.
1.2.1 Основные идеи концепции ХД
В основе концепции Хранилищ Данных лежат две основополагающие идеи:
Интеграция разъединенных детализированных данных (детализированных в том смысле, что они описывают некоторые конкретные факты, свойства, события и т.д.) в едином хранилище. В процессе интеграции должно выполняться согласование рассогласованных детализированных данных и, возможно, их агрегация. Данные могут поступать из исторических архивов корпорации, оперативных баз данных, внешних источников.
Разделение наборов данных и приложений, используемых для оперативной обработки и применяемых для решения задач анализа.
Цель концепции ХД – прояснить отличия в характеристиках данных в операционных и аналитических системах (таблица 1), определить требования к данным (таблица 2), помещаемым в целевую БД Хранилища Данных, определить общие принципы и этапы ее построения.
Наиболее распространенной на сегодня ошибкой является попытка найти в концепции Хранилищ Данных некий законченный рецепт реализации информационной аналитической системы. Тем более, это не некий готовый программный продукт или некое готовое универсальное решение.
| Характеристика
|
Операционные |
Аналитические
|
| Частота обновления |
Высокая частота, маленькими порциями |
Малая частота, большими порциями |
| Источники данных |
В основном, внутренние |
В основном, внешние |
| Объемы хранимых данных |
Сотни мегабайт, гигабайты |
Гигабайты и терабайты |
| Возраст данных |
Текущие (за период от нескольких месяцев до одного года) |
Текущие и исторические (за период в несколько лет, десятки лет) |
| Назначение |
Фиксация, оперативный поиск и преобразование данных |
Хранение детализированных и агрегированных исторических данных, аналитическая обработка, прогнозирование и моделирование |
Таблица 1.
Сравнение характеристик данных в информационных системах,
ориентированных на операционную и аналитическую обработку данных.
| Предметная ориентированность |
Все данные о некотором предмете (бизнес-объекте) собираются (обычно из множества различных источников), очищаются, согласовываются, дополняются, агрегируются и представляются в единой, удобной для их использования в бизнес-анализе форме. |
| Интегрированность |
Все данные о разных бизнес-объектах взаимно согласованы и хранятся в едином общекорпоративном Хранилище. |
| Неизменчивость |
Исходные (исторические) данные, после того как они были согласованы, верифицированы и внесены в общекорпоративное Хранилище, остаются неизменными и используются исключительно в режиме чтения. |
| Поддержка хронологии |
Данные хронологически структурированы и отражают историю, за достаточный для выполнения задач бизнес-анализа и прогнозирования период времени. |
Таблица 2.
Основные требования к данным в Хранилище Данных.
Предметом концепции ХД служат сами данные. Данные рассматриваются как самостоятельный объект предметной области, порожденные в результате функционирования ранее созданных информационных систем.
Для правильного понимания данной концепции необходимо уяснение следующих принципиальных моментов:
Концепция Хранилищ Данных - это не концепция анализа данных, скорее, это концепция подготовки данных для анализа.
Концепция Хранилищ Данных не предопределяет архитектуру целевой аналитической системы. Она говорит о том, какие процессы должны выполняться в системе, но не о том, где конкретно и как эти процессы должны выполняться.
Концепция Хранилищ Данных предполагает не просто единый логический взгляд на данные организации (как иногда это трактуется), а реализацию единого интегрированного источника данных.
Последний пункт достаточно принципиален, поэтому рассмотрим его более детально. Сегодня достаточно популярны решения, предполагающие интеграцию различных СОД на основе единого справочника метаданных (поддерживающего единый логический взгляд на данные организации), но не единого интегрированного источника данных. При этом по каждому новому запросу предполагается динамическая выгрузка данных из различных операционных источников (СОД), их динамическое согласование, агрегация и транспортировка к пользователю.
Очевидно, что для определенных классов приложений это решение вполне корректно. Но следует заранее понимать все накладываемые им ограничения.
Кроме единого справочника метаданных, средств выгрузки, агрегации и согласования данных, концепция Хранилищ Данных подразумевает: интегрированность, неизменчивость, поддержку хронологии и согласованность данных. И если два первых свойства (интегрированность и неизменчивость) влияют на режимы анализа данных (как будет показано ниже, без интегрированной базы данных, в которой используются специализированные методы хранения и доступа, по крайней мере, сегодня трудно говорить о реализации интерактивного динамического анализа), то последние два (поддержка хронологии и согласованность) существенно сужают список решаемых аналитических задач.
Без поддержки хронологии (наличия исторических данных) нельзя говорить о решении задач прогнозирования и анализа тенденций. Но наиболее критичными и болезненными оказываются вопросы, связанные с согласованием данных.
Основным требованием аналитика является даже не столько оперативность, сколько достоверность ответа. Но достоверность, в конечном счете, и определяется согласованностью. Пока не проведена работа по взаимному согласованию значений данных из различных источников, сложно говорить об их достоверности.
1.2.2 Свойства Хранилищ Данных.
Подробнее опишем – какими свойствами должно обладать содержимое ХД:
1. Предметная ориентация
2. Интегрированность данных
3. Инвариантность во времени
4. Неразрушаемость - cтабильность информации
5. Минимизация избыточности информации
1 Предметная ориентация
В отличие от БД в традиционных OLTP-системах, где данные подобраны в соответствии с конкретными приложениями, информация в DW ориентирована на задачи поддержки принятия решений.. Для системы поддержки принятия решений требуются "исторические" данные - факты продаж за определенные интервалы времени. Хорошо спроектированные структуры ХД отражают развитие всех направлений бизнеса компании во времени.
Поскольку в технологии ХД объекты данных выходят на первый план, то особые требования предъявляются к структурам БД, используемым для создания информационных хранилищ. Принципиально отличаются и структуры баз данных для OLTP сиитем и систем ХД. Во втором случае в них помещается только та информация, которая может быть полезной для работы систем поддержки принятия решений (DSS).
2 Интегрированность данных
Данные в информационное хранилище поступают из различных источников, где они могут иметь разные имена, атрибуты, единицы измерения и способы кодировки. После загрузки в ХД данные очищаются от индивидуальных признаков, т. е. как бы приводятся к общему знаменателю. С этого момента они представляются пользователю в виде единого информационного пространства.
Если в четырех разных приложениях пол клиента кодировался четырьмя различными способами, то в информационном хранилище будет использована единая для всех данных схема кодировки (например, f,m).
3 Инвариантность во времени
В OLTP-системах истинность данных гарантирована только в момент чтения, поскольку уже в следующее мгновение они могут измениться в результате очередной транзакции. Важным отличием ХД от OLTP-систем является то, что данные в них сохраняют свою истинность в любой момент процесса чтения.
В OLTP-системах информация часто модифицируется как результат выполнения каких-либо транзакций. Временная инвариантность данных в ХД достигается за счет введения полей с атрибутом "время" (день, неделя, месяц) в ключи таблиц. В результате записи в таблицах ХД никогда не изменяются, представляя собой снимки данных, сделанные в определенные отрезки времени. В ХД содержатся как бы моментальные снимки данных. Каждый элемент в своем ключе явно или косвенно хранит временной параметр, например день, месяц или год.
4 Неразрушаемость - cтабильность информации
В OLTP-системах записи могут регулярно добавляться, удаляться и редактироваться. В ХД, как следует из требования временной инвариантности, однажды загруженные данные теоретически никогда не меняются. По отношению к ним возможны только две операции: начальная загрузка и чтение (доступ). Это и определяет специфику проектирования структуры базы данных для ХД. Если при создании OLTP-систем разработчики должны учитывать такие моменты, как откаты транзакций после сбоя сервера, борьба с взаимными блокировками процессов (deadlocks), сохранение целостности данных, то для DW данные проблемы не столь актуальны - перед разработчиками стоят другие задачи, связанные, например, с обеспечением высокой скорости доступа к данным.
5 Минимизация избыточности информации
Поскольку информация в DW загружается из OLTP-систем, возникает вопрос, не ведет ли это к чрезмерной избыточности данных? Не обязательно. И это объясняется следующими причинами:
- при загрузке информации из OLTP – систем в ХД данные фильтруются. Многие из них вообще не попадают в ХД, поскольку лишены смысла с точки зрения использования в системах поддержки принятия решений;
- информация в OLTP-системах носит, как правило, оперативный характер, и данные, потеряв актуальность, удаляются. В ХД, напротив, хранится историческая информация, и с этой точки зрения перекрытие содержимого ХД данными OLTP-систем оказывается весьма незначительным;
- в ХД хранится некая итоговая информация, которая в базах данных OLTP-систем вообще отсутствует;
- во время загрузки в ХД записи сортируются, очищаются от ненужной информации и приводят к единому формату. После такой обработки это уже совсем другие данные.
1.2.3 Взаимное соотношение концепции Хранилищ Данных и концепций анализа данных
Как уже было сказано выше, концепция Хранилищ Данных определяет лишь самые общие принципы построения аналитической системы и в первую очередь сконцентрирована на свойствах и требованиях к данным, но не способах их организации и представления в целевой БД и режимах их использования.
То есть она фактически не затрагивает и оставляет свободу выбора в вопросах, относящихся:
- к конкретным способам представления данных в целевой БД (например многомерное, реляционное или смешанное);
- режимам анализа данных (статический или динамический).
В определенном смысле, концепция Хранилищ Данных, это концепция построения аналитической системы, но не концепция ее использования. Но данные собираются не для того, чтобы храниться, они должны работать. Ответ на вопрос, как наилучшим образом и наиболее полно использовать уже собранные и подготовленные для анализа данные, и дают различные концепции анализа данных:
- традиционный статический анализ данных;
- динамический интерактивный многомерный анализ данных.
Всего три-четыре года назад результатом работы любой аналитической системы являлись регламентированные многостраничные отчеты и диаграммы. Но, как правило, после просмотра такого отчета у аналитика появлялся не готовый ответ, а новая серия вопросов. Однако если бы ему захотелось получить ответ на новый, непредусмотренный при проектировании системы вопрос, он мог ждать его часы, а иногда и дни.
Каждый новый запрос в системах, реализуемых на основе традиционных технологий статического анализа данных (таблица 3), должен быть сначала формально описан, передан программисту, запрограммирован и, наконец, выполнен. Но после того, как аналитик, наконец, получал долгожданный ответ, достаточно часто оказывалось, что решение не могло ждать и оно уже принято, или, что еще чаще, произошло взаимное непонимание и получен ответ не на совсем тот вопрос.
| Характеристика
|
Статический анализ
|
Динамический анализ
|
| Типы вопросов |
Сколько? Как? Когда? |
Почему? Что будет, если? |
| Время отклика |
Не регламентируется |
Секунды |
| Типичные операции |
Регламентированный отчет, диаграмма |
Последовательность интерактивных отчетов, диаграмм, экранных форм.
Динамическое изменение уровней агрегации и срезов данных. |
| Уровень аналитических требований |
Средний |
Высокий |
| Тип экранных форм |
В основном, определенный заранее, регламентированный |
Определяемый пользователем |
| Уровень агрегации данных |
Детализированные и суммарные |
В основном, суммарные |
| Возраст данных |
Исторические и текущие и прогнозируемые |
Исторические, текущие и прогнозируемые |
| Типы запросов |
В основном, предсказуемые |
Непредсказуемые, от случаю к случаю |
| Назначение |
Регламентированная аналитическая обработка |
Многопроходный анализ, моделирование и построение прогнозов |
Таблица 3.
Сравнение характеристик статического и динамического анализа.
У истоков концепции многомерного динамического анализа - OLAP, стоит основоположник реляционного подхода Э. Кодд [2], сформулировавший 12 основных требований к средствам реализации OLAP.
Заметим, что у Кодда, термин "OLAP" обозначает исключительно конкретный способ представления данных на концептуальном уровне - многомерный.
Однако исторически сложилось так, что сегодня термин "OLAP" подразумевает не только многомерный взгляд на данные со стороны конечного пользователя, но и многомерное представление данных в целевой БД [33]. Именно с этим связано появление в качестве самостоятельного термина "Реляционный OLAP" (ROLAP).
Закономерен вопрос, как взаимно соотносятся концепции: Хранилищ Данных и различные концепции анализа данных (например, как соотносятся концепция Хранилищ Данных и OLAP/ROLAP)? По-видимому, правильный ответ состоит в том, что формально обе они говорят об одном и том же: "Что требуется для успешной реализации информационной системы, ориентированной на аналитическую работу с данными". Но, однако, это два различных взгляда.
Взгляд со стороны конечного пользователя (выраженный Э. Коддом), который главным образом сосредоточен на концептуальном уровне представления данных и на выработке методологии анализа данных. При этом он, естественно, говорит о том, что исходные данные могут храниться в различных источниках и должны быть обеспечены эффективные средства для их выборки и транспортировки. Но для него эти процессы вторичны, а главное состоит в том, что конечному пользователю должен быть предоставлен максимально комфортный и эффективный инструментарий визуализации и манипулирования данными - OLAP Tools.
Взгляд со стороны специалиста, отвечающего за реализацию и сопровождение системы (выраженный Б. Инмоном), который также вполне естественно говорит о том, что конечной целью Хранилища Данных является обеспечение информационных потребностей конечных пользователей (менеджеров и аналитиков). Но для него главное - выявление наиболее общих свойств и характеристик данных. Решение вопросов сбора, транспортировки, очистки, согласования и агрегации данных из различных внешних источников.
Таким образом, формально говоря об одном и том же, эти концепции не конкурируют, а скорее, взаимно дополняют друг друга.
В то же время эти концепции никак непосредственно не взаимосвязаны. Хранилище Данных может использоваться исключительно как источник для регламентированных аналитических сводок и отчетов или для регламентированной статистической обработки, но не для OLAP. А OLAP-инструментарий может быть с успехом использован для непосредственной работы с оперативными данными из традиционной СОД.
1.3 Технологии и средства реализации
1.3.1 Вопросы реализации Хранилищ Данных
Аналитические системы всегда предъявляли существенно более высокие, чем традиционные СОД, требования к аппаратному обеспечению и программному обеспечению. И, приступая к построению ХД, следует учитывать необходимость разрешения таких вопросов, как:
1. неоднородность программной среды;
2. распределенность;
3. защита данных от несанкционированного доступа;
4. построение и ведение многоуровневых справочников метаданных;
5. эффективное хранение и обработка очень больших объемов данных.
1 Неоднородность программной среды
Основополагающим отличием Хранилищ Данных от традиционных СОД является то, что они практически никогда не создаются на пустом месте. И почти всегда конечное решение будет разнородным (с точки зрения производителей программных средств, принципов построения, операционных систем).
Основа Хранилищ Данных - не внутренние, как в большинстве традиционных СОД, а внешние источники данных: различного рода информационные системы, электронные архивы, общедоступные и коммерческие электронные каталоги, справочники, статистические сборники. Как правило, сегодня в любой организации реально функционирует множество несвязанных или слабо связанных СОД. В большинстве случаев они создавались в различное время, различными коллективами разработчиков и реализованы на основе различных программных и аппаратных средств. Таким образом, уже сама основа, на которой будет строиться Хранилище Данных, чаще всего уже является крайне не однородной. Добавьте сюда средства выгрузки, транспортировки, реализации целевой БД Хранилища Данных.
Очевидно, что в таких условиях даже говорить об однородности программных средств чрезвычайно сложно. И практически всегда задача построения Хранилища Данных - это задача построения единой, согласованно функционирующей, информационной системы на основе неоднородных программных средств и решений. И уже сам выбор средств реализации Хранилища Данных становится чрезвычайно сложной задачей. Здесь должно учитываться множество факторов, включая взаимную совместимость различных программных компонентов, легкость их освоения и использования, эффективность функционирования, стабильность и даже формы, уровень и потенциальную перспективность взаимоотношений различных фирм производителей.
2 Распределенность
Хранилища Данных уже по своей природе являются распределенным решением.
В основе концепции Хранилищ Данных лежит физическое разделение узлов, где выполняется операционная обработка, от узлов, в которых выполняется анализ данных. И хотя при реализации такой системы нет необходимости в строгой синхронизации данных в различных узлах (например на основе средств двухфазной фиксации транзакций), средства асинхронной асимметричной репликации данных являются неотъемлемой частью практически любого решения.
3 Защита данных от несанкционированного доступа;
Собрав в одном месте всю информацию об истории развития организации, ее успехах и неудачах, о взаимоотношениях с поставщиками и заказчиками, об истории развития и состоянии рынка, менеджеры получают уникальную возможность для анализа прошлой деятельности, сегодняшнего дня и построения обоснованных прогнозов на будущее. Однако не следует забывать и о том, что, если не обеспечены надлежащие средства защиты и ограничения прав доступа, вы можете снабдить этой информацией и ваших конкурентов.
Одним из первых же вопросов, встающих при обсуждении проекта Хранилища Данных, является вопрос защиты данных. Чисто психологически, многих пугают не столько затраты на реализацию системы Хранилищ Данных (чаще всего есть понимание, что эффект от ее использования будет больше), а то, что доступ к критически значимой информации может получить кто-либо, не имеющий на это права.
В таких системах часто оказывается недостаточно защиты, обеспечиваемой в стандартных конфигурациях коммерческих СУБД (обычно уровень защиты по классу "C2 Orange Book"). Региональный менеджер должен видеть только те данные, которые относятся к его региону, а менеджер подразделения не должен видеть данные, относящиеся ко всей фирме. Но для повышения эффективности доступа к данным, в целевой БД Хранилища Данных все эти данные, как правило, хранятся в виде единой фактологической таблицы. Следствием этого является то, что средства реализации должны поддерживать ограничения доступа не только на уровне отдельных таблиц и их колонок, но и отдельных строк в таблице (класс "B1 Orange Book").
Не менее остро стоят и вопросы авторизации и идентификации пользователей, защиты данных в местах их преобразования и согласования, в процесс их передачи по сети (шифрование паролей, текстов запросов, данных).
4 Построение и ведение многоуровневых справочников метаданных
Наличие метаданных и средств их представления конечным пользователям - это один из основополагающих факторов успешной реализации Хранилища Данных. Более того, без наличия актуальных, максимально полных и легко понимаемых пользователем описаний данных Хранилище Данных превращается в обычный, но очень дорогостоящий электронный архив.
Первая же задача, с которой сталкиваешься при проектировании и реализации системы Хранилищ Данных, заключается в необходимости одновременной работы с самыми разнородными внешними источниками данных, несогласованностью их структур и форматов, масштабами и количеством архивов, которые должны быть переработаны и загружены. И при построении такой системы разработчику сложно обойтись без высокоуровневых средств описания информационной модели системы. Причем эта модель должна содержать описания не только целевых структур данных в БД Хранилища, но и структур данных в источниках их получения (различных информационных системах, архивах, электронных справочниках и т. д.), правила, процедуры и периодичность их выборки и выгрузки, процедуры и места согласования и агрегации.
Здесь следует сделать несколько замечаний относительно выбора конкретных средств проектирования. Как уже было сказано выше, характерными свойствами аналитической системы, являются:
- разнородность компонентов;
- ориентированность на нерегламентированную работу с данными.
Рассмотрим, как это влияет на выбор и требования к средствам проектирования. С одной стороны, из-за разнородности программных и системных компонентов, образующих Хранилища, и малой доли регламентированных пользовательских приложений, чаще всего результатом проектирования системы будет не готовый к исполнению программный продукт (что является обычным требованием для средств проектирования СОД), а база метаданных, содержащая всестороннее многоуровневое описание целевой информационной системы. С другой стороны, как будет показано ниже, в аналитических системах именно вопросы полноты, актуальности, простоты использования и понимания метаданных приобретают особую актуальность.
О значимости метаданных в информационных системах говорится много. Тем не менее на практике в подавляющем большинстве традиционных СОД их роль, по крайней мере, с точки зрения конечного пользователя, не очень велика. С чем это связано? Для того чтобы ответить на этот вопрос, рассмотрим три основных категории специалистов, работающих с СОД: конечные пользователи, системные администраторы, разработчики.
Конечные пользователи - это наиболее массовый слой специалистов, работающих с СОД. Именно они, в конечном счете, являются основными заказчиками и пользователями системы. Но в случае традиционной СОД, которую можно сравнить с хорошо отлаженным заводским конвейером, именно они, как правило, и не получают никаких преимуществ ни от наличия, ни от отсутствия базы метаданных. Обязанности и функции каждой категории конечных пользователей обычно четко оговорены в соответствующих инструкциях ("Инструкция оператора", "Инструкция пользователя" и т. д.), а всю уточняющую информацию они могут получить с помощью специальных регламентированных подсказок и комментариев.
Более того, обычно предполагается, что чем меньше от пользователя требуется знаний о структурах и потоках данных, взаимосвязях и взаимозависимостях различных программных компонентов, тем лучше реализована информационная система. В таких системах обычно не только не приветствуется, но и даже не допускается возможность свободной импровизации с данными и процедурами их обработки. Здесь преднамеренно не рассматриваются случаи, когда у конечного пользователя возникает необходимость в выполнении нового, заранее непредусмотренного, запроса (выборки), так как этот вид деятельности свойственен аналитической, а не оперативной системе.
Администраторы БД - категория специалистов, основной задачей которых является поддержание СОД в актуальном рабочем состоянии. Их, как правило, интересует не семантика данных, а способы их физического представления и организации. Администратор обычно не работает с конкретными значениями данных, не занимается написанием новых и модернизацией уже существующих прикладных программ. И хотя потребность в наличии и доступности метаданных у этой категории специалистов высока, их обычно вполне устраивают ограниченные описания данных, содержащиеся в традиционных справочниках БД. И даже, несмотря на то что структура описаний в таких справочниках достаточно сложна для понимания, это также не вызывает особых нареканий. Число администраторов обычно невелико, и они, как правило, обладают достаточной квалификацией и опытом работы.
Разработчики - категория специалистов, ответственных за разработку и дальнейшее развитие СОД. Наличие метаданных (данных о данных) является необходимым условием успешной реализации любой СОД. И именно при разработке (модернизации) СОД эта информация формируется и активно используется. Однако формируется, не означает того, что формируется электронный образ общедоступной и общепонятной базы метаданных. Более того, даже если при разработке информационной системы используется CASE-инструментарий:
- результирующие описания, в первую очередь, ориентированы и будут полезны разработчикам, но никак не пользователям и в меньшей степени администраторам системы;
- в процессе эксплуатации СОД изменения в прикладные программы и даже в структуры данных, часто вносятся напрямую, а не через CASE-инструментарий.
Поэтому, через непродолжительный промежуток времени, описания данных, сформированные в процессе разработки, перестают соответствовать реальности.
Существенно иная ситуация в случае информационных систем, ориентированных на аналитическую работу с данными (таблица 4). Здесь наличие метаданных и средств их представления конечным пользователям является одним из основополагающих факторов успешной реализации системы. Для конечного пользователя база метаданных является тем же самым, что и путеводитель для туриста, попавшего в незнакомый город. Прежде чем сформулировать свой вопрос к системе, менеджер должен понять, какая информация в ней есть, ее актуальность, насколько ей можно доверять и даже сколько времени может занять формирование ответа. Поэтому для конечного пользователя крайне важно и желательно, чтобы в системе содержались не только описания собственно структур данных, их взаимосвязей, предвычисленных уровней агрегации, но источников получения данных. Аналитику желательно не просто знать о том, какие данные есть в системе, но и источники их получения и степень их достоверности. Например, одна и та же информация может попасть в Хранилище Данных из различных источников. В этом случае пользователь должен иметь возможность узнать, какой источник выбран в качестве основного и каким образом выполнялись согласование и очистка исходных данных; периодичности обновления. Пользователю желательно не просто знать, какому моменту времени соответствуют те или иные данные, но и когда они будут обновлены; собственников данных. В отличие от традиционных СОД, где пользователь видит только то, что ему разрешено, здесь пользователю будет полезно знать:
- какие еще данные есть в системе;
- кто является их собственником;
- какие шаги он должен предпринять, чтобы получить к ним доступ;
- статистические оценки запросов.
Еще до выполнения запроса пользователю желательно иметь хотя бы приблизительную оценку времени, которое потребуется для получения ответа, и представлять, каков будет объем этого ответа.
| Уровень приложения (внешних источников данных) |
Описывает структуру данных в операционных БД и других источниках данных. Обычно, этот уровень достаточно сложен для понимания неподготовленного пользователя и является приложение ориентированным |
| Уровень ядра Хранилища Данных |
Описывает логическую и физическую структуру и взаимосвязи данных в Хранилище Данных. |
| Уровень конечного пользователя |
Описывает структуры данных в Хранилище Данных в терминах предметной области конечного пользователя. |
Таблица 4.
Уровни метаданных в Хранилище Данных.
5 Хранение и обработка очень больших объемов данных.
Когда мы говорим о целевой БД Хранилища Данных, то подразумеваем, что это нечто очень большое (таблица 5). Но насколько большое? Согласно данным Meta Group, уже сегодня около половины организаций планируют Хранилища в 100 гигабайт и более. И уже известны реализации систем с терабайтами данных.
| Маленькое Хранилище Данных |
До 3 Гбайт |
До нескольких миллионов строк в одной таблице |
| Среднее Хранилище Данных |
До 25 Гбайт |
До ста миллионов строк в одной таблице |
| Большое Хранилище Данных |
До 200 Гбайт |
До нескольких сотен миллионов строк в одной таблице |
| Очень Большое Хранилище Данных |
Свыше 200 Гбайт |
Сотни миллионов или миллиарды строк в одной таблице |
Таблица5.
Классификация ХД в соответствии с объемом целевой БД.
Причем, когда говорится о 100 гигабайтах исходных данных, следует понимать, что реальное дисковое пространство, требуемое для реализации целевой БД, будет несколько больше. Коэффициенты увеличения данных при помещении в ХД составляют от нескольких единиц до нескольких десятков.
1.3.2 Основные компоненты Хранилищ Данных.
Основными компонентами Хранилищ Данных являются:
1) ПО промежуточного слоя.
Обеспечивает сетевой доступ и доступ к базам данных. Сюда относятся сетевые и коммуникационные протоколы, драйверы, системы обмена сообщениями и пр.
2) Транзакционные БД и внешние источники информации.
Базы данных OLTP-систем исторически предназначались для эффективной обработки структур данных в относительно небольшом числе четко определенных транзакций. Из-за ограниченной целевой направленности "учетных" систем применяемые в них структуры данных плохо подходят для систем поддержки принятия решений. Кроме того, возраст многих установленных OLTP-систем достигает 10 - 15 лет.
3) Уровень доступа к данным.
Относящееся сюда ПО обеспечивает общение конечных пользователей с информационным хранилищем и загрузку требуемых данных из транзакционных систем. В настоящее время универсальным языком общения служит язык структурированных запросов (SQL).
4) Загрузка и предварительная обработка.
Этот уровень включает в себя набор средств для загрузки данных из OLTP-систем и внешних источников. Выполняется, как правило, в сочетании с дополнительной обработкой: проверкой данных на чистоту, консолидацией, форматированием, фильтрацией и пр.
5) Информационное хранилище.
Представляет собой ядро всей системы - один или несколько серверов БД.
6) Метаданные.
Метаданные (репозиторий, "данные о данных"). Играют роль справочника, содержащего сведения об источниках первичных данных, алгоритмах обработки, которым исходные данные были подвергнуты, и т. д.
7) Уровень информационного доступа
Обеспечивает непосредственное общение пользователя с данным DW посредством стандартных систем манипулирования, анализа и предоставления данных типа MS Excel, MS Access, Lotus 1-2-3 и др.
8) Уровень управления (администрирования)
Отслеживает выполнение процедур, необходимых для обновления информационного хранилища или поддержания его состояния. Здесь программируются процедуры подкачки данных, перестройки индексов, выполнения итоговых (суммирующих) расчетов, репликации данных, построения отчетов, формирования сообщений пользователям, контроля целостности и др.
1.4 Подходы и имеющиеся решения
1.4.1 Data Warehouse Framework
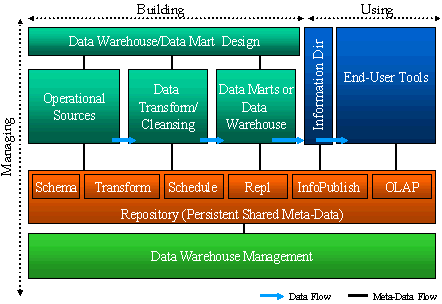 Архитектура Microsoft Data Warehousing Framework представляет собой план разработки и интеграции продуктов, базирующихся на платформе Microsoft. В рамках этой инфраструктуры предоставляется объектно-ориентированный комплект компонентов, обеспечивающих Рисунок 3. Data Warehousing Framework Архитектура Microsoft Data Warehousing Framework представляет собой план разработки и интеграции продуктов, базирующихся на платформе Microsoft. В рамках этой инфраструктуры предоставляется объектно-ориентированный комплект компонентов, обеспечивающих Рисунок 3. Data Warehousing Framework
управление информацией в распределенной среде
Data Warehousing Framework описывает связи между различными компонентами, используемыми в процессе создания, использования и администрирования хранилища данных. Ядром Data Warehousing Framework является набор продуктивных технологий, включающий в себя уровень транспортировки данных (OLE DB) и интегрированный репозитарий метаданных. Эти две технологии обеспечивают интегрируемость множества продуктов и инструментальных средств, используемых в процессе построения хранилища данных.
Создание хранилища данных требует применения набора инструментальных средств для описания логической и физической структуры источников данных и мест их назначения в хранилищах или киосках данных. Оперативные данные должны пройти этап очистки и преобразования перед помещением в хранилище или киоск данных, чтобы соответствовать сформированным на этапе проектирования спецификациям. Такой процесс поэтапной обработки данных на практике часто бывает многоуровневым, особенно в архитектурах, использующих общекорпоративные хранилища, но на приведенной выше схеме он изображен для экономии места в упрощенном виде.
Для обеспечения доступа к информации хранилища данных применяются инструменты конечных пользователей. В идеальном случае, пользовательский доступ осуществляется через некоторое средство работы с каталогами, предоставляющее возможность поиска именно тех данных, которые нужны пользователю для решения вопросов бизнеса, а также обеспечивающее необходимый уровень защиты, лежащий между пользователями и серверными системами.
Центром интеграции метаданных ("данных о данных"), совместно используемых разнообразными инструментами, участвующими в процессе построения хранилища данных, служит репозитарий Microsoft Repository. Эти совместно используемые метаданные обеспечивают прозрачную интеграцию множества инструментальных средств различных производителей, устраняя необходимость в специализированных интерфейсах между каждой парой продуктов.
1.4.2 A Data Warehouse Plus.
Решение компании IBM называется A Data Warehouse Plus
. Целью компании является обеспечение интегрированного набора программных продуктов и сервисов, основанных на единой архитектуре. Основой хранилищ данных является семейство СУБД DB2. Преимуществом IBM является то, что данные, которые нужно извлечь из оперативной базы данных и поместить в хранилище данных, находятся в системах IBM. Поэтому естественная тесная интеграция программных продуктов.
Предлагаются три решения для хранилищ данных:
(1) Изолированная витрина данных.
Предназначен для решения отдельных задач вне связи с общим хранилищем корпорации.
(2) Зависимая витрина данных.
Аналогичен изолированной витрине данных, но источники данных находятся под централизованным контролем.
(3) Глобальное хранилище данных.
Корпоративное хранилище данных, которое полностью централизовано контролируется и управляется. Глобальное хранилище данных может храниться централизовано или состоять из нескольких распределенных в сети рынков данных.
1.
4.3 Warehouse Technology Initiative
Решение компании Oracle в области хранилищ данных основывается на двух факторах: широкий ассортимент продуктов самой компании и деятельность партнеров в рамках программы Warehouse Technology Initiative. Корпорация Oracle исходит из того, что Хранилище данных – это архитектура и технология
, а не готовый продукт или семейство продуктов.
Общая архитектура решения представлена на рис.4
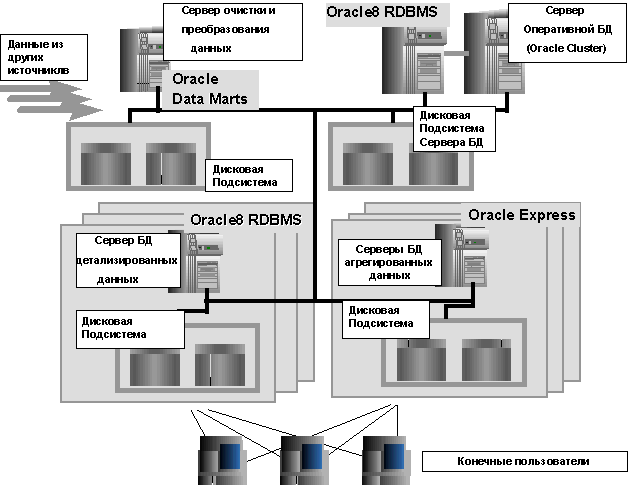
Рисунок.4.
Архитектура СППР
Oracle Data Marts Builder -- специализированный инструментарий, предназначенный для автоматизации процессов выгрузки, транспортировки и преобразования данных(рис.5).
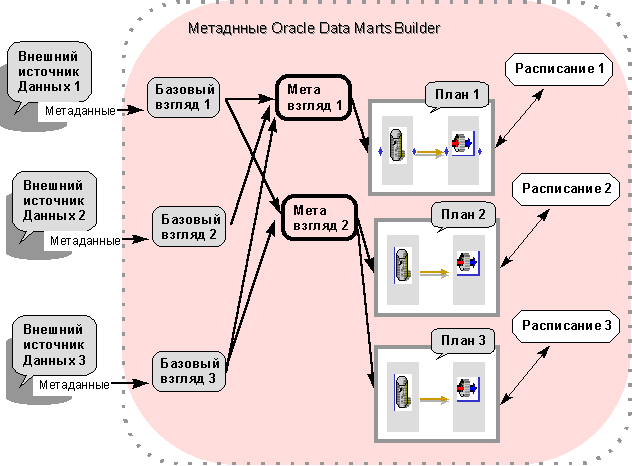
Рисунок 5. Структура метаданных Oracle Data Marts Builder
Выгрузка, транспортировка и согласование данных осуществляется в автоматическом
режиме, на основе Планов и Расписаний, составленных на этапе разработки системы. Вся информация необходимая для реализации этих процедур хранится в виде единого справочника метаданных в БД Oracle.
Средство обеспечивает возможность определения множества различных источников данных, в качестве которых могут выступать различные СУБД, а так же плоские файлы.
Проектирование процедур выгрузки, транспортировки и согласования данных осуществляется в следующей последовательности.
1. Определяются сетевые адреса серверов, из которых, будет выполняться выгрузка и транспортировка данных. В частом случае, это может быть тот же север на котором выполняется Oracle Data Marts Builder.
2. Для каждого источника данных автоматически формируется отдельный Базовый взгляд. Для этого Oracle Data Marts Builder связывается, через ODBC или напрямую, с БД источником и выгружает оттуда описания (структуру таблиц, типы полей и, если они определены, отношения типа - основной/внешний ключ) целевых структур данных. В дальнейшем, эти описания запоминаются и хранятся в соответствующих разделах базы метаданных Oracle Data Marts Builder.
3. На основе одного или нескольких Базовых взглядов формируется обобщённый Мета взгляд. При этом, маскируется тот факт, что различные таблицы данных на физическом уровне хранятся в различных узлах и с помощью различных средств. На этом же этапе, проектировщик имеет возможность:
удалить из описаний структур поля, не используемые в процедурах преобразования, согласования и загрузки данных;
добавить к описаниям структур, новые вычисляемые поля и определить формулы, по которым будут формироваться их значения.
4. Определяются процедуры (Планы) преобразования и согласования данных. Планы составляются на специальном высокоуровневом языке).
При составлении плана используется набор настраиваемых встроенных функций, В состав стандартного набора входит более 20 различных функций, например, таких как:
- выбрать данные из плоского файла с разделителями;
- выбрать данные из таблицы БД;
- удалить колонку из таблицы;
- найти и заменить один набор символов на другой;
- выполнить сортировку;
- заменить значение (текстовый дескриптор) его идентификатором (кодом),
- ранящимся во внешней таблице;
- выполнить сортировку;
- сформировать значение ключевого поля типа время;
- расщепить входной поток данных на два;
- объединить два потока данных в один;
- добавить данные в целевую таблицу;
- вызвать SQL Loader и передать данные на его вход;
- запомнить данные в виде плоского файла с разделителями;
- вывести данные на печать;
обеспечивающих возможность выборки, преобразования, согласования и загрузки данных. При необходимости этот набор может быть расширен самим разработчиком.
6. Для каждого Плана (или группы Планов) составляется расписание их выполнения).
При составлении расписания, разработчик имеет возможность определить действия, которые должны быть выполнены при возникновении различных сбойных или ошибочных ситуаций.
1.4.4 Warehouse WORKS.
В реальной жизни процессу создания хранилища данных зачастую предшествует разработка прототипа - небольшой системы, призванной продемонстрировать новые возможности, чтобы, попробовав систему в работе, сделать выводы о необходимости продолжения дальнейшей разработки.
Такая система, называемая далее витриной данных (ВД) - это небольшое хранилище, обеспечивающее потребности одного из подразделений компании, или одного из направлений бизнеса. ВД не требует, хотя и не исключает, наличие корпоративного ХД, охватывающей сразу все аспекты ее жизнедеятельности организации. Как правило, она доступна ограниченному кругу аналитиков, для работы которых она и создавалась. Стоимость разработки такой ВД намного ниже, чем корпоративного ХД, а результат ее внедрения может окупиться много быстрее. Параллельно с созданием ВД, может идти процесс проектирования корпоративного ХД.
Sybase выпустила интегрированный комплект базовых программных продуктов для ХД под названием Warehouse Studio для решения всех задач, связанных с созданием, управлением и развитием ХД и ВД. Среди этих продуктов - сервера для хранения и управления бизнес-информации, связующее ПО для доступа к распределенным источникам данных, средства разработки для построения систем поддержки принятия решений.
Корпоративная архитектура ХД компании Sybase представляет собой интегрированный набор программных продуктов Sybase и ее партнеров, позволяющих создавать масштабируемые приложения для DSS в рамках единой архитектуры, способной сохранить целостность и непротиворечивость данных, а также обеспечить свое развитие ХД в будущем.
Компонентная адаптивная архитектура Sybase (ImpactNOW) обеспечивает наиболее широкие возможности по повторному использованию стандартных компонент, причем всех основных форматов объектов -- ActiveX, JavaBeans, CORBA. Кроме того, она позволяет использовать их на любой уровне: клиента, сервера баз данных, промежуточного слоя. Это обеспечивает быструю разработку приложений, их высокую производительность, расширяемость и надежность.
SAFE/DW (Data Warehouse) - методология разработки хранилищ данных которая предлагает ряд подходов, позволяющих ускорить процесс построения ХД. В частности, в рамках исследовательской стадии проекта она требует определить бизнес-цели, информационные запросы, определить критические для успеха факторы, разработать предварительную бизнес-модель. В рамках создания бизнес-модели требуется идентифицировать потоки данных, выявить относительную ценность данных, смакетировать потоки данных в логическую структуру объектов.
2 глава Исследование методов организации структуры данных для аналитических систем.
2.1 СУБД для аналитических систем
2.1.1
РСУБД
Сегодня РСУБД стали доминирующим промышленным решением при реализации самых разнообразных СОД. Они обеспечивают приемлемые времена отклика при произвольной выборке отдельных записей и небольших групп записей. А реальные объемы БД, с которыми они умеют работать, превышают сотни гигабайт. Более того, сегодня известны, правда, пока на уровне демонстрационных версий БД с объемом в несколько терабайт. Однако, исходно ориентированные на реализацию систем операционной обработки данных, РСУБД оказались менее эффективными в задачах аналитической обработки. С чем это связано?
Во-первых, из-за наличия достаточно жестких ограничений накладываемых существующей реализацией языка SQL, аналитические запросы получаются весьма громоздкими, а многие функции обработки приходится выносить в заранее написанные пользовательские приложения. И если вопрос о том, что громоздкость конструкций это серьезный недостаток, достаточно спорный (сегодня практически никто не пишет непосредственно на SQL, а соответствующие конструкции автоматически генерируются средствами клиентского инструментария), то ограничения SQL реально существуют, и их так просто не обойти.
Примером такого реально существующего ограничения является предположение о том, что данные в реляционной базе не упорядочены (или, более точно, упорядочены случайным образом). Но выполнение большинства аналитических функций (например построение прогноза), наоборот, невозможно без предположения об упорядоченности данных. Естественно, при использовании реляционной базы имеется возможность после выборки данных из базы, выполнить их сортировку и затем построить прогноз. Но это потребует дополнительных затрат времени на сортировку; сортировка должна будет проводиться каждый раз при обращении к этой функции, и, самое главное, такая функция может быть определена и применена только в пользовательском приложении, но не может быть встроенной функцией языка SQL.
Во-вторых, для обеспечения приемлемого времени ответа, при использовании РСУБД, нужно уже на этапе проектирования знать обо всех возможных типах запросов, необходимых срезах и уровнях агрегации данных.
Основой традиционного реляционного подхода является нормализация (декомпозиция) таблиц, подразумевающая устранение избыточности в основных ключах таблиц и устранение транзитивных зависимостей между реквизитами, образующими таблицу. Это позволяет не только минимизировать суммарный объем данных в БД, но и решает проблемы, связанные с различного рода аномалиями, возникающими при удалении и модификации данных в ненормализованных таблицах. И хотя в процессе нормализации утрачиваются и семантические связи, существующие между реквизитами, это не особенно критично для традиционных СОД. Те немногие связи, которые необходимы для реализации конкретного приложения, известны заранее и легко реализуются с помощью механизма внешних ключей. Более критична эта проблема для аналитических систем. Здесь обычно даже нельзя заранее определить, какие связи между различными реквизитами будут применяться более часто, а какие не будут использоваться вообще. Все зависит от неординарности мышления конкретного аналитика, ситуации на рынке, в фирме и многих других факторов.
Но основной недостаток традиционных РСУБД заключался в том, что в качестве основного и часто единственного механизма, обеспечивающего быстрый поиск и выборку отдельных строк в таблице (или в связанных через внешние ключи таблицах), обычно используются различные модификации индексов, основанных на B-деревьях. Но такое решение оказывается эффективным только при обработке небольших групп записей и высокой интенсивности модификации данных в БД. В аналитических системах ввод и выборка данных осуществляется большими порциями. А данные, после того как они попадают в БД, остаются неизменными в течение длительного периода времени. И здесь более эффективным оказывается хранение данных в форме частично денормализованных таблиц, в которых для увеличения производительности могут храниться не только детализированные, но и предварительно вычисленные агрегированные значения, а для навигации и выборки - использоваться специализированные, основанные на предположении о малоизменчивости и малоподвижности данных в БД, методы адресации и индексации. Такой способ организации данных иногда называют предвычисленным, подчеркивая, тем самым, его отличие от нормализованного реляционного подхода, предполагающего динамическое вычисление различного вида итогов (агрегация) и установление связей между реквизитами из разных таблиц (операции соединения).
И все же, реляционные базы данных уже стали, и будут оставаться и в будущем, наиболее подходящей технологией для реализации информационных систем уровня предприятия. Главными причинами их неэффективности в аналитических приложениях являются не столько собственно недостатки реляционного подхода, сколько то, что производители РСУБД еще до недавнего времени просто не обращали внимания на рынок аналитических систем.
Но уже сегодня ситуация изменилась. И, пожалуй, главной новацией здесь является то, что сегодня официально признана необходимость и право на существование в реляционной БД таблиц с денормализованной формой - различные модификации схемы организации данных типа звезда
. В своем классическом варианте данная схема предполагает наличие одной денормализованной фактологической таблицы (количество строк в этой таблице обычно составляет десятки и сотни миллионов), с которой соотнесено несколько десятков относительно небольших справочных таблиц.
Другое направление развития РСУБД - поиск и реализация новых способов индексации и организации хранения данных, задачей которого является отсеять максимальное количество данных, не удовлетворяющих условиям запроса, еще до считывания их с внешнего накопителя, и одновременно иметь индекс такого размера, чтобы он легко умещался в оперативной памяти (или имел сопоставимый с ней размер).
Примерами таких индексов служат Bitmap-индексы, которые оказываются достаточно эффективными при работе с реквизитами, количество значений которых относительно невелико. Не меньший, если не больший выигрыш, может принести использование различных вариантов горизонтального или вертикального разделения таблиц (данных). Например, разделение одной большой фактологической таблицы на несколько отдельных фрагментов (горизонтальная фрагментация). Такое разбиение может производиться, например, в соответствии с временным интервалом, к которому относятся данные. Каждая из таких подтаблиц (фрагментов) имеет одну и ту же структуру, формат реквизитов, индексы. И каждый из этих фрагментов может обрабатываться независимо (например могут строиться и перестраиваться индексы). В запросе вся таблица может представляться как единое целое, причем фрагменты, не удовлетворяющие условиям выборки, могут быть легко отсечены, еще до момента их считывания с внешнего накопителя.
Другим подходом к повышению производительности является вертикальная фрагментация данных (она используется в решении фирмы Sybase). Предположим, что у нас имеется таблица из 10 000 000 строк, каждая строка состоит из 30 полей (колонок), по 10 символов (байт) каждое. Абстрагируясь от вопросов эффективности или неэффективности хранения данных в конкретной реализации РСУБД, предположим, что объем результирующей БД равен объему исходных данных. В этом случае мы получим БД размером в 3 гигабайта.
В традиционных реализациях РСУБД данные хранятся построчно, и при последовательном просмотре вне зависимости от того, значения из скольких колонок таблицы требуются для формирования ответа на запрос, будут считаны все 3 гигабайта данных. Но в аналитических запросах крайне редко возникает необходимость работы одновременно со всеми колонками таблицы. Именно на этом предположении и основывается механизм вертикальной фрагментации, при использовании которого данные хранятся не построчно, а по столбцам. Таким образом, каждый столбец представляет собой независимый раздел данных и при запросах на чтение может обрабатываться независимо. И если в нашем примере для формирования ответа на запрос потребуются значения из трех столбцов таблицы, нужно будет считать только 300 мегабайт, а не 3 гигабайта данных.
До сих пор мы в основном говорили о достоинствах различных способов повышения эффективности обработки аналитических запросов. Но ни один из этих подходов не является универсальным и равно эффективным во всех ситуациях. Сегодня производители РСУБД находятся на этапе поиска, и ни один из описанных выше механизмов не может быть общепризнан, бесспорен и универсален.
Оптимизаторы обработки запросов со схемой звезда.
Наиболее широко распространенный на сегодняшний день, способ оптимизации запросов типа звезда предполагает построение промежуточной таблицы, являющейся декартовым произведением используемых в запросе справочных таблиц. И только затем выполняется последовательный просмотр, но уже только двух таблиц (фактологической и промежуточной), в процессе которого и отсеиваются все строки, неудовлетворяющие условиям выборки. К сожалению, в ряде случаев такое решение может только, наоборот, увеличить время обработки или вообще сделать выполнение запроса невозможным.
Покажем это на примере. Такой способ оптимизации дает эффект только тогда, когда промежуточная таблица умещается в оперативной памяти. Но это не всегда так. Если запрос ссылается на 10 справочных таблиц, в каждой из которых всего 10 строк длиной в 40 символов, в результате декартова произведения мы получим промежуточную таблицу в 10 млрд. строк. А объем оперативной памяти, необходимый для размещения такой таблицы, составит 400 гигабайт. И это без учета памяти для операционной системы, системных программ СУБД и буфера для просмотра теперь уже ставшей относительно маленькой фактологической таблицы.
Bitmap-индексы
Бесполезны при малом числе различных значений в индексируемой колонке. Предположим, что индексируется поле "Пол Сотрудника". Здесь мы имеем всего два значения: Мужской/Женский. И если данные не были заранее упорядочены по этому полю, и оно используется в качестве критерия выборки, скорее всего, придется считать всю таблицу. Это связано с тем, что на физическом уровне считывается не отдельная строка, а блок, в котором размещены значения нескольких строк, и вероятность того, что в каждом блоке записаны только строки, относящиеся к мужскому или женскому полу, настолько невелика, что применение Bitmap-индексов только замедлит выполнение запроса.
Бесполезны при большом (более нескольких сотен) количестве различных значений в индексируемой колонке. В этом случае требуется использование различных вариантов комбинированных методов индексирования (комбинация B-деревьев, битовых массивов и списков идентификаторов записей).
Как правило, значительно снижают производительность системы при выполнении операций обновления данных.
Горизонтальное разбиение данных
Разбиение таблицы может производиться только в соответствии со значениями данных одной колонки таблицы.
Например, если в таблице содержится информация о продаже товаров в регионах (50 регионов) за последние 48 месяцев, имеет смысл разбить таблицу или по регионам (каждый фрагмент соответствует определенному региону), или по времени (каждый фрагмент соответствует определенному месяцу). Но каждое из этих решений ускорит обработку лишь определенного фиксированного класса запросов.
Вертикальное разбиение данных
Эффективно только в том случае, если при выполнении запроса требуется просмотр всего нескольких колонок таблицы, и чем меньше соотношение - "Число колонок в таблице/Число колонок, на которые есть ссылки в запросе", тем менее эффективным оказывается данный метод.
Методы хранения данных по строкам и по колонкам взаимно исключают друг друга, и решение о том, как будут храниться данные, должно быть принято заранее.
Не поддерживается транзакционная обработка данных, и очень сильно снижается производительность системы при выполнении операций обновления данных.
Таким образом, сегодня вновь складывается ситуация, от которой, казалось бы, давно и безвозвратно ушли. И вновь на первый план выносится значимость вопросов проектирования базы данных на физическом уровне: "Чтобы гибко формировать запросы и быстро получать результат, необходима гибкая комбинация разных высокоэффективных индексных структур. ...корпорации нуждаются в таких проектировщиках базы данных, которые понимали бы, что в ней находится и как она будет использоваться. Хороший проект базы данных на физическом уровне - это залог высокой производительности" (5). До боли знакомая цитата, но взятая из статьи 1996, а не 1976 года. Вспомним региональные и индексно-последовательные файлы, инвертированные списки, иерархические и сетевые БД.
К тому же от проектировщиков аналитической системы можно и даже нужно требовать, чтобы они понимали - что находится в БД. Но требовать от них того, чтобы они понимали, как она будет использоваться, просто нереально. Это требование хорошо для традиционной СОД, но никак не для системы, предполагающей нерегламентированную аналитическую обработку данных.
2.1.2
МСУБД
Более просто и эффективно аналитические системы реализуются средствами специализированных баз данных, основанных на многомерном представлении данных. В этих системах данные организованы не в виде плоских таблиц (как в реляционных системах), а в виде упорядоченных многомерных массивов - гиперкубов (или поликубов).
Очевидно, что такое решение требует большей суммарной памяти для хранения данных, больших затрат времени при их загрузке и является менее гибким при необходимости модификации структур данных. Но, как уже было сказано выше, в аналитических задачах все это окупается за счет более быстрого поиска и выборки данных, отсутствия необходимости в многократном соединении различных таблиц и многократного вычисления агрегированных значений. И, как правило, среднее время ответа на нерегламентированный аналитический запрос при использовании многомерной СУБД обычно на один-два порядка меньше, чем в случае реляционной СУБД с нормализованной схемой данных.
Казалось бы, все очевидно и выбор однозначен - многомерные БД. Однако не все так просто. Многомерные базы, в силу чисто исторических причин, "не умеют" работать с большими объемами данных. На сегодняшний день их реальный предел - база объемом в 10-20 гигабайт. И хотя данное ограничение не связано с какими-либо внутренними объективными недостатками многомерного подхода и, скорее всего, является временным, сегодня это так. С чем нельзя не считаться.
К тому же за счет денормализации и предварительно выполненной агрегации 20 гигабайт в многомерной базе, в лучшем случае, эквивалентны не более чем 1 гигабайту исходных данных. По оценкам Кодда [3], для систем, основанных на многомерном представлении данных, это соотношение лежит в диапазоне от 2.5 до 100. И здесь необходимо остановиться на основном недостатке многомерных БД - неэффективному, по сравнению с реляционными БД, использованию внешней памяти. И это уже объективный фактор.
В основе многомерного подхода лежит представление данных в виде многомерных гиперкубов, при этом обычно предполагается, что внутри такого гиперкуба нет пустот. То есть все ячейки куба всегда заполнены. Это связано с тем, что данные в них обычно хранятся в виде множества логически упорядоченных блоков (массивов), имеющих фиксированную длину, причем именно блок является минимальной индексируемой единицей. И хотя в МСУБД, как правило, подразумевается, что блоки, полностью заполненные неопределенными значениями, не хранятся, это обеспечивает лишь частичное решение проблемы. Данные в таких системах хранятся в упорядоченном виде. И неопределенные значения устраняются, и то частично, только в том случае, если мы за счет выбора порядка сортировки сгруппируем их в максимально большие непрерывные группы.
Но такое решение может напрямую вступить в конфликт с тем, что МСУБД работают очень быстро только тогда, когда данные в них заранее отсортированы в том порядке, в котором они должны быть отсортированы в ответе на запрос. Но порядок сортировки, наиболее часто используемый в запросах, может не совпадать с тем, в котором они должны быть отсортированы, для максимального устранения неопределенных (несуществующих) значений. В результате разработчик может оказаться перед трудноразрешимой дилеммой:
пожертвовать быстродействием, но это одно из главных достоинств и часто одна из основных причин выбора именно МСУБД;
пожертвовать внешней памятью, но увеличение объема данных также не повышает быстродействие. Кроме того, как уже говорилось, МСУБД в настоящее время не приспособлены для работы с большими объемами данных.
Таким образом, МСУБД однозначно хороши только при выполнении двух требований.
Уровень агрегации данных в БД достаточно высок, и, соответственно, объем БД не очень велик (не более нескольких гигабайт).
В качестве граней многомерного куба выбраны достаточно стабильные во времени реквизиты (с точки зрения неизменности их взаимосвязей), и, соответственно, число несуществующих значений относительно невелико.
К сожалению, сегодня отсутствуют официальные сравнительные результаты тестирования производительности систем, реализованных на основе многомерных и реляционных баз данных (некоторые дополнительные аргументы в пользу того и другого подхода приведены в таблице 7), но при этом общая оценка такова: "Производительность хорошо настроенных реляционных систем, при использовании схемы звезда, вполне сравнима с производительностью систем, реализованных на основе многомерных баз данных".
Многомерный подход
Для достижения сравнимой производительности реляционные системы требуют тщательной проработки схемы БД, определения способов индексации и специальной настройки. В случае многомерных БД, как правило, не требуется даже указание на то, по каким реквизитам (группам реквизитов) требуется индексация данных.
Ограничения SQL остаются реальностью, что не позволяет реализовать в РСУБД многие встроенные функции, легко обеспечиваемые в системах, основанных на многомерном представлении данных.
Производители РСУБД находятся на этапе поиска, и ни один из описанных выше механизмов не является бесспорным и универсальным.
Реляционный подход
РСУБД обеспечивают качественно более высокий уровень защиты данных (по классу B1 Orange Book) и разграничения прав доступа.
РСУБД имеют более развитые средства администрирования и реальный опыт работы с большими и сверхбольшими БД.
Для многомерных БД в настоящее время отсутствуют единые стандарты на интерфейс, языки описания и манипулирования данными.
МСУБД не поддерживают репликацию данных, наиболее часто используемую в качестве механизма загрузки.
|
Таблица 7. Дополнительные аргументы в пользу МСУБД и РСУБД.
2.2 Витрины Данных
Концепция Витрин Данных (Data Mart) была предложена Forrester Research еще в 1991 году. По мысли авторов, Витрины Данных - множество тематических БД, содержащих информацию, относящуюся к отдельным аспектам деятельности организации, должны были стать реальной альтернативой Информационным Хранилищам (Information Warehouse) фирмы IBM.
Концепция Витрин Данных имеет ряд несомненных достоинств.
Аналитики видят и работают только с теми данными, которые им реально нужны.
Целевая БД Витрины Данных максимально приближена к конечному пользователю.
Витрины Данных обычно содержат тематические подмножества заранее агрегированных данных, их проще проектировать и настраивать.
Для реализации Витрин Данных не требуются высокомощная вычислительная техника.
И именно Витрины Данных (или что-то очень близкое к ним) подразумевал Э. Кодд, когда использовал термин "OLAP Server".
Но концепция Витрин Данных имеет и очень серьезные пробелы. По существу, здесь имеется в виду реализация территориально-распределенной информационной системы с мало контролируемой избыточностью, но не предлагается способов для обеспечения целостности и непротиворечивости хранимых в ней данных.
Идея соединить две концепции - Хранилищ Данных и Витрин Данных, по-видимому, принадлежит М. Демаресту (M. Demarest), который в 1994 году в работе "Построение Витрин Данных" [6] предложил объединить две концепции и использовать Хранилище Данных в качестве единого интегрированного источника данных для Витрин Данных.
И сегодня именно такое многоуровневое решение:
первый уровень - общекорпоративная БД на основе РСУБД с нормализованной или слабо денормализованной схемой (детализированные данные);
второй уровень - БД уровня подразделения (или конечного пользователя), реализуемые на основе МСУБД (агрегированные данные);
третий уровень - рабочие места конечных пользователей, на которых непосредственно установлен аналитический инструментарий;
постепенно становится стандартом де-факто, позволяя наиболее полно реализовать и использовать достоинства каждого из подходов:
- компактного хранения детализированных данных и поддержки очень больших БД, обеспечиваемых РСУБД;
- простота настройки и хорошие времена отклика при работе с агрегированными данными, обеспечиваемыми МСУБД.
Реляционная форма представления данных, используемая в центральной общекорпоративной БД, обеспечивает наиболее компактный способ хранения данных. А современные РСУБД уже умеют работать даже с терабайтными базами. И хотя такая центральная система обычно не сможет обеспечить оперативного режима обработки аналитических запросов, при применении новых способов индексации и хранения данных, а также частичной денормализации таблиц, время обработки заранее регламентированных запросов (а в качестве таких можно рассматривать и регламентированные процедуры выгрузки данных в многомерные БД) оказывается вполне приемлемым.
В свою очередь, использование МСУБД в узлах нижнего уровня гарантирует минимальные времена обработки и ответа на нерегламентированные запросы пользователя. Кроме того, в некоторых МСУБД имеется возможность как хранить данные на постоянной основе (непосредственно в многомерной БД), так и динамически (на время сеанса) загрузить данные из реляционных БД (на основе регламентированных запросов).
Таким образом, имеется возможность хранить на постоянной основе только те данные, которые наиболее часто запрашиваются в данном узле. Для всех остальных хранятся только описания их структуры и программы их выгрузки из центральной БД. И хотя, при первичном обращении к таким виртуальным данным, время отклика может оказаться достаточно продолжительным, такое решение обеспечивает высокую гибкость и требует более дешевых аппаратных средств.
2.3. Выбор структуры Хранилища Данных
До выбора структуры, необходимо определиться с моделью данных. В самом простом варианте для Хранилищ Данных используется та модель данных, которая лежит в основе транзакционной системы. Если, как это часто бывает, транзакционная система функционирует на реляционной СУБД (Oracle, Informix, Sybase и т. п.), самой сложной задачей становится выполнение запросов ad-hoc, поскольку невозможно заранее оптимизировать структуру БД так, чтобы все запросы работали эффективно.
Однако практика принятия решений показала, что существует зависимость между частотой запросов и степенью агрегированности данных, с которыми запросы оперируют, а именно чем более агрегированными являются данные, тем чаще запрос выполняется. Другими словами, круг пользователей, работающих с обобщенными данными, шире, чем тот, для которого нужны детальные данные. Это наблюдение легло в основу подхода к поиску и выборке данных, называемого Оперативной Аналитической Обработкой (On-line Analytical Processing, OLAP).
OLAP-системы построены на двух базовых принципах:
все данные, необходимые для принятия решений, предварительно агрегированы на всех соответствующих уровнях и организованы так, чтобы обеспечить максимально быстрый доступ к ним;
язык манипулирования данными основан на использовании бизнес-понятий.
В основе OLAP лежит понятие гиперкуба, или многомерного куба данных, в ячейках которого хранятся анализируемые (числовые) данные, например объемы продаж. Измерения представляют собой совокупности значений других данных, скажем названий товаров и названий месяцев года. В простейшем случае двумерного куба (квадрата) мы получаем таблицу, показывающую значения уровней продаж по товарам и месяцам. Дальнейшее усложнение модели данных может идти по нескольким направлениям:
увеличение числа измерений - данные о продажах не только по месяцам и товарам, но и по регионам. В этом случае куб становится трехмерным;
усложнение содержимого ячейки - например нас может интересовать не только уровень продаж, но и, скажем, чистая прибыль или остаток на складе. В этом случае в ячейке будет несколько значений;
введение иерархии в пределах одного измерения - общее понятие ВРЕМЯ естественным образом связано с иерархией значений: год состоит из кварталов, квартал из месяцев и т. д.
Речь пока идет не о физической структуре хранения, а лишь о логической модели данных. Другими словами, определяется лишь пользовательский интерфейс модели данных. В рамках этого интерфейса вводятся следующие
- базовые операции:
- поворот;
- проекция. При проекции значения в ячейках, лежащих на оси проекции, суммируются по некоторому предопределенному закону;
- раскрытие (drill-down). Одно из значений измерения заменяется совокупностью значений из следующего уровня иерархии измерения; соответственно заменяются значения в ячейках гиперкуба;
- свертка (roll-up/drill-up). Операция, обратная раскрытию;
- сечение (slice-and-dice).
В зависимости от ответа на вопрос, существует ли гиперкуб как отдельная физическая структура или лишь как виртуальная модель данных, различают системы MOLAP (Multidimensional OLAP) и ROLAP (Relational OLAP). В первых гиперкуб реализуется как отдельная база данных специальной нереляционной структуры, обеспечивающая максимально эффективный по скорости доступ к данным, но требующая дополнительного ресурса памяти. MOLAP-системы весьма чувствительны к объемам хранимых данных. Поэтому данные из хранилища сначала помещаются в специальную многомерную базу (Multidimensional Data Base, MDB), а затем эффективно обрабатываются OLAP-сервером.
Для систем ROLAP гиперкуб - это лишь пользовательский интерфейс, который эмулируется на обычной реляционной СУБД. В этой структуре можно хранить очень большие объемы данных, однако ее недостаток заключается в низкой и неодинаковой эффективности OLAP - операций. Опыт эксплуатации ROLAP-продуктов показал, что они больше подходят на роль интеллектуальных генераторов отчетов, чем действительно оперативных средств анализа. Они применяются в таких областях, как розничная торговля, телекоммуникации, финансы, где количество данных велико, а высокой эффективности запросов не требуется.
В настоящее время получили развитие HOLAP системы, в которых часть данных хранится в ROLAP, а часть в MOLAP.
При определении программно-технологической архитектуры Хранилища следует иметь в виду, что система принятия решения, на какие бы визуальные средства представления она ни опиралась, должна предоставить пользователю возможность детализации информации. Руководитель предприятия, получив интегрированное представление данных и/или выводы, сделанные на его основе, может затребовать более детальные сведения, уточняющие источник данных или причины выводов. С точки зрения проектировщика СППР, это означает, что необходимо обеспечить взаимодействие СППР не только с Хранилищем Данных, но и в некоторых случаях с транзакционной системой.
Несколько лет назад для Хранилищ Данных было предложено использовать схемы данных, получившие названия "звезда" и "снежинка". Суть технологии проектирования этих схем заключается в выделении из общего объема информации собственно анализируемых данных (или фактов) и вспомогательных данных (называемых измерениями). Необходимо, однако, отдавать себе отчет в том, что это приводит к дублированию данных в Хранилище, снижению гибкости структуры и увеличению времени загрузки. Все это - плата за эффективный и удобный доступ к данным, необходимый в СППР.
Несмотря на то что предсказать, какую именно информацию и в каком виде захочет получить пользователь, работая с СППР, практически невозможно, измерения, по которым проводится анализ, достаточно стабильны. В процессе подготовки того или иного решения пользователь анализирует срез фактов по одному или нескольким измерениям. Анализ информации, исходя из понятий измерений и фактов, иногда называют многомерным моделированием данных (MultiDimensional Modelling, MDM). Таблицы фактов обычно содержат большие объемы данных, тогда как таблицы измерений стараются сделать поменьше. Этого подхода желательно придерживаться потому, что запрос по выборке из объединения таблиц выполняется быстрее, когда одна большая таблица объединяется с несколькими малыми. При практической реализации ХД небольшие таблицы измерений иногда удается целиком разместить в оперативной памяти, что резко повышает эффективность выполнения запросов.
Поскольку в Хранилищах Данных, наряду с детальными, должны храниться и агрегированные данные, в случае "снежинки" или "звезды" появляются таблицы агрегированных фактов (агрегатов). Подобно обычным фактам, агрегаты могут иметь измерения. Кроме того, они должны быть связаны с детальными фактами для обеспечения возможной детализации. На практике Хранилища часто включают в себя несколько таблиц фактов, связанных между собой измерениями, которые таким образом разделяются между несколькими таблицами фактов. Такая схема носит название "расширенная снежинка", и именно она, как правило, встречается в Хранилищах Данных.
Для достижения наивысшей производительности иногда используют подход, при котором каждая "звезда" располагается в отдельной базе данных или на отдельном сервере. Хотя такой подход приводит к увеличению размера дискового пространства за счет дублирования разделенных измерений, он может оказаться весьма полезным при организации Витрин Данных.
При проектировании структуры хранилища часто возникает желание использовать как можно больше агрегатов и за счет этого повысить производительность системы. Нетрудно подсчитать, что для модели "звезда" с 10 измерениями можно построить 10!=3.63 миллиона различных агрегированных значений, размещение которых в памяти при установлении связей с соответствующими измерениями приведет к резкому увеличению занимаемого дискового пространства и замедлению доступа к данным. Другая крайность состоит в использовании слишком малого числа агрегатов, а это может привести к необходимости выполнять агрегирование динамически, что заметно снижает эффективность запросов. По некоторым оценкам, при определении оптимального количества агрегатов следует придерживаться принципа 80:20 - 80% ускорения достигается за счет использования 20% кандидатов на агрегаты.
3. глава Проектирование Хранилищ Данных
3.1 Методология проектирования Хранилищ Данных
3.1.1
Планирование и проектирование
Этот этап включает в себя следующие задачи:
Подготовка проекта.
Включает в себя составление проектного соглашения. Здесь определяются цели ХД. Составляется календарный график выполнения работ.
Сбор требований.
Здесь происходит уяснение целей бизнеса. Определяются предметные области. Составляется предварительная библиотека запросов.
Определение модели данных.
Составляется модель данных ХД «звезда». Определяются объекты, отношения, элементы данных, спецификации защиты. Здесь определяем измерения и меры, а также иерархию измерений.
Модель процессов загрузки.
Определяются спецификации переноса данных и способы доступа к данным.
Модель приложений.
Определяются способы представления информации пользователю.
Определение архитектуры
. Создание технологической модели ХД. Рассмотрение альтернатив решения.
Оценка проекта.
Здесь проводится анализ результатов. Анализ риска, стоимости и выгод.
Далее если оценка удовлетворительная, то переходим к следующему этапу. Если нет, то возвращаемся на один из предыдущих этапов.
Проектное предложение
Составляется акт о завершении этапа. Имеется уже готовый проект.
3.1.2
Разработка
Этот этап включает в себя следующие задачи:
Построение БД
Необходимо оценить неоходимый размер
Построение, тест процесса переноса (загрузки) данных
Определяем средства доступа к источнику, приемнику. Определение видов трансформации данных.
Прототипы запросов и отчетов
Оценка проекта.
Здесь проводится анализ результатов.
Далее если оценка удовлетворительная, то переходим к следующему этапу. Если нет, то возвращаемся на один из предыдущих этапов.
Процедура начальной загрузки данных.
Выполнение доступа к источникам, преобразование данных: унификация, изменение структуры, проверка на корректность и непротиворечивость, очистка, агрегирование.
Процедуры регулярной загрузки данных
. Утверждение расписания загрузки.
Приложения
Финальное тестирование системы
Оценка проекта.
Здесь проводится анализ результатов.
Далее если оценка удовлетворительная, то переходим к следующему этапу. Если нет, то возвращаемся на один из предыдущих этапов.
Документация всех процедур.
Определение инфраструктуры поддержки.
Определение администраторов, регламент загрузки данных и создания резервной копии)
Обучение пользователей
3.1.3
Установка системы и эксплуатация
Инсталяция системных компонентов
Инициализация расписания процедур регулярной загрузки
Ввод в эксплуатацию
3.1.4
Анализ протекающих процессов в системе
Анализ работы системы
Подготовка отчета
Оптимизация ХД для более частых запросов
3.2 Тестовый проект по созданию витрины данных.
Исходя из вышеприведенной методологии определим этапы создания ВД:
1. Определение предметной области для данной организации.
2. Определение цели создания ВД.
3. Определение библиотеки запросов.
4. Определение объектов изучения. Выделение необходимой части из совокупности первичных источников данных
5. Создание модели ВД (звезда).
6. Определение отношений.
7. Модель процесса загрузки.
8. Модель приложения.
9. Определение архитектуры.
10. Построение базы данных.
11. Загрузка данных.
12. Тестирование. Запросы и отчеты.
А теперь выполним эту цепочку для создания ВД.
1. Определение предметной области для данной организации.
Организация представляет собой страховую компанию. Предметная область:
Страховой рынок.
2. Определение цели создания ВД.
Цель создания ВД – получение возможности наблюдать динамику изменения изучаемых параметров во времени, по продуктам и по филиалам. Причем необходима возможность задавания нерегламентированных запросов и получение отчетов в виде удобном пользователю. Получение отчетности по фирме и по филиалам.
3. Определение библиотеки запросов.
Пример необходимых запросов:
1. Как изменялась продажа продукта «Страхование имущества физ. лиц» в Кукморском филиале с 3-го квартала 1998 года по 3-й квартал 1999 года включительно?
2. Как продавался продукт «Семейное страхование жизни» во всех филиалах в 4-м квартале 1999 года.
3. …………..
4. Определение объектов изучения. Выделение необходимой части из совокупности первичных источников данных
В организации выделены следующие объекты для изучения:
- страховая сумма
- сумма поступлений взносов
- страховое поле
- количество договоров
- число застрахованных
- сумма заявленных выплат
- фактически выплаченная сумма
Для тестового проекта выбран один из наиболее важных объектов:
сумма поступлений взносов.
Затем были определены оперативные источники содержащие необходимые данные для проекта.
Исходные данные представляют собой результат работы в программе квартальной отчетности OTCHET. Программа работает под DOS. Данные находятся в таблицах формата *.dbf. Понадобились таблицы:
ATE2.DBF – справочник филиалов с их кодом АТЕ (табл. 8)
( нам понадобятся столбцы
ATE2_2 – код филиала внутри фирмы
ATE2_5 – название филиала )
| ATE2_0 |
ATE2_1 |
ATE2_2 |
ATE2_3 |
ATE2_4 |
ATE2_5 |
ATE2_6 |
ATE2_7 |
| 2 |
1 |
1 |
И |
Агрызский |
Агрызский |
1 |
| 2 |
2 |
2 |
И |
Азнакаевский |
Азнакаевск |
1 |
| 2 |
3 |
3 |
И |
Аксубаевский |
Аксубаевс |
1 |
| 2 |
4 |
4 |
И |
Актанышский |
Актанышс |
1 |
| 2 |
5 |
5 |
И |
Алексеевский |
Алексеевс |
1 |
| 2 |
6 |
6 |
И |
Алькеевский |
Алькеевс |
1 |
Таблица.8 Фрагмент файла ATE2.DBF.
DAT_OTCH.DBF – основная таблица содержащая информацию за 1998, 1999 гг. о суммах поступлении. (табл. 9)
( нам понадобятся столбцы GD - год, KVART - квартал, ATE – код филиала,
NR – номер раздела в справочниках видов страхования
NS – номер строки в справочнике видов страхования
A6 – сумма поступлений)
| GD |
KVART |
ATE |
NR |
NS |
A3 |
A4 |
A5 |
A6 |
A7 |
A8 |
| 1998 |
2 |
64 |
1 |
1,00 |
22 |
0 |
15262,0 |
749,0 |
23,0 |
0,0 |
| 1998 |
2 |
64 |
1 |
2,00 |
13 |
0 |
10262,0 |
649,0 |
16,0 |
0,0 |
| 1998 |
2 |
64 |
1 |
3,00 |
0 |
0 |
0,0 |
0,0 |
0,0 |
0,0 |
| 1998 |
2 |
64 |
1 |
4,00 |
0 |
0 |
0,0 |
0,0 |
0,0 |
0,0 |
Таблица. 9 Фрагмент файла DAT_OTCH.DBF
| A9 |
A10 |
A11 |
A12 |
| 0 |
7386,0 |
2 |
542,0 |
| 0 |
70086,0 |
2 |
582,0 |
| 0 |
0,0 |
0 |
0,0 |
| 0 |
0,0 |
0 |
0,0 |
Таблица. 9 (окончание)
BOKOV1.DBF, BOKOV2.DBF, BOKOV3.DBF – справочники видов страхования с 1 по 3 раздел соответственно.
( нам понадобятся столбцы VID_STR – название вида страховния
NR – номер раздела
NS – номер строки )
| VID_STR |
NS |
NR |
LOGIK |
B3 |
B4 |
B5 |
B6 |
B7 |
B8 |
B9 |
| 1. Д/с юридических лиц 1 |
1,00 |
1 |
ИСТИНА |
X |
X |
| Имущественное: 2 |
2,00 |
1 |
ИСТИНА |
X |
X |
| имущества фермерских |
2,00 |
1 |
ЛОЖЬ |
| хозяйств и арендаторов 3 |
3,00 |
1 |
ИСТИНА |
X |
X |
| в т.ч. посевов (21) 4 |
4,00 |
1 |
ИСТИНА |
X |
X |
| животных (17) 5 |
5,00 |
1 |
ИСТИНА |
| транспортных средств(9,10) 6 |
6,00 |
1 |
ИСТИНА |
| прочего (15) 7 |
7,00 |
1 |
ИСТИНА |
Таблица. 10 Фрагментфайла BOKOV1.DBF
| VID_STR |
NS |
NR |
LOGIK |
B3 |
B4 |
B5 |
B6 |
B7 |
B8 |
B9 |
B10 |
B11 |
B12 |
| Страхование жизни - всего 1 |
1,00 |
2 |
ИСТИНА |
| в том числе: |
1,00 |
2 |
ЛОЖЬ |
| смешанное 2 |
2,00 |
2 |
ИСТИНА |
X |
X |
X |
| детей 3 |
3,00 |
2 |
ИСТИНА |
X |
X |
X |
| к бракосочетанию 4 |
4,00 |
2 |
ИСТИНА |
X |
X |
X |
| воспитанников дет. учрежд. 5 |
5,00 |
2 |
ИСТИНА |
X |
| пожизненное 6 |
6,00 |
2 |
ИСТИНА |
X |
X |
X |
| семейное 7 |
7,00 |
2 |
ИСТИНА |
| N23 за счёт физ. лиц 8 |
8,00 |
2 |
ИСТИНА |
Таблица.11 Фрагмент файла BOKOV2.DBF
| VID_STR |
NS |
NR |
LOGIK |
B3 |
B4 |
B5 |
B6 |
B7 |
B8 |
B9 |
B10 |
B11 |
B12 |
| Обязательное страхование 1 |
1,00 |
3 |
ИСТИНА |
X |
X |
| имущества граждан |
1,00 |
3 |
ЛОЖЬ |
| в том числе: |
1,00 |
3 |
ЛОЖЬ |
| строений 2 |
2,00 |
3 |
ИСТИНА |
X |
X |
X |
X |
| животных 3 |
3,00 |
3 |
ИСТИНА |
X |
X |
X |
X |
| Обязательное страхование |
3,00 |
3 |
ЛОЖЬ |
| пассажиров 4 |
4,00 |
3 |
ИСТИНА |
| Прочие виды обязат. страх-ния 5 |
5,00 |
3 |
ИСТИНА |
Таблица.12 Фрагмент файла BOKOV3.DBF
5. Создание модели ВД.
Выбираем многомерную модель данных.
Определяем меры и измерения.
Измерения: Продукт, Регион, Время
.
Иерархии:
Продукт
Регион
Время
| | |
Группа Регион Год
| | |
Категория Филиал
Квартал
| | |
Продукт
Агент Месяц
Меры:
- страховая сумма
- сумма поступлений взносов
- страховое поле
- количество договоров
- число застрахованных
- сумма заявленных выплат
- фактически выплаченная сумма
Жирным шрифтом выделено, то что будет присутствовать в тестовом проекте. Мы имеем одну меру и три измерения.
Строим модель «звезду». Модель «снежинка» здесь не подходит, так как необходимость в ней бывает тогда, когда нужно денормализовать одну или несколько таблиц измерений. В нашем случае нечего денормализовывать.
В модели данных будут присутствовать таблица фактов и три таблицы измерений: времени, вида страхового продукта, название филиала.
В таблице фактов будет 4 поля – 3 внешних ключа ATE_ID, VID_ID, TIME_ID и поле VZNOS – сумма поступлений взносов.
В двух таблицах измерений будут справочники филиалов и видов продуктов (идентификатор + название).
Таблица измерения «Время» будет иметь 3 поля TIME_ID, YEAR, QUARTER.
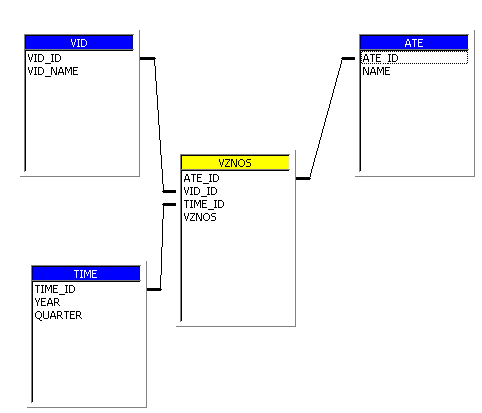
Рисунок. 6 Схема «звезда»
6. Определение отношений.
Соединяем таблицы измерений отношениями «один ко многим» с таблицей фактов. Получили схему «звезда» (рис. )
7. Модель процесса загрузки.
Мы переносим следующие данные:
КодАТЕ ATE2.ATE2_2 - ATE.ATE_ID
Название филиала ATE2.ATE2_5 -ATE.NAME
Вид продукта BOKOV1.VID_STR - VID.VID_NAME
BOKOV2.VID_STR - VID.VID_NAME
BOKOV3.VID_STR - VID.VID_NAME
Сумма поступлений DAT_OTCH.A6 -VZNOS.VZNOS
Таблицу TIME заполняем значениями года: 1998,1999. И соответсвенно значениями квартала от 1 до 4.
8. Модель приложения.
Информация пользователю будет представляться в виде таблиц, графиков или диаграмм. Например (табл. ):
| Взносы |
Филиал |
| Год |
Вид страхования |
Кукморский |
Общий итог * |
| 1999 |
Добровольное страхование имущества физ. лиц |
382778 |
7245476,5 |
| Добровольное страхование имущества юр. лиц |
439245 |
8615743,6 |
| Добровольное страхование ответственности юр. лиц |
401766 |
7367026,9 |
| Обязательное страхование имущества физ. лиц |
58968 |
9172973,7 |
| Обязательное страхование пассажиров |
141150 |
9345879 |
| Прочие виды обязательного страхования |
74073 |
9279667 |
| Страхование жизни: по правилам №23 |
131609,5 |
8225452,7 |
| Страхование жизни: пожизненное |
113449,5 |
7448453,5 |
| Страхование жизни: семейное |
109720,5 |
8032250,7 |
| Страхование жизни: смешанное |
107079,5 |
9966974,3 |
| 1999 Всего * |
1959839 |
84699897,9 |
| Общий итог * |
3953311 |
160045472,8 |
Таблица. 13 Табличный способ представления информации
9. Определение архитектуры.
В связи с тем, что у проекта очень ограничен бюджет, то в качестве
платформы было выбрано решение фирмы Microsoft на базе Wintel:
- Windows 2000 Server;
- Microsoft SQL Server 7.0 Enterprise Edition;
- Microsoft OLAP Services;
- MSExcel’2000 из русифицированного пакета MSOffice’2000.
При невысокой цене это решение дало нам всю необходимую функциональность. А знакомство пользователей с пакетом МSOffice’97 сводит их обучение к минимуму.
10. Построение базы данных.
Используя SQLServerEnterpriseManager создаем базу данных “TASFIR”, используя мастер. Указываем размер базы 50 Mb и размер приращения 5 Mb.
11. Загрузка данных.
Используя DataTransformationServices (DTS) – сервисы преобразования данных, загрузим данные в базу данных TASFIR согласно модели процесса загрузки. DTS работает в виде мастера импорта. Здесь необходимо указать в качестве источника (Source) – DbaseIV и указать в пути каталог нахождения исходных таблиц. В качестве приемника будет выступать MicrosoftOLEDBProviderforSQLServer, необходимо указать название нашей БД TASFIR. Далее выбираем те таблицы, которые участвуют в переносе и обозначаем условия для переноса каждой таблицы и каждого поля. И производим перенос данных.
Запускаем OLAPManager для создания OLAP-куба. Создаем новую базу данных. Затем создаем новый куб с помощью мастера.
- создаем новый источник данных. Выбираем базу данных TASFIR, а в ней таблицу VZNOS.
- выбираем в качестве меры поле VZNOS базы данных VZNOS
- далее создаем новые измерения time, vid, ate. Причем создавая измерение time необходимо соблюсти иерархию и поставить год выше квартала
- далее называем куб TASFIR, здесь можно просмотреть как можно работать с кубом на тестовых данных
- открывается редактор куба, здесь можно отредактировать отношения между таблицами, удалить и добавить новые
- далее закрываем редактор и записываем куб
- получаем приглашение провести агрегирование данных тремя различными способами MOLAP, HOLAP, ROLAP. Выбираем первое, так как у нас маленькая база
- в следующем окне нажимаем старт и получаем график зависимости ускорения ответа на запросы (вследствие предварительного просчета агрегатов и их хранения) от того сколько дисковой памяти будет выделено под эти агрегаты.
- Далее запускаем процесс создания.
12. Тестирование. Запросы и отчеты.
В качестве клиентской части выступает MSExcel’2000 из русифицированного пакета MSOffice’2000.
Заходим Данные -Внешние данные - Создать запрос.
Далее отвечаем готово и расставляем наши меры и измерения по таблице. Меру в середину, а измерения в любом порядке. ВСЕ инструмент для тестового анализа готов.
Заключение.
1. Был проведен анализ организации хранилищ данных
2. Проведена оценка требуемого объема памяти и быстродействия в
аналитических системах в зависимости от организации данных.
3. Была разработана технология проектирования Хранилищ Данных
4. Разработан алгоритм создания Хранилища Данных
5. Апробация проведена в ведущей организации
6. Тестовый проект выполненнвсреде Windows 2000, на базе SQL Server 7.0 и MS Office 2000.
Библиографический список.
1. Inmon W.H. Building the Data Warehouse // Wellesley, MA.: QED Publishing Group, 1992
2. Codd E.F., Codd S.B., Salley C.T., E.F.Codd & Associates. Providing OLAP
(On-Line Analytical Processing) to User-Analysts: An IT Mandate. - 1993.
3. DePompa B. Основные тенденции развития информационных хранилищ
//COMPUTERWORLD MOSCOW. – 1996. - №16
4. DePompa B. Хотите получить прибыль - разберитесь со своими данными.
// COMPUTERWORLD MOSCOW. – 1997. - №13
5. MicrosoftCorporation Компьютерные сети. Учебный курс. – М. Русская
редакция,1997. – 696 с.
6. Raden N.Моделирование информационных хранилищ //
COMPUTERWORLD MOSCOW. – 1996. - №16
7. Артемов Д., Погульский Г., Альперович М. MicrosoftSQLServer 7.0 для профессионалов. – М.: Русская редакция, 1999. – 576 с.
8. Баронов В.В. Автоматизация управления предприятиям. – М.: ИНФРА-М, 2000. – 239 с.
9. Бритов П.А., Липчинский Е.А. Практика построения Хранилищ Данных:
Система SAS //СУБД. - 1998. - №4-5
10. Буров К. Обнаружение знаний в хранилищах данных // Открытые
Системы. - 1999. - №5-6
11. Ганьон Габриэль Хранилища данных: краткий обзор // PCMagazine/RE. –
1999. - №10
12. ГарбусДж., ПаскузиД., ЧангЭ. Database Design on SQL Server 7. Сертификационный экзамен – экстерном (экзамен – 70-029). – СПб.: Питер, 2000. – 560 с.
13. Дейт К. Дж. Введение в системы баз данных. – К : Диалектика, 1998. – 784 с.
14. Джулия Борт Витринам данных не мешает похудеть // Директору
информационной службы. - 1999
15. Зельцер A. Информационные хранилища в сетях предприятий
//COMPUTERWORLD MOSCOW. – 1995. - №12
16. Иванов П. Индивидуальный маркетинг на плечах информационных
хранилищ // СomputerWeekly. – 1998. - №26-27
17. Калянов Г.Н. Консалтинг при автоматизации предприятия. – М.: СИНТЕГ, 1997. – 316 с.
18. Кречетов Н. Информационные хранилища: обзор технологий и
продуктов //COMPUTERWORLD MOSCOW. – 1996. - №16
19. Кречетов Н. Информационные хранилища //COMPUTERWORLD
MOSCOW. – 1995. - №12
20. Кристин К. Корпоративная отчетность. Серверная архитектура для
распределенного доступа к информации //Открытые Системы - 1999 - №1.
21. Кузин Ф.А. Магистерская диссертация. Методика написания, правила оформления и процедура защиты.Практическое пособие для студентов-магистрантов. – М.: Ось-98, 1997. – 304 с.
22. Липаев В.В. Системное проектирование сложных программных средств для информационных систем. – М.: СИНТЕГ, 1999. – 224 с.
23. Львов В. Создание систем поддержки принятия решений на основе
хранилищ данных // СУБД. – 1997. - №3
24. Маклаков С.В. CASE-средства разработки информационных систем: BPwin, ERwin. – М.: ДИАЛОГ-МИФИ, 2000. – 256 с.
25. Наталья Д. Устройство и назначение хранилищ данных // Открытые
Системы. - 1998. - №4-5
26. Найгель П. Истоки сегодняшних продуктов OLAP.(перевод Абушаева Ш)
// THEOLAPREPORT. – 1999
27. Найгель П. Как не купить OLAP продукт. (переводАбушаеваШ.) // THE
OLAP REPORT. – 1999
28. Пржиялковский В. Data Warehouse — почувствуйте себя принимающим
решение //Директору информационной службы. – 2000
29. Рекорд Сара. Строя рентабельное хранилище данных // Informix
Magazine(русское издание). – 1998
30. Роджерс Джефри Проверка достоверности данных при репликации //
WINDOWS 2000 MAGAZINE. - 1999. – №3
31. Саймон А.Р. Стратегические технологии баз данных: менеджмент на 2000 год. – М.: Финансы и статистика, 1999. – 479 с.
32. Сахаров А.А. Концепции построения и реализации информационных
систем, ориентированных на анализ данных // СУБД. – 1996. - №4
33. Сахаров А.А. Принципы проектирования и использования многомерных
баз данных (на примере Oracle Express Server) // СУБД. – 1996. - №3
34. Сонькин А. Построение хранилища данных средствами Informix //
InformixMagazineRussian Edition. – 1998. - Апрель
35. Тао Ай Лей Три ареала хранилищ данных //COMPUTERWORLD
РОССИЯ. – 1999. - №24
36. Шапиро В.Д. Projectmanagement/Управление проектами: толковый англо-русский словарь-справочник. – М.: Высшая школа, 2000. – 379 с.
37. Щавелёв Л.В. Способы аналитической обработки данных для поддержки
принятия решений //СУБД. - 1998. - №4-5
Приложение 1
Отчетные формы и диаграммы полученные
в результате тестирования системы
|