Московский Государственный Технический Университет
«МАМИ»
Факультет Экономический
Кафедра Информационные технологии в экономике
КУРСОВАЯ РАБОТА
По дисциплине Эконометрика
Студента Николаевой Елены Александровны
(фамилия, имя, отчество)
На тему: Применение регрессионного анализа в эконометрике
Автор работы:
Николаева Е.А.
___________________
Научный руководитель:
к. э. н., Квитченко С.А.
___________________
Дата сдачи:
«____»______________200__г.
Дата защиты:
«____»_____________200__г.
Оценка: __________________
Москва 2009
Оглавление
Введение……………………………………………………………………………...3
1. Глава 1. Теоретические и методологические основы применения регрессионного анализа в эконометрике
1.1. Основные положения регрессионного анализа………………………….5
1.2. Оценка параметров парной регрессионной модели…………………….8
1.3. Интервальная оценка функции регрессии и ее параметров…………...15
1.4. Оценка значимости уравнения регрессии и особенности
применения коэффициента детерминации………………….…………16
Выводы……………………………………………………………………………...20
2. Глава 2. Практическое применение регрессионного анализа в эконометрике
2.1. Задача 1…………………………………………………………………...22
2.2. Задача 2…………………………………………………………………...23
Выводы……………………………………………………………………………...26
Заключение………………………………………………………………………….27
Библиографический список………………………………………………………..29
Приложение
Введение
Актуальность выбранной темы определяется тем, что в эконометрике широко используются методы статистики. Во многих практических задачах прогнозирования, изучая различного рода связи в экономических, производственных системах, необходимо на основании экспериментальных данных выразить зависимую переменную в виде некоторой математической функции от независимых переменных – регрессоров, то есть построить регрессионную модель. Регрессионный анализ позволяет:
· производить расчет регрессионных моделей путем определения значений параметров – постоянных коэффициентов при независимых переменных – регрессорах, которые часто называют факторами;
· проверить гипотезу об адекватности модели имеющимся наблюдениям;
· использовать модель для прогнозирования значений зависимой переменной при новых или ненаблюдаемых значениях независимых переменных.
Целью курсовой работы явилось исследование регрессионного анализа и применение его в эконометрике. Для достижения поставленной цели были решены следующие задачи:
· изучение основных положений регрессионного анализа
· рассмотрение оценки параметров парной регрессионной модели
· изучение интервальной оценки функции регрессии и ее параметров
· исследование оценки значимости уравнения регрессии и особенностей применения коэффициента детерминации
· рассмотрение практических задач
Предметом исследования явились математико-статистические методы в экономических исследованиях.
Объект исследования курсовой работы – практическая задача по применению регрессионного анализа в эконометрике.
Информационную базу составили труды отечественных ученых-экономистов в области эконометрических исследований, публикации, Интернет источники и личные наблюдения автора.
Для написания курсовой работы использовались методы статистической обработки информации, методы аналитических процедур и возможности математических расчетов для обоснования экономических исследований.
3.
Глава 1. Теоретические и методологические основы применения регрессионного анализа в эконометрике
1.1.
Основные положения регрессионного анализа
Ставя цель дать количественное описание взаимосвязи между экономическими переменными, эконометрика прежде всего связана с методами регрессии и корреляции.
Регрессия [regression] — это зависимость среднего значения какой-либо случайной величины от некоторой другой величины или нескольких величин[1]
. Следовательно, при регрессионной связи одному и тому же значению x
величины X
(в отличие от функциональной связи) могут соответствовать разные случайные значения величины Y.
Распределение этих значений называется условным распределением Y
при данном X = x.
Уравнение, связывающее эти величины, называется уравнением регрессии, а соответствующий график — линией регрессии величины Y
по X
.
К задачам регрессионного анализа относятся[2]
: • установление формы зависимости между переменными; • оценка модельной функции (модельного уравнения) регрессии; • оценка неизвестных значений (прогноз значений) зависимой переменной. В регрессионном анализе рассматривается односторонняя зависимость переменной Y (ее еще называют функцией отклика, результативным признаком, предсказываемой переменной) от одной или нескольких независимых переменных X (называемых также объясняющими или предсказывающими переменными, факторными признаками).В зависимости от количества факторов, включенных в уравнение регрессии, принято различать простую (парную) и множественную регрессии.Простая регрессия представляет собой регрессию между двумя переменными y и x, то есть модель вида: y = ƒ(x), где:y – зависимая переменная (результативный признак);x – независимая, или объясняющая, переменная (признак-фактор).Множественная регрессия соответственно представляет собой регрессию результативного признака с двумя и большим числом факторов, то есть модель вида[3]
:y = ƒ(x1
, x2
, …, xk
).В данной работе рассмотрена модель парной регрессии. Прежде всего из всего круга факторов, влияющих на результативный признак, необходимо выделить наиболее существенно влияющие факторы. Парная регрессия достаточна, если имеется доминирующий фактор, который и используется объединяющей переменной.Уравнение простой регрессии характеризует связь между двумя переменными, которая проявляется как некоторая закономерность лишь в среднем в целом по совокупности наблюдений.В уравнении регрессии корреляционная по сути связь признаков представляется в виде функциональной связи, выраженной соответствующей математической функцией. Практически в каждом отдельном случае величина y складывается из двух слагаемых:yj
= ŷxj
+ εj
, где:yj
– фактическое значение результативного признака;ŷxj
– теоретическое значение результативного признака, найденное исходя из соответствующей математической функции y и x, то есть из уравнения регрессии;εj
– случайная величина, характеризующая отклонения реального значения результативного признака от теоретического, найденного по уравнению регрессии.Случайная величина ε (возмущение) включает влияние не учтенных в модели факторов, случайных ошибок и особенностей измерения. Ее присутствие в модели обусловлено тремя источниками: спецификацией модели, выборочным характером исходных данных, особенностями измерения переменных.От правильно выбранной спецификации модели зависит величина случайных ошибок: они тем меньше, чем в больше мере теоретические значения результативного признака ŷx
подходят у фактическим данным y.В парной регрессии выбор вида математической функции ŷx
= ƒ(x) может быть осуществлен тремя методами[4]
: графическим, аналитическим (исходя из теории изучаемой взаимосвязи), экспериментальным.При изучении зависимости между двумя признаками графический метод подбора вида уравнения регрессии достаточно нагляден. Он основан на поле корреляции. Основные типы кривых, используемые при количественной оценке связей: · ŷx
=а+b*x;· ŷx
=а+b/x;· ŷx
=а*xb
;· ŷx
=а+b*x+c*x2
;· ŷx
=а+b*x+c*x2
+d*x3
;· ŷx
=а*bx
.Если между экономическими явлениями существуют нелинейные соотношения[5]
, то они выражаются с помощью соответствующих нелинейных функций: например, равносторонней гиперболы y=a+b/x+ε, параболы второй степени y=a+b*x+c*x2
+ ε и другие. Различают два класса нелинейных регрессий:· Регрессии, нелинейные относительно включенных в анализ объясняющих переменных, но линейные по оцениваемым параметрам (примером такой регрессии могут служить: полиномы разных степеней – y=a+b*x+c*x2
+ ε, y= a+b*x+c*x2
+ d*x3
+ε);· Регрессии, нелинейные по оцениваемым параметрам (к ним относятся: степенная – y=a*xb
*ε; показательная – y=a*bx
*ε; экспоненциальная – y=ea
+
bx
*ε).1.2.
Оценка параметров парной регрессионной модели
Линейная регрессия находит широкое применение в эконометрике в виде четкой экономической интерпретации ее параметров.Линейная регрессия сводится к нахождению уравнения вида:ŷx
=a+b*x или y=a+b*x+ε.Уравнение вида ŷx
=a+b*x позволяет по заданным значениям фактора x иметь теоретические значения результативного признака, подставляя в него фактические значения фактора x.Построение линейной регрессии сводится к оценке ее параметров – а и b[6]
. Оценки параметров линейной регрессии могут быть найдены разными методами. Можно обратиться к полю корреляции и, выбрав на графике две точки, провести через них прямую линию. Далее по графику можно определить значения параметров. Параметр а определим как точку пересечения линии регрессии с осью oy, а параметр b оценим, исходя из угла наклона линии регрессии, как dy/dx, где dy – приращение результата у, а dx – приращение фактора х.Классический подход к оцениванию параметров линейной регрессии основан на методе наименьших квадратов (МНК)[7]
.МНК позволяет получить такие оценки параметров а и b, при которых сумма квадратов отклонений фактических значений результативного признака (у) от расчетных (теоретических) ŷx
минимальна: ∑(уi
- ŷxi
)2
→min. Иными словами, из всего множества линий линия регрессии на графике выбирается так, чтобы сумма квадратов расстояний по вертикали между точками и этой линией была бы минимальной.Чтобы найти минимум функции, надо вычислить частные производные по каждому из параметров а и b и приравнять их к нулю.Обозначим ∑εi
2
через S, тогда:S=∑(уi
- ŷxi
)2
=∑(y-a-b*x)2
dS/da=-2∑y+2*n*a+2*b∑x=0 (1.1)dS/db=-2∑y*x+2 *a∑x +2*b∑x2
=0 Преобразуя формулу (1.1), получим следующую систему нормальных уравнений для оценки параметров а и b:n*a+b∑x=∑ya ∑x+ b∑x2=
∑x*y (1.2)Решая систему нормальных уравнений (1.2) либо методом последовательного исключения переменных, либо методом определителей, найдем исходные оценки параметров а и b. Можно воспользоваться следующими готовыми формулами: a=y-b*x (1.3)Формула (1.3) получена из первого уравнения системы (1.2), если все его члены разделить не n.b=cov(x,y)/σx
2
, гдеcov(x,y) – ковариация признаков;σx
2
– дисперсия признака х.Ввиду того, что cov(x,y)=yx-y*x, а σx
2
=x2
-x2
, получим следующую формулу расчета оценки параметра b:b=yx-y*x/ x2
-x2
Параметр b называется коэффициентом регрессии. Его величина показывает среднее изменение результата с изменением фактора на одну единицу.Формально а – значение у при х=0. Если признак-фактор х не имеет и не может иметь нулевого значения, то вышеуказанная трактовка свободного члена а не имеет смысла. Параметр а может не иметь экономического содержания. Попытки экономически интерпретировать параметр а могут привести к абсурду, особенно при а<0.Интерпретировать можно лишь знак при параметре а. если а>0, то относительное изменение результата происходит медленнее фактора. Иными словами, вариация результата меньше вариации фактора – коэффициент вариации по фактору х выше коэффициента вариации для результата у: Vx>Vy.Нелинейная регрессия по включенным переменным не представляет никакой сложности в оценке ее параметров[8]
. Она определяется, как и в линейной регрессии, МНК, обо эти функции линейны по параметрам. Так, в параболе второй степени у=а0
+а1
*х+а2
*х2
+ε, заменяя переменные х=х1
, х2
=х2
, получим двухфакторное уравнение линейной регрессии: у=а0
+а1
*х1
+а2
*х2
+ε, для оценки параметров которого используется МНК.Следовательно для полинома третьего порядка у=а0
+а1
*х+а2
*х2
+а3
*х3
+ε, при замене х=х1
,х2
=х2
, х3
=х3
получим трехфакторную модель линейной регрессии: у=а0
+а1
*х1
+а2
*х2
+а3
*х3
+ε.А для полинома k-го порядка у=а0
+а1
*х+а2
*х2
+…+аk
*хk
+ε получим модель множественной регрессии с k объясняющими переменными: у=а0
+а1
*х1
+а2
*х2
+…+аk
*хk
+ε/Следовательно, полином любого порядка сводится к линейной регрессии с ее методами оценивания параметров и проверки гипотез. Как показывает опыт большинства исследователей, среди нелинейной полиномиальной регрессии чаще всего используется парабола второй степени; в отдельных случаях – полином третьего порядка. Ограничения в использовании полиномов более высоких степеней связаны с требованием однородности исследуемой совокупности: чем выше порядок полинома, тем больше изгибов имеет кривая и соответственно менее однородна совокупность по результативному признаку.Парабола второй степени целесообразна к применению, если для определенного интервала значений фактора меняется характер связи рассматриваемых признаков: прямая связь меняется на обратную или обратная на прямую. В этом случае определяется значение фактора, при котором достигается максимальное (минимальное) значение результативного признака: приравнивается к нулю первая производная параболы второй степени: ŷx
=a+b*x+c*х2
, то есть b+2*c*x=0 и x=-b/2*c.Если же исходные данные не обнаруживают изменения направленности связи, то параметры параболы второго порядка становятся трудно интерпретируемыми, а форма связи часто заменяется другими нелинейными моделями.Ввиду симметричности кривой парабола второй степени далеко не всегда пригодна в конкретных исследованиях. Чаще всего исследователь имеет дело лишь с отдельными сегментами параболы, а не с полной параболической формой. Кроме того, параметры параболической связи не всегда могут быть логически истолкованы. Поэтому если график зависимости не демонстрирует четко выраженной параболы второго порядка (нет смены направленности связи признаков), то она может быть заменена другой нелинейной функцией, например степенной.Среди класса нелинейных функций, параметры которых без особых затруднений оцениваются МНК, следует назвать хорошо известную в эконометрике равностороннюю гиперболу: ŷx
=a+b/x. Она может быть использована не только для характеристики связи удельных расходов сырья, топлива, материалов с объемом выпускаемой продукции, времени обращения товаров от величины товарооборота на микроуровне, но и на макроуровне. Классическим ее примером является кривая Филипса, характеризующая нелинейное соотношение между нормой безработицы х и процентом прироста заработной платы у: y=a+b/x+ε.Для равносторонней гиперболы вида y=a+b/x+ε, заменив 1/х на z, получим линейное уравнение регрессии y=a+b*z+ε, оценка параметров которого может быть дана МНК. Система нормальных уравнений составит:∑у=n*a+b*∑1/x,∑y/x=a*∑1/x+b*∑1/x2
При b>0 имеем обратную зависимость, которая при х→∞ характеризуется нижней асимптотой, то есть минимальным предельным значением у, оценкой которого служит параметр а.При b<0 имеем медленно повышающуюся функцию с верхней асимптотой при х→∞, то есть с максимальным предельным уровнем у, оценку которого в уравнении ŷx
=a+b/x дает параметр а.Примером может служить взаимосвязь доли расходов на товары длительного пользования и общих сумм расходов (или доходов). Математическое описание подобного рода взаимосвязей получило название кривых Энгеля.Уоркинг и Лизер для описания кривой Энгеля использовали полулогарифмическую кривую у=а+b*lnx+ε/Заменив lnx на z, опять получим линейное уравнение: y=a+b*z+ε. Данная функция, как и предыдущая, линейна по параметрам и нелинейна по объясняющей переменной х. оценка параметров а и b может быть найдена МНК. Система нормальных уравнений при этом окажется следующей:∑у=n*a+b*∑lnx,∑y*lnx=a*∑lnx+b*∑(lnx)2
Возможны и иные модели, нелинейные по объясняющим переменным. Например, у=а+b*√x+ε. Соответственно система нормальных уравнений для оценки параметров составит:∑у=n*a+b*∑√x,∑y*√x=a*∑√x+b*∑xУравнение с квадратными корнями использовались в исследованиях урожайности[9]
, трудоемкости сельскохозяйственного производства. В работе Н.Дрейнера и Г.Смита[10]
справедливо отмечено, что если нет каких-либо теоретических обоснований в использовании данного вида кривых, то основная цель подобных преобразований состоит в том, чтобы для преобразованных переменных получить более простую модель регрессии, чем для исходных данных.Иначе обстоит дело с регрессией, нелинейной по оцениваемым параметрам[11]
. Данный класс нелинейных моделей подразделяется на два типа: · Нелинейные модели внутренне линейные. Такая модель с помощью соответствующих преобразований может быть приведена к линейному виду;· Нелинейные модели внутренне не линейные не могут быть сведены к линейной функцииНапример, в экономических исследованиях при изучении эластичности спроса от цен широко используется степенная функция: у=а*хb
*ε, гдеу – спрашиваемое количество;х – цена;ε – случайная ошибка.Данная модель не линейна относительно оцениваемых параметров, ибо включает параметры а и b неаддитивно. Однако ее можно считать внутренне линейной, так как логарифмирование данного уравнения по основанию е приводит его к линейному виду: lny=lna+b*lnx+lnε.Соответственно оценки параметров а и b могут быть найдены МНК. В рассматриваемой степенной функции предполагается, что случайная ошибка ε мультипликативно связана с объясняющей переменной х.Если же модель представить в виде у=а*xb
+ε, то она становится внутренне не линейной, так как ее невозможно превратить в линейный вид.В специальных исследованиях по регрессионному анализу часто к нелинейным относят модели, только внутренне нелинейные по оцениваемым параметра, а все другие модели, которые внешне нелинейны, но путем преобразований параметров могут быть приведены к линейному виду, относятся к классу линейных моделей. Если модель внутренне нелинейна по параметрам, то для оценки параметров используются итеративные процедуры, успешность которых зависит от вида уравнений и особенностей применяемого итеративного подхода. Среди нелинейных функций, которые могут быть приведены к линейному виду, в эконометрических исследованиях очень широко используется степенная функция у=а*xb
*ε. Связанно это с тем, что параметр b в ней имеет четкое экономическое толкование, те есть он являеся коэффицентом эластичности. Это значит, что величина коэффициента b показывает, на сколько процентов изменился в среднем результат, если фактор изменился на 1%. О правомерности подобного истолкования параметра b для степенной функции ŷх
=а*хb
можно судить, если рассмотреть формулу расчета коэффициента эластичностиЭ=ƒ`(x)x/y, где ƒ`(x) – первая производная, характеризующая соотношение приростов результата и фактора для соответствующей формы связи.В силу того, что коэффициент эластичности для линейной функции не является величиной постоянной, а зависит от соответствующего значения х, то обычно рассчитывается средний показатель эластичности по формуле:Э=b*x/y.Для оценки параметров степенной функции у=а*xb
*ε применяется МНК к линеаризированному уравнению lny=lna+b*lnx+lnε, то есть решается система нормальных уравнений:∑lnу=n*lna+b*∑lnx,∑lny*lnx=lna*∑lnx+b*∑(lnx)2
Параметр b определяется непосредственно из системы, а параметр а – косвенным путем после потенцирования величины lna.Поскольку коэффициенты эластичности представляют экономический интерес, а виды моделей не ограничиваются только степенной функцией, то существуют формулы расчета коэффициентов эластичности для наиболее распространенных типов уравнений регрессии, приведенные в приложении 1.Несмотря на широкое использование в эконометрике коэффициентов эластичности, возможны случаи, когда их расчет экономического смысла не имеет. Это происходит тогда, когда для рассматриваемых признаков бессмысленно определение изменения значений в процентах.1.3.
Интервальная оценка функции регрессии и ее параметров
В прогнозных расчетах по уравнению регрессии определяется предсказываемое (ур
) значение как точечный прогноз ŷx
при хр
=хк
, то есть путем подстановки в уравнение регрессии ŷx
=a+b*x соответствующего значения х[12]
. однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ŷx
, то есть mŷ
x
, и соответственно интервальной оценкой прогнозного значения (у*
)ŷx
-mŷ
x
≤у*
≤ŷx
+mŷ
x
что бы понять, как строится формула для определения величины стандартной ошибки ŷx
, обратимся к уравнению линейной регрессии: ŷx
=a+b*x. Подставим в это уравнение выражение параметра а: a=y-b*x, тогда уравнение регрессии примет вид: ŷx
= y-b*x+b*x=у+ b(x-x).Отсюда вытекает, что стандартная ошибка mŷ
x
зависит от ошибки у и ошибки коэффициента регрессии b, то есть:mŷ
x
2
=my
2
+mb
2
(x-x)2
Из теории выборки известно, что my
2
= σ2
/n. Используя в качестве оценки σ2
остаточную дисперсию на одну степень свободы S2
, получим формулу расчета ошибки среднего значения переменной у:my
2
= S2
/n.Считая, что прогнозное значение фактора хз
=хк
, получим следующую формулу расчета стандартной ошибки предсказываемого по линии регрессии значения, то есть mŷ
x
:mŷx
2
= S2
/n+ S2
/∑(x-x)2
*(хк
-х)2
= S2
*(1/n+((xk
-x)2
/(∑(x-x)2
)))Рассмотренная формула стандартной ошибки предсказываемого среднего значения у при заданном значении xk
характеризует ошибку положения линии регрессии. Величина стандартной ошибки mŷ
x
, как видно из формулы, достигает минимума при хк
=х, и возрастает по мере того, как «удаляется» от х в любом направлении. Иными словами, чем больше разность между хк
и х, тем больше ошибка mŷ
x
с которой предсказывается среднее значение у для заданного значения хк
. Можно ожидать наилучшие результаты прогноза, если признак-фактор х находится в центре области наблюдений х и нельзя ожидать хороших результатов прогноза при удалении хк
от х. Если же значение хк
оказывается за пределами наблюдаемых значений х, используемых при построении линейной регрессии, то результаты прогноза ухудшаются в зависимости от того, насколько хк
отклоняется от области наблюдаемых значений фактора х.Фактические значения у варьируются около среднего значения ŷx
. Индивидуальные значения у могут отклоняться от ŷx
на величину случайной ошибки ε, дисперсия которой оценивается как остаточная дисперсия на одну степень свободы S2
. Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку mŷ
x
, но и случайную ошибку S.1.4.
Оценка значимости уравнения регрессии и особенности применения коэффициента детерминации
После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров[13]
.Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. При этом выдвигается нулевая гипотеза, коэффициент регрессии равен нулю, то есть b=0, и, следовательно, фактор х не оказывает влияния на результат у. Непосредственному расчету F-критерия предшествует анализ дисперсии. Центральное место в нем занимает разложение общей суммы квадратов отклонений переменной у от среднего значения у на две части – «объясненную» и «необъясненную» (приложение 2). Общая сумма квадратов отклонений индивидуальных значений результативного признака у от среднего значения у вызвана влиянием множества причин. Условно всю совокупность причин можно разделить на две группы:· изучаемый фактор х· прочие факторыЕсли фактор не оказывает влияния на результат, то линия регрессии на графике параллельна оси охи у = ŷ. Тогда вся дисперсия результативного признака обусловлена воздействием прочих факторов и общая сумма квадратов отклонений совпадает с остаточной. Если же прочие факторы не влияют на результат, то у связан с х функционально и остаточная сумма квадратов равна нулю. В этом случае сумма квадратов отклонений, объясненная регрессией, совпадает с общей суммой квадратов.Поскольку не все точки поля корреляции лежат на линии регрессии, то всегда имеет место их разброс как обусловленный влиянием фактора х, то есть регрессией у по х, так и вызванный действием прочих величин (необъясненная вариация). Пригодность линии регрессии для прогноза зависит от того, какая часть общей вариации признака у приходится на объясненную вариацию. Очевидно, что если сумма квадратов отклонений, обусловленная регрессией, будет больше остаточной суммы квадратов, то уравнение регрессии статистически значимо и фактор х оказывает существенное влияние на результат у. Это равносильно тому, что коэффициент детерминации r2
xy
будет приближаться к единице.Любая сумма квадратов отклонений связана с числом степеней свободы (df – degreesoffreedom), то есть с числом свободы независимого варьирования признака. Число степеней свободы связано с числом единиц совокупности n и с числом определяемых по ней констант. Применительно к исследуемой проблеме число степеней свободы должно показать, сколько независимых отклонений из n возможных [(y1
-y), (y2
-y),…,(yn
-y)] требуется для образования данной суммы квадратов. Так, для общей суммы квадратов ∑(y-y)2
требуется (n-1) независимых отклонений.При расчете объясненной или факторной суммы квадратов ∑(ŷx
-y)2
используются теоретические (расчетные) значения результативного признака ŷx
, найденные по линии регрессии: ŷx
=а+b*x.В линейной регрессии сумма квадратов отклонений, обусловленных линейной регрессией, составит: ∑(ŷx
-y)2
=b2
*∑(x–x)2
. Поскольку при заданном объеме наблюдений по х и у факторная сумма квадратов при линейной регрессии зависит только от одной константы коэффициента регрессии b, то данная сумма квадратов имеет одну степень свободы. К тому же выводу придем, если рассмотрим содержательную сторону расчетного значения признака у, то есть ŷx
. Величина ŷx
определяется по уравнению линейной регрессии: ŷx
=а+b*x. Параметр а можно определить как: a=y-b*x. Подставив выражение параметра а в линейную модель получим:ŷx
= y-b*x+b*x= y-b*(х-х).Отсюда видно, что при заданном наборе переменных у и х расчетное значение ŷx
является в линейной регрессии функцией только одного параметра – коэффициента регрессии. Соответственно и факторная сумма квадратов отклонений имеет число степеней свободы, равное 1.Существует равенство между числом степеней свободы общей, факторной и остаточной суммами квадратов. Число степеней свободы остаточной суммы квадратов при линейной регрессии составляет n-2. Число степеней свободы для общей суммы квадратов определяется числом единиц, и поскольку используется средняя вычисленная по данным выборки, то теряем одну степень свободы, то есть dfобщ
= n-1.Итак, имеется два равенства:∑(у-у)2
=∑( ŷx
–у)2
+∑(у- ŷx
)2
,n-1=1+(n-2).Разделив каждую сумму квадратов на соответствующее ей число степеней свободы, получим средний квадрат отклонений, или, что то же самое, дисперсию на одну степень свободы D.Dобщ
=∑(у-у)2
/(n-1);Dфакт
=∑( ŷx
–у)2
/1;Dост
=∑(у- ŷx
)2
/(n-1).Определение дисперсии на одну степень свободы приводит дисперсии к сравнимому виду. Сопоставляя факторную и остаточную дисперсии в расчете на одну степень свободы, получим величину F-отношения (F-критерия):F= Dфакт
/ Dост
, гдеF – критерий для проверки нулевой гипотезы Н0
: Dфакт
=Dост
.Если нулевая гипотеза справедлива, то факторная и остаточная дисперсии не отличаются друг от друга. Для Н0
необходимо опровержение, чтобы факторная дисперсия превышала остаточную в несколько раз.Английским статистиком Снедекором разработаны таблицы критических значений F-отношений при разных уровнях существенности нулевой гипотезы и различимом числе степеней свободы. Табличное значение F-критерия – это максимальная величина отношения дисперсий, которая может иметь место при случайном их расхождении для данного уровня вероятности наличия нулевой гипотезы. Вычисленное значение F-отношения признается достоверным (отличным от единицы), если оно больше табличного. В этом случае нулевая гипотеза об отсутствии связи признаков отклоняется и делается вывод о существенности этой связи: Fфакт
>Fтабл
. Н0
отклоняется.Если же величина окажется меньше табличной Fфакт
<Fтабл
, то вероятность нулевой гипотезы выше заданного уровня и она не может быть отклонена без серьезного риска сделать неправильный вывод о наличии связи. В этом случае уравнение регрессии считается статистически не значимым. Н0
не отклоняется. Оценку качества модели дает коэффициент детерминации. Коэффициент детерминации (R
2
) — это квадрат множественного коэффициента корреляции[14]
. Он показывает, какая доля дисперсии результативного признака объясняется влиянием независимых переменных.
Формула для вычисления коэффициента детерминации:
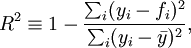 где где
yi
— выборочные данные, а fi
— соответствующие им значения модели.
Также это квадрат корреляции Пирсона между двумя переменными. Он выражает количество дисперсии, общей между двумя переменными.
Коэффициент принимает значения из интервала [0;1]. Чем ближе значение к 1 тем ближе модель к эмпирическим наблюдениям.
В случае парной линейной регрессионной модели коэффициент детерминации равен квадрату коэффициента корреляции, то есть R
2
= r
2
.
Иногда показателям тесноты связи можно дать качественную оценку (шкала Чеддока) (приложение 3).
Функциональная связь возникает при значении равном 1, а отсутствие связи — 0. При значениях показателей тесноты связи меньше 0,7 величина коэффициента детерминации всегда будет ниже 50 %. Это означает, что на долю вариации факторных признаков приходится меньшая часть по сравнению с остальными неучтенными в модели факторами, влияющими на изменение результативного показателя. Построенные при таких условиях регрессионные модели имеют низкое практическое значение.
Выводы
В настоящее время регрессионный анализ используется как в естественнонаучных исследованиях, так и в обществоведении.
Уравнение регрессии позволяет найти значение зависимой переменной, если величина независимой или независимых переменных известна.
Практически, речь идет о том, чтобы, анализируя множество точек на графике (т.е. множество статистических данных), найти линию, по возможности точно отражающую заключенную в этом множестве закономерность (тренд, тенденцию), линию регрессии.
Задачи регрессионного анализа лежат в сфере установления формы зависимости, определения функции регрессии, использования уравнения для оценки неизвестных значений зависимой переменной.
Решение задач основывается на анализе соответствующих параметров (статистических данных) в которых всегда неизбежно присутствуют отклонения, вызванные случайными ошибками. Поэтому существуют специальные методы оценки как уравнения регрессии в целом, так и отдельных ее параметров.
Глава 2. Практическое применение регрессионного анализа в эконометрике
Задача 1
По территории региона приводятся данные за 2007 (табл. 2.1).| Номер региона |
Среднедушевой прожиточный минимум в день одноготрудоспособного, руб., х |
Среднедневная заработная плата, руб., у |
| 1 |
78 |
133 |
| 2 |
82 |
148 |
| 3 |
87 |
134 |
| 4 |
79 |
154 |
| 5 |
89 |
162 |
| 6 |
106 |
195 |
| 7 |
67 |
139 |
| 8 |
88 |
158 |
| 9 |
73 |
152 |
| 10 |
87 |
162 |
| 11 |
76 |
159 |
| 12 |
115 |
173 |
Построить линейное уравнение парной регрессии у от х.Решение: для расчета параметров уравнения линейной регрессии строим расчетную таблицу (табл. 2.2)| х |
у |
Ху |
х2
|
у2
|
| 1 |
78 |
133 |
10374 |
6084 |
17689 |
| 2 |
82 |
148 |
12136 |
6724 |
21904 |
| 3 |
87 |
134 |
11658 |
7569 |
17956 |
| 4 |
79 |
154 |
12166 |
6241 |
23716 |
| 5 |
89 |
162 |
14418 |
7921 |
26244 |
| 6 |
106 |
195 |
20670 |
11236 |
38025 |
| 7 |
67 |
139 |
9313 |
4489 |
19321 |
| 8 |
88 |
158 |
13904 |
7744 |
24964 |
| 9 |
73 |
152 |
11096 |
5329 |
23104 |
| 10 |
87 |
162 |
14094 |
7569 |
26244 |
| 11 |
76 |
159 |
12084 |
5776 |
25281 |
| 12 |
115 |
173 |
19895 |
13225 |
29929 |
| Итого |
1027 |
1869 |
161808 |
89907 |
294377 |
| Среднее значение |
85,6 |
155,8 |
13484,0 |
7492,3 |
24531,4 |
| σ |
12,95 |
16,53 |
- |
- |
- |
| σ2
|
167,7 |
273,4 |
- |
- |
- |
b=xy-y*x/∑x2
-(x)2
=(13484-85,6*155,8)/(7492,3-85,62
)=151,8/164,94=0,92a=y-b*x=155,8-0,92*85,6=77,0Получено уравнение регрессии: у=77,0+0,92*х.С увеличением среднедушевого прожиточного минимума на 1 рубль среднедневная заработная плата возрастает в среднем на 0,92 рубля.Задача 2
По семи территориям Уральского района за 2008 г. Известны значения двух признаков (табл. 2.3).| Район |
Расходы на покупку продовольственных товаров в общих расходах, %, у |
Среднедневная заработная плата одного работающего, руб., х |
| Удмуртская республика |
68,8 |
45,1 |
| Свердловская область |
61,2 |
59,0 |
| Башкортостан |
59,9 |
57,2 |
| Челябинская область |
56,7 |
61,8 |
| Пермская область |
55,0 |
58,8 |
| Курганская область |
54,3 |
47,2 |
| Оренбургская область |
49,3 |
55,2 |
Определить:1. Для характеристики зависимости у от х рассчитать параметры следующих функций:А. линейной, ценить ее через F-критерий Фишера. Б. степеннойРешение:1.А. Для расчета параметров а и b линейной регрессии ŷx
=а+b*x решаем систему нормальных уравнений относительно а и b:n*a+b∑x=∑y,a∑x+b∑x2
=∑y*x.По исходным данным рассчитываем: ∑x, ∑y, ∑x2
, ∑y*x, ∑y2
. (Табл. 2.4)b= yx-y*x/ σx
2
=(3166,05-57,89*54,9)/(5,86)2
=-0,35;a=y-b*x=57,89+0,35*54,9=76,88.Уравнение регрессии: ŷ=76,8-0,35*х| У |
х |
у*х |
х2
|
у2
|
| 1 |
68,8 |
45,1 |
3102,88 |
2034,01 |
4733,44 |
| 2 |
61,2 |
59,0 |
3610,80 |
3481,00 |
3745,44 |
| 3 |
59,9 |
57,2 |
3426,28 |
3271,84 |
3588,01 |
| 4 |
56,7 |
61,8 |
3504,06 |
3819,24 |
3214,89 |
| 5 |
55,0 |
58,8 |
3234,00 |
3457,44 |
3025,00 |
| 6 |
54,3 |
47,2 |
2562,96 |
2227,84 |
2948,49 |
| 7 |
49,3 |
55,2 |
2721,36 |
3047,04 |
2430,49 |
| Итого |
405,2 |
384,3 |
22162,34 |
21338,41 |
23685,76 |
| Среднее значение |
57,89 |
54,90 |
3166,05 |
3048,34 |
3383,68 |
| σ |
5,74 |
5,89 |
- |
- |
- |
| σ2
|
32,92 |
34,34 |
- |
- |
- |
С увеличением среднедневной заработной платы на 1 рубль доля расходов на покупку продовольственных товаров снижается в среднем на 0,35%-ных пункта.Рассчитаем линейный коэффициент парной корреляции:rxy
=b*σx
/σy
=-0,35*5,86/5,74=-0,357.Связь умеренная, обратная.Определим коэффициент детерминации:r2
xy
=(-0,35)2
=0,127.Вариация результата на 12,7% объясняется вариацией фактора х.Рассчитаем F-критерий:Fфакт
= r2
xy
*(n-2)/(1- r2
xy
)=0,127*5/0,873=0,7.Поскольку 1≤F≤∞, следует рассмотреть F-1
.Полученное значение указывает на необходимость принять гипотезу Н0
о случайной природе выявленной зависимости и статистической незначимости параметров уравнения и показателя тесноты связи.1.Б. построению степенной модели ŷx
=а*xb
предшествует процедура линеаризации переменных. В примере линеаризация производится путем логарифмирования обеих частей уравнения:lgy=lga + b*lgx;Y = C + b*X, гдеY = lg y, X = lg x, С = lg a.Для расчетов построим таблицу (табл. 2.5)| х |
у |
Х |
У |
Х*У |
Х2
|
У2
|
| 1 |
68,8 |
45,1 |
1,6542 |
1,8376 |
3,0398 |
2,7364 |
3,3768 |
| 2 |
61,2 |
59,0 |
1,7709 |
1,7868 |
3,1642 |
3,1361 |
3,1927 |
| 3 |
59,9 |
57,2 |
1,7574 |
1,7774 |
3,1236 |
3,0885 |
3,1592 |
| 4 |
56,7 |
61,8 |
1,7910 |
1,7536 |
3,1407 |
3,2077 |
3,0751 |
| 5 |
55,0 |
58,8 |
1,7694 |
1,7404 |
3,0795 |
3,1308 |
3,0290 |
| 6 |
54,3 |
47,2 |
1,6739 |
1,7348 |
2,9039 |
2,8019 |
3,0095 |
| 7 |
49,3 |
55,2 |
1,7419 |
1,6928 |
2,9487 |
3,0342 |
2,8656 |
| Итого |
405,2 |
384,3 |
12,1587 |
12,3234 |
21,4003 |
21,1355 |
21,7078 |
| Среднее значение |
57,89 |
54,90 |
1,7370 |
1,7605 |
3,0572 |
3,0194 |
3,1011 |
| Σ |
5,74 |
5,89 |
0,0484 |
0,0425 |
- |
- |
- |
| σ2
|
32,92 |
34,34 |
0,0023 |
0,0018 |
- |
- |
- |
Рассчитаем С и b:b=(YX-Y*X)/σ2
X
=3,0572-1,7605*1,7370/0,04842
=-0,298;C=Y-b*X=1,7605+0,298*1,7370=2,278.Получим линейное уравнение: Ŷ=2,278-0,298*Х.Выполнив его потенцирование, получим:ŷ=102,278
*х-0,298
=189,7* х-0,298
.Выводы
В практических исследованиях возникает необходимость аппроксимировать (описать приблизительно) зависимость между переменными величинами у и х. Ее можно выразить аналитически с помощью формул и уравнений и графически в виде геометрического места точек в системе прямоугольных координат. Для выражения регрессии служат эмпирические и теоретические ряды, их графики — линии регрессии, а также корреляционные уравнения (уравнения регрессии) и коэффициент линейной регрессии.
Показатели регрессии выражают корреляционную связь двусторонне, учитывая изменение средней величины 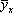 признака у при изменении значений xi
признака х, и, наоборот, показывают изменение средней величины признака у при изменении значений xi
признака х, и, наоборот, показывают изменение средней величины 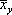 признака х по измененным значениям yi
признака у. признака х по измененным значениям yi
признака у.
Форма связи между показателями может быть разнообразной. И поэтому задача состоит в том, чтобы любую форму корреляционной связи выразить уравнением определенной функции (линейной, параболической и т.д.), что позволяет получать нужную информацию о корреляции между переменными величинами у и х, предвидеть возможные изменения признака у на основе известных изменений х, связанного с у корреляционно.
Заключение
В настоящее время регрессионный анализ используется как в естественнонаучных исследованиях, так и в обществоведении.
В практических исследованиях возникает необходимость аппроксимировать (описать приблизительно) зависимость между переменными величинами у и х. Ее можно выразить аналитически с помощью формул и уравнений и графически в виде геометрического места точек в системе прямоугольных координат. Для выражения регрессии служат эмпирические и теоретические ряды, их графики — линии регрессии, а также корреляционные уравнения (уравнения регрессии) и коэффициент линейной регрессии.
Показатели регрессии выражают корреляционную связь двусторонне, учитывая изменение средней величины признака у при изменении значений xi
признака х, и, наоборот, показывают изменение средней величины признака х по измененным значениям yi
признака у.
Форма связи между показателями может быть разнообразной. И поэтому задача состоит в том, чтобы любую форму корреляционной связи выразить уравнением определенной функции (линейной, параболической и т.д.), что позволяет получать нужную информацию о корреляции между переменными величинами у и х, предвидеть возможные изменения признака у на основе известных изменений х, связанного с у корреляционно.
Уравнение регрессии позволяет найти значение зависимой переменной, если величина независимой или независимых переменных известна.
Практически, речь идет о том, чтобы, анализируя множество точек на графике (т.е. множество статистических данных), найти линию, по возможности точно отражающую заключенную в этом множестве закономерность (тренд, тенденцию), линию регрессии.
Задачи регрессионного анализа лежат в сфере установления формы зависимости, определения функции регрессии, использования уравнения для оценки неизвестных значений зависимой переменной.
Решение задач основывается на анализе соответствующих параметров (статистических данных) в которых всегда неизбежно присутствуют отклонения, вызванные случайными ошибками. Поэтому существуют специальные методы оценки как уравнения регрессии в целом, так и отдельных ее параметров.
Построение линейной регрессии сводится к оценке ее параметров – a и b. Оценки параметров линейной регрессии могут быть найдены разными методами. Классический подход к оцениванию параметров линейной регрессии основан на методе наименьших квадратовВ прогнозных расчетах по уравнению регрессии путем подстановки в него соответствующего значения х определяется предсказываемое значение. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки ŷx
, то есть mŷ
x
, и соответственно интервальной оценкой прогнозного значения (у*
).После того как найдено уравнение линейной регрессии, проводится оценка значимости как уравнения в целом, так и отдельных его параметров. Оценка значимости уравнения регрессии в целом дается с помощью F-критерия Фишера. Библиографический список
1. Басовский Л.Е., Прогнозирование и планирование в условиях рынка, учебное пособие.- М.: ИНФРА-М, - 2002.-260с.2. Бережная Е.В., Бережной В.И., Математические методы моделирования экономических систем, учебное пособие, 2е изд.,- М.: Финансы и статистка, - 2005, 432с.3. Гладилин А.В., Эконометрика: учебное пособие. – М.:КНОРУС, 2006.–232с.4. Домбровский В.В., Эконометрика: учебник.- М.: Новый учебник, 2004.-342с.5. Елисеева И.И., Эконометрика: учебник для вузов.- М.: Финансы и статистика, 2002.-344с.6. Елисеева И.И., Эконометрика: учебник, 2е изд.- М.: Финансы и статистика, 2005.-576с.7. Елисеева И.И., Практикум по эконометрике: учебное пособие.- М.: Финансы и статистика, 2002.-192с.8. Зандер Е.В., Эконометрика: учебно-методический комплекс, - Красноярск: РИО КрасГУ, 2003.- 36с.9. Колемаев В.А. Эконометрика: учебник, - М.: ИНФРА-М, 2006. – 160с.10. Интернет: Википедия Приложение 1
| Вид функции, у |
Первая производная, y`x
|
Коэффициент эластичности,Э= y`x
*(х/у) |
| ЛинейнаяУ=а+b*x+ε |
b |
Э=(b*x)/(a+b*x) |
| Парабола второго порядкаy=a+b*x+c*x2
+ε |
B+2*c*x |
Э=((b+2*c*x)*x)/(a+b*x+c*x2
) |
| Гиперболаy=a+b/x+ε |
-b/x2
|
Э=(-b)/(a*x+b) |
| Показательнаяy=a*bx
*ε |
ln b*a*bx
|
Э=x*ln b |
| Степеннаяy=a*xb
*ε |
A*b*xb-1
|
Э=b |
| Полулогарифмическаяy=a+b*lnx+ε |
b/x |
Э=b/(a+b*ln x) |
| Логистическаяy=a/(1+b*e-cx
+ε
) |
(a*b*c*e-cx
)/(1+b*e-cx
)2
|
Э=(c*x)/((1/b)*ecx
+1) |
| Обратнаяy=1/(a+b*x+ε) |
-b/((a+b*x)2
) |
Э=(-b*x)/(a+b*x) |
Приложение 2
| ∑(у-у)2
|
= |
∑(ŷх
-у)2
|
+ |
∑(у- ŷх
)2
|
| Общая сумма квадратов отклонений |
Сумма квадратов отклонений, объясненная регрессией |
Остаточная сумма квадратов отклонений |
Приложение 3
| Количественная мера тесноты связи |
Качественная характеристика силы связи |
| 0,1 - 0,3 |
Слабая |
| 0,3 - 0,5 |
Умеренная |
| 0,5 - 0,7 |
Заметная |
| 0,7 - 0,9 |
Высокая |
| 0,9 - 0,99 |
Весьма высокая |
[1]
Интернет. Экономико-математический словарь.
[2]
Е.В. Зандер, Эконометрика: Учебно-методический комплекс., Красноярск: Рио КрасГУ, 2003, 15с.
[3]
Е.В. Бережная, Математические методы моделирования экономических систем: учебное пособие, 2е изд., М.: Финансы и статистика, 2005, 148с
[4]
И.И. Елисеева, Эконометрика: учебник для вузов., М.: Финансы и статистика, 2002 – 36с.
[5]
И.И. Елисеева, Эконометрика: учебник для вузов., 2-е изд., М.: Финансы и статистика, 2005 – 81с
[6]
В.А. Колемаев, Эконометрика: учебник. – М.: ИНФРА-М, 2006, 46с
[7]
И.И. Елисеева, Эконометрика: учебник для вузов., М.: Финансы и статистика, 2002 – 42с.
[8]
И.И. Елисеева, Эконометрика: учебник для вузов., М.: Финансы и статистика, 2002 – 62с
[9]
М. Езекил: Методы анализа корреляций и регрессий., М.:Статистика, 1966.-393с
[10]
Н.Дрейнер, Г.Смит: Прикладной регрессионный анализ/Пер. с англ., М.:Статистика , 1973, 140с
[11]
А.В. Гладилин, Эконометрика: учебное пособие.- М.:КНОРУС, 2006.- 68
[12]
В.В. Дмитровский: Эконометрика: учебник, М.: Новый учебник, 2004, 27с.
[13]
А.В. Гладилин, Эконометрика: учебное пособие., М.:КНОРУС, 2006, 60с
[14]
Интернет: Википедия
|